Dear Eastgate,
I am interested in discussing your propositions further about hyperbolic view,
let us branch out “hyperbolic view” as topical incidents.
Does the proposal meet with your approval?
thx and regards, WAKAMATSU kunimitsu
fwiw, my experiments w/ DTPO show that with markdown documents, links can inform the AI because the link UUID is a unique string. So if you want to go down that route, give markdown documents a try.
That said, my own experience has been that the serendipity suggested by DT’s AI is simply not as useful as the serendipity that results from following my own links and organization w/ TB notes. DT works on a fairly naive principle – documents are related to each other because they have words in common – whereas TB notes are related because they have a meaningful relationship to me.
The TB serendipity comes when I view a note and follow its link to another note I wasn’t thinking of, or I link one cluster of notes to another cluster.
I guess you can have both when linking within DT… I just personally find TB’s visual aspect more useful than DT’s formless presentation (even more so now with hyperbolic view).
Eheu, the tragedy of AI. I’m surprised at our ability, more so amongst tech folk, to assume 'computer knows best. In my youth, when colour TV arrived the saying was “It must be true, it’s in colour”. Algorithms may be great for spotting patterns (especially if the AI is trained, ironically by humans), but I’m mystified at how little tech vales human insight.
A reason Tinderbox lives close at hand for me is that it neither privileges brute force pattern matching nor does it feed our human instinct for order**. Rather, it is supportive of incremental formalism, which is an academic way of saying don’t enforce structure you don’t yet understand and which may be a false trail. In doing so, Tinderbox supports human intellect in a nice un-database-y way. Long may it do so, and help support human insight in the face of the AI onslaught.
** If you’ve ever felt it necessary to apologies that your Tinderbox maps are messy, this is that effect at work. Resist it—knowledge discovery is not graphic design.
Thank you to both of you, @pat and @mwra, for sharing your insights and experience.
From your words — but please correct me if I misunderstood them — it seems to me that the three of us — and probably, from the threads in this forum, many, if not most, of TB’s users — are interested, for perhaps different reasons, in how patterns of knowledge seem to emerge from our interaction with a set of notes.
That’s why I always find very interesting to learn how different people interact with their notes. Following existing first-order links (e.g., note 1 to note 2) is straightforward. And the changes to Roadmap view and the Hyperbolic view in TB8 now facilitate following higher-order links (e.g., note 1 to note 3 through note 2). But what I find even more interesting is the process of creation of new links; for example, how do you, @pat, decide to link precisely that cluster of notes to that other cluster of notes? And how do you, @mwra, implement “incremental formalization” in your notes? And of course, how do other users interact with their notes?
I realize describing this in the necessary detail may be too time consuming; moreover, for various reasons, you may not want to share this information. Nothing can be done if the latter is the case, and I would of course respect your choice; if, on the other hand, time is the limiting factor, as it often is, may I make to @eastgate the friendly suggestion that it may be time to bring the TB community together for a meetup, a workshop or a conference where we can meet and discuss our common interests?
Thank you for your consideration.
Best regards,
Enrico
My main Tinderbox-based ‘work’ at present is mixed-methods research as part of my PhD. Pat of that is essentially a qualitative discovery process of the source material—in my case mainly hypertext aspect of Wikipedia. The scale of the work, with thousands rather than tens of notes, precludes a map view based approach, if only as one would need a massive screen to lay everything out. Thus the visual affordances of visible links are lessened.
However, Tinderbox’s flexible method os adding attributes as/when needed and action code allowing me to easily back-fill values new attributes in pre-existing notes makes it easy to add structure as it emerges. If doing exploratory work, whilst you may have an overarching hypothesis, crystallising that too early in the process is self-defeating. I’ve learned from experience that it can be useful to capture emerging strands as list values, not necessarily in a single attribute, and as clarity emerges to split these out into discrete new attributes. This is both for more detailed analysis and structure, but also for the later phase of reporting and quantifying of data. Capturing single strands within multi-value (i.e. list or set type attribute) data into single value attributes can make later querying or export of the data easier.
Also, I try to leverage prototypes. How does this help?
- Querying. For example, even if you do no customisation of the prototype, have all your source notes use the ame prototype makes a query of all your sources as simple as:
$Prototype=="some_prototype". - KAs. Prototypes make it easy to set, and alter, the KA set-up across a large set of notes. Indeed, I sometimes set up prototypes for the same intended set of notes but having different KAs for each. This makes it easy to swap our KAs appropriate to the task at hand rather than try and show 10s of KAs at once (as they will overflow the visible KA space).
- Actions (especially edicts). When doing things like getting individual notes to find other notes with a particular value, whether to create a link or capture as an attribute value, you will often find it necessary to run per-note
find()queries that have a regex-based method such as.contains(). Running these as rules isn’t needed as generally you only need one pass to effect the outcome, but each note’s run of the code is quite CPU intensive. Rule or edict choice regardless, a prototype makes it easy to insert, run and then remove the code. You could use an agent, with 000s of notes making an alias of each (i.e. 000s more objects in the document) can also clog things up.
In summary, even if I don’t use Map view so much due to pragmatic constraints, I think in those terms. Even if I don’t always create an actual link between objects I often store metadata (i.e. attribute values) which allows me to work as if the link did exists. My own journey with using Tinderbox has been to internalise the map process allowing me to use it on a larger canvas than my screen space would allow.
Dear @mwra,
Thank you very much for taking the time to write such a thoughtful and exhaustive reply: I found it most inspiring, especially because it seems to refer to the application of an approach similar to one that has been on my mind lately; here it is.
I have been considering using keywords for my notes (added through $Tags). This would allow me to find all the notes labeled with a given keyword and evaluate whether those notes should be linked to one another, either directly or through other notes.
The problem is that I of course don’t know precisely which keywords are or will be relevant for my growing set of notes. For example, I may think that the keyboard “cell polarity” is and will be sufficient, but over time I may need to differentiate between “cell polarity establishment” and “cell polarity maintenance”. In this case, I know I could find all those notes labeled with the keyword “cell polarity”, but once I had identified for which of those notes I would like to replace the keyword “cell polarity” with the keyword “cell polarity establishment”, would I be able to do that replacement automatically in TB, without doing that one note at a time? I am not asking precisely how to do that at this stage, but only whether you thought one could automate that replacement in TB. If that were the case, I would consider it worth it the investment of time required to apply keywords to all the notes I already have and the ones I will create without worrying about finding the “perfect keyword” from the very beginning.
I suspect that should be possible with TB, but sometimes my suspicions are wrong; for example, I thought that simply by adding $Tags as a KA to a Prototype, all the notes that had been created with that Prototype would automatically inherit $Tags as a KA, but that did not seem to be the case…
Thank you for your consideration.
Best regards,
Enrico
- Yes, there are several good ways to automate this kind of tag conversion. For example, an agent could find all the notes that have the tag CellPolarity
Query: $Tags.contains("CellPolarity")
and add a new tag
Action: $Tags=$Tags+"CellPolarityEstablishment";
or remove the old tag
Action: $Tags=$Tags-"CellPolarity"; $Tags=$Tags +"CellPolarityEstablishment";
- You question about key attributes is quite straightforward. If a note has its own value of an attribute, that value takes precedence over any inherited value. If you think about it, that’s essential: otherwise, notes would inherit all their values, and you couldn’t tell them apart! So, you simple need to remove the value assigned to existing notes; if you do, the inherited values will be used.
I don’t… it’s more like, let’s say you like one note to another. Well that other note is linked to another note, that links to another, that links to another. So you have two separate clusters of notes, but when you link one from one cluster to one from the other, the two clusters become joined to make a bigger cluster / network of notes. Does that make sense?
Thank you very much, @eastgate, not only for the helpful clarification, but for already explaining in detail how I could add or replace keywords (i.e. $Tags): I really appreciate that!
As to:
You question about key attributes is quite straightforward. If a note has its own value of an attribute, that value takes precedence over any inherited value. If you think about it, that’s essential: otherwise, notes would inherit all their values, and you couldn’t tell them apart! So, you simple need to remove the value assigned to existing notes; if you do, the inherited values will be used.
However, that’s not exactly what happens to me; I apologize for the confusion and please let me clarify. When I add $Tags as a KA to a Prototype—for example, to the Prototype Quotes in the screenshot below—even if I do not add any keywords/tags in the $Tags attribute field of the Prototype:
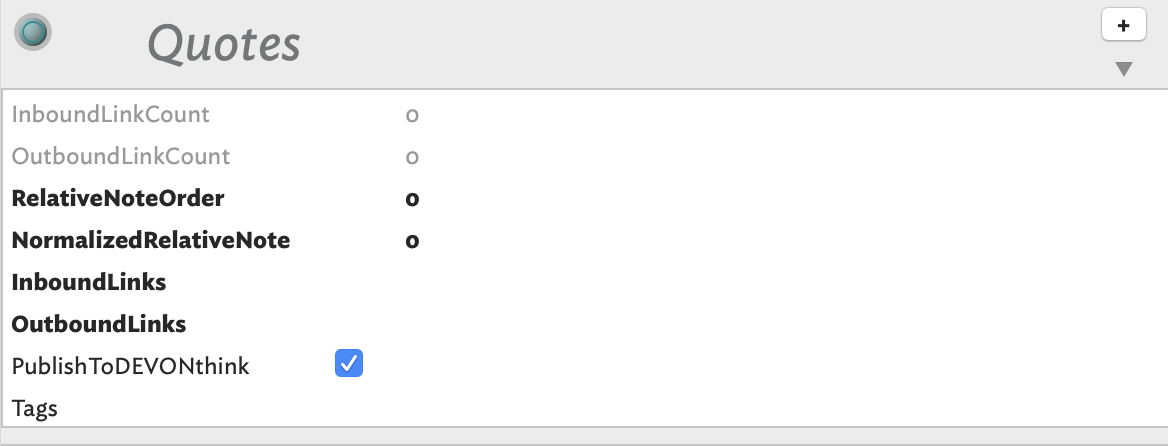
The notes that had been created with the Quotes Prototype before I added the $Tags KA to the Quotes Prototype fail to inherit such KA; for example, the note q20190105163532:
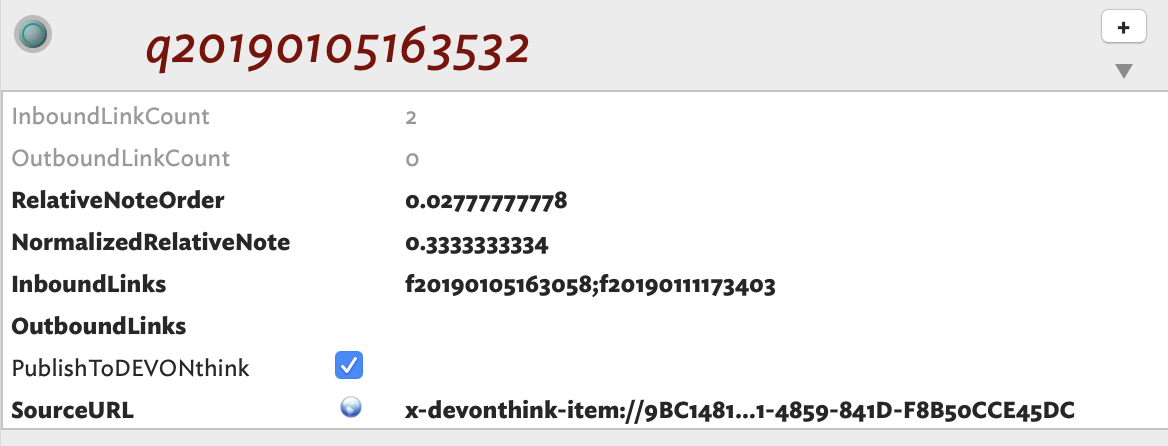
However, notes created after the addition of $Tags as a KA to the Prototype Quotes inherit such KA; for example, the note untitled:

I hope I clarified what I meant and would be grateful for any help/suggestions you may have.
Thank you for your consideration.
Best regards,
Enrico
Thank you very much, @pat, for the helpful clarification: it makes perfect sense, and I now understand exactly what you originally meant!
Best regards,
Enrico
It appears that you added attribute sourceURL to the KA for this note. Therefore the note will not inherit the KA settings from the prototype because that not has local settings for the KeyAttibutes. You can use a Quickstamp to make the note inherit from the prototype instead of using the local settings.
Thank you very much, @PaulWalters, for identifying the problem: if I am not mistaken, that $SourceURL attribute is generated by @pat’s Publish-to-DEVONthink Stamp, which I use to export my notes to DTPO.
Thank you very much also for suggesting a solution: I have never used a Quickstamp, so your suggestion also offers me the opportunity to learn that too!
Best regards,
Enrico
@enricoscarpella I suggest you take a look at my tutorial on inheritance in Tinderbox which is the underlying issue to your problem above.
Thank you very much, @mwra, for the helpful suggestion and for the amazing resource, which I will read with the greatest interest!
Through that page, I was also able to find other very helpful tutorials here; are they public or would I be infringing copyrights by reading them? I know your name is acknowledged at the beginning of that page, but I am not sure if you really posted them or somebody else did without your consent… (I recently discovered a TB-related case of copyright infringement and reported it to Eastgate, so I am circumspect).
Thank you again very much for your continuous support!
Best regards,
Enrico
@enricoscarpella, they’re all free and unencumbered for re-use. Inevitably a few features may change - e.g. descriptions of each Inspector feature - and I don’t necessarily have time to update these a quickly as aTbRef. Stuff with graphics always takes a bit longer (normally because you need to ‘make’ the right picture to record. Indeed, aTbRef8 is pretty much done, bar the graphics.
Sadly, the Clarify app has been withdrawn and remains a 32-bit app (so not supported on macOS 10.5) as the makers have concentrated on a $$$ enterprise version of the app. I’m not aware of an app that does annotated screenshot based tutorials with as much ease/speed.
Thank you very much fo the clarification, @mwra.
I don’t necessarily have time to update these a quickly as aTbRef.
Frankly, I don’t even know where you find the time to work on your PhD thesis: it seems that we users in this forum are the main obstacle between you and your degree… I cannot speak for anyone else — even though I am quite certain the sentiment is widespread — but your generosity with your time speaks volumes about you, so thank you very very much!
Best regards,
Enrico
1 Like
Dear @PaulWalters,
I found the clearest explanation of what I needed to do in this posting of yours. I hope you don’t mind if I link it here: I thought it could be helpful to other users too. Thank you again for pointing me in the right direction.
Best regards,
Enrico
1 Like
This is possible, if you specify a section within the Text where you would like the attribute values to go. I agree with @mwra’s general assessment about the best way to accomplish what you’re aiming for. But independently of that, this is a useful trick for generating reports in a note’s text.
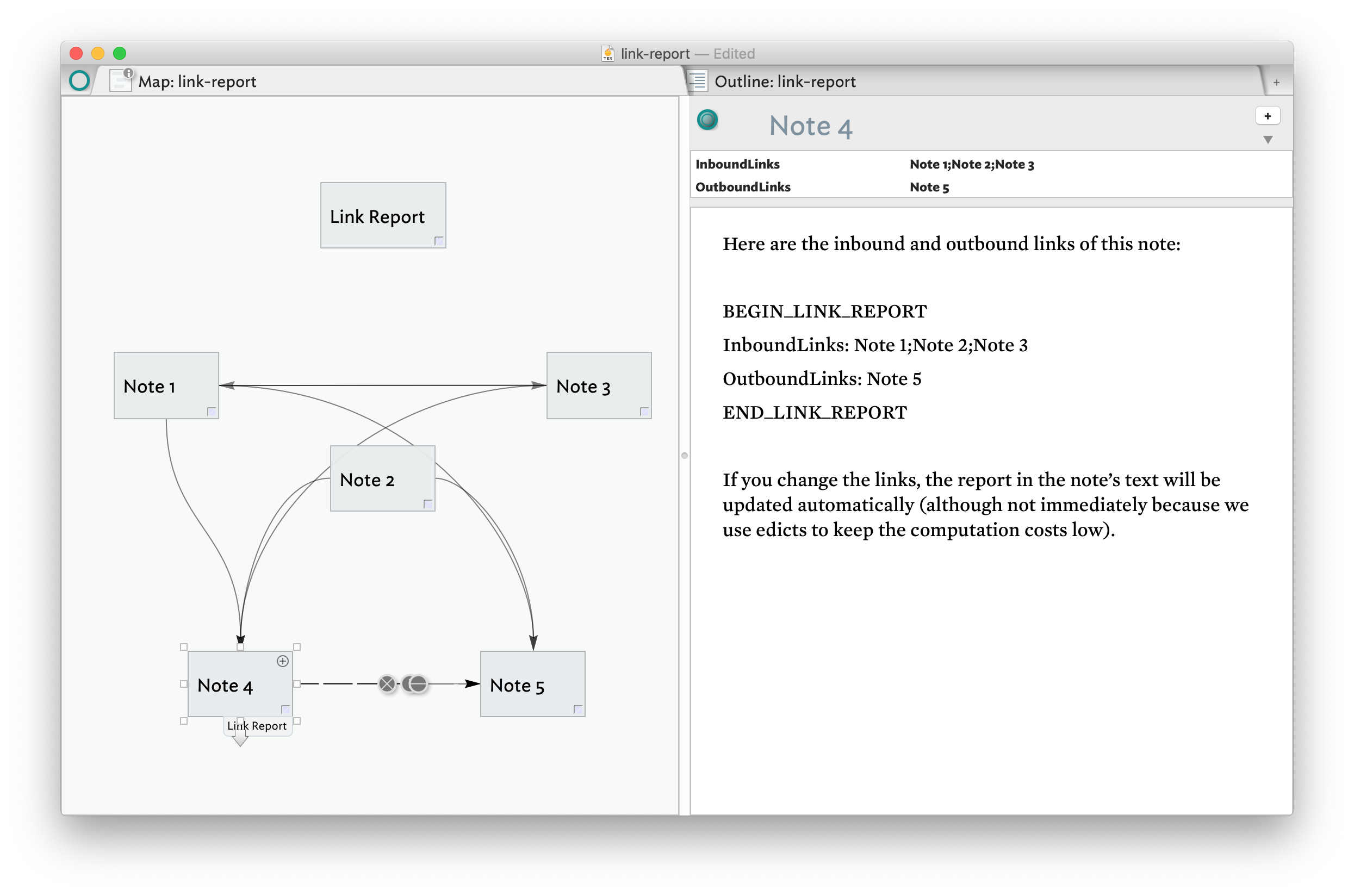
The attached document contains a prototype with the following Edict:
$InboundLinks=links.inbound..$Name;
$OutboundLinks=links.outbound..$Name;
if ($Text.contains("(.*BEGIN_LINK_REPORT\n).*(\nEND_LINK_REPORT.*)")) {
$Text=$1 +
"InboundLinks: " + $InboundLinks +
"\nOutboundLinks: " + $OutboundLinks +
$2;
}
When the edict is run, it updates InboundLinks and OutboundLinks. It then checks to see if the note’s text contains a section that looks like this:
BEGIN_LINK_REPORT
...
[any text can go here]
...
END_LINK_REPORT
If it does, it inserts a report of the incoming and outgoing links between BEGIN_LINK_REPORT and END_LINK_REPORT. The other text in the note is unaffected.
Changes to the links are automatically propagated into the text of the note.
Here’s what it looks like in action:
link-report.tbx (94.2 KB)
That’s fantastic, @galen! Thank you very much for generously taking the time to help me out describing in such detail what the Edict does and for attaching the sample .tbx file (already downloaded!).
I am always pleasantly surprised by how powerful TB is: it seems it can always do what I need, even though I often don’t know how. And that’s where the second pleasant surprise comes in: how selfless the users in this forum are. So thank you very much again!
Best regards,
Enrico
1 Like
I use Tinderbox and TheBrain, and they meet very different requirements because they are designed to solve different problems. The main difference for me is that TheBrain is designed to scale up to hundreds of thousands or millions of notes while remaining responsive, and Tinderbox is designed to give rich, varied, and customizable visual presentations of your data (as well as helping to automatically categorize and/or generate data).
Tinderbox can’t scale up to a large graph like TheBrain does (again, by “large” I mean > 10^5 here). For example, in hyperbolic view, Tinderbox displays all nodes that are reachable from the note in focus. This means in a graph of only a few hundred notes, the hyperbolic view in Tinderbox slows to a crawl. TheBrain only shows notes that are at most two jumps away from the note in focus. This keeps the document responsive, but at the cost of only ever being able to see a restricted subgraph.
TheBrain also doesn’t support fine scrolling adjustments of the graph view like Tinderbox does. With TheBrain, the focus note sits in the middle of the screen, period. If you want to look at a different part of the graph, you have to move the focus to another note. This means that exploring the graph in TheBrain necessarily means you lose some coherence of the view, because the nodes are constantly being rearranged on the screen as you change focus to explore the graph.
I use TheBrain as a long-term reference store. I have one brain database, and anything that catches my interest goes in there. TheBrain’s design (including its restricted view of the graph, oddly enough) allows you to keep adding stuff to it without slowing down performance and without it feeling like the database is becoming a huge unmanageable hairball. But it does this by heavily restricting the presentation of the data to a few (quite well designed) views. TheBrain also offers minimal automation to reclassify notes etc., so to my mind it’s best suited for long-term data store that doesn’t change all that much (aside from new manually created links). I see people trying to use TheBrain as a daily planner/GTD system and I am totally baffled.
I use Tinderbox as a dynamic planning, thinking, and drafting tool. Tinderbox is like a toolbox for creating a little specialized app that’s perfectly suited to the task at hand. It’s far more flexible and powerful than TheBrain, but at the cost of scalability and responsiveness. In practice I use TBX as a document drafting tool and as a mini database tool for jobs that are too complex for a spreadsheet. I use a bullet journal for planning these days, but in my view Tinderbox is the best digital GTD tool there is (if you are willing and able to pay the opportunity cost of learning to use it well).