I have a document with sources, authors, quotes, and tags. Each quote is tagged, usually with multiple tags, and all quotes list the author and source (stored as an ID numbers) as attributes.
As I explore the relationship between these things, I end up with questions like “Which quotes mention the phrase X?” Or “Which authors are tagged Y?” and I want to create a list of authors and compare them to other subsets of authors.
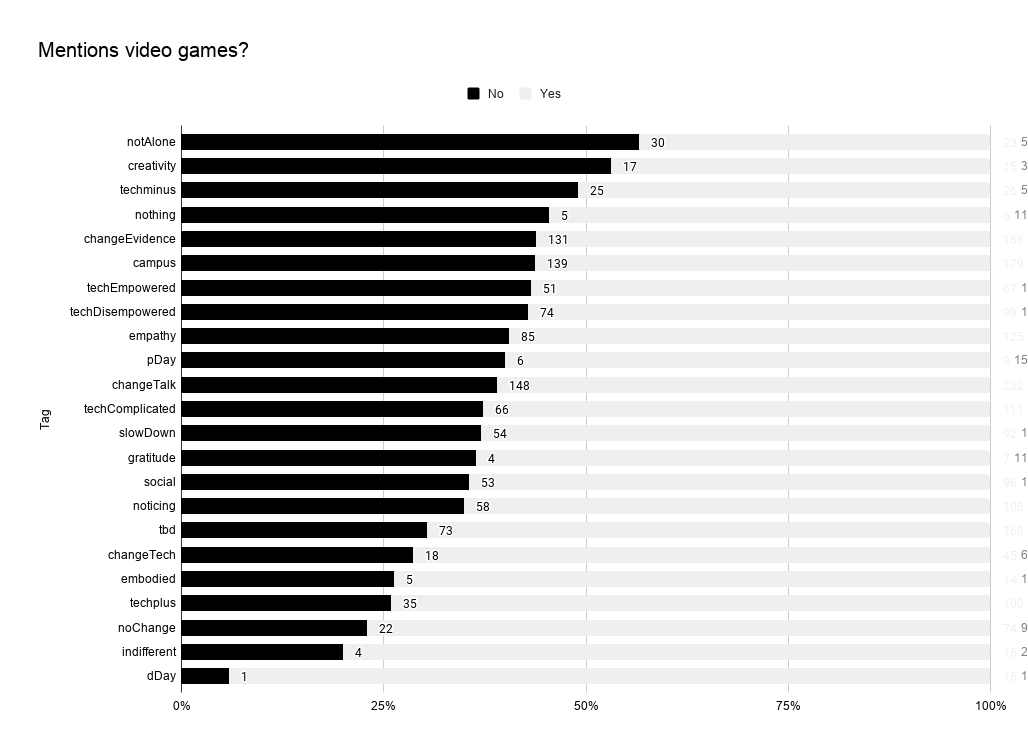
For example, today I wanted to look at “Which quotes mention the phrase video games?” and compare the tags for those quotes to the tags of those quotes that do not mention video games so that I could do some quick and dirty visualizations as a method of exploration, e.g.
To get the data for this graph, I created an agent that searched for the phrase “video games” and I used action code to print a list of the participants with help from Ordering $MySet. Then, I created two new agents with massive, ugly, endless OR conditions that I am embarrassed to share here but am doing so for the good of the order.
In my case, it was to stop multiple | $Prototype==. Mark B suggested I collect all the ‘or’ commands into the value of a single set attribute (I chose to put it in the note “Config”, but that’s optional of course) and reference it from there.
e.g.
In the Config note:
$MyPrototypeSet = "pThis;pThat;pTheOther"
In the Query
$MyPrototypeSet("Config").contains($Prototype)
So, what about putting all the relevant PIDs for each search into an attribute somewhere then having the agent query as
Obviously, you could have different set attributes for different searches, or just amend the same one each time as required, and perhaps there’s a way of automating what’s in each set attribute (with collect()?).
I take it the big list of $PIDs is those participants that had the term “video games”—or not. So these could be defined by a boolean. As you say you repeat the process, rather than use a name like $HasVideoGames, we’ll use $HasTopic. Thus, when we come to search for a different terms, we can re-use the attribute without having a confusing name - or, make a boolean per topic (unless there are many 10s of them).
Now for those notes with the topic of interest we set $HasTopic to true. Now are queries are:
$Prototype=="Data Extract"&$HasTopic==true
for notes with the search topic and for the others:
$Prototype=="Data Extract"&$HasTopic==false
Now you are down to two query terms. It isn’t less work than the above but trades the regex .contains() for a simple boolean call. In truth, here’s probably no difference at the size of data set you are using - so pick a method you find easiest to understand.
Don’t overlook the re-use part as you say you want to do this a lot. Ideally then, you want to be able to re-use the construction pipeline for “video games”, “some other term”, etc. without building out lots more agents, attributes, etc. The only limitation of that approach is you can’t show the data for two different search terms at the same time (though you could use two copies of the same doc (different filenames needed) open together). Anyway, food for thought.