I’m still importing a bunch of data into TB, which originated in the antique MS-DOS program Lotus Agenda and has made its journey through a spreadsheet (as recounted in this thread).
Challenge of the moment: the BBEdit conversion routine that got the Agenda info ready for spreadsheet import has left a lot of date info in this format:
03011998 21:37
03111998 08:02
03151998 14:38
Just as reference, those are all dates in 1998: March 1, March 11, March 15.
When I copy-paste this into TB, with all the TB attribute fields set up to match the column headings in the spreadsheet, TB does not recognize it as a date field. (I have specified this field, called $Date, as a date-type field.) It renders the date as either “Never” or the current date.
You are about to enter the wonderful world of regular expressions! Congratulations (I suppose)!
You’ll notice that while Tinderbox does not recognize “03011998 21:37” as a date string, it does recognize “03/01/1998 21:37” as a date string. So we just need to construct a new string from the old string that has slashes in the right places. Here is some action code that does this, assuming that $MyString contains a string in the no-slash format:
The argument to contains is a regular-expression string that describes a pattern that $MyString must conform to for contains to evaluate to true. Here ^ matches the start of a string, and \d matches a decimal digit. .* matches any string. The parentheses are groupings that define the contents of $1, $2, and $3 (known as “back-references”) on the next line.
This action as a whole basically says if $MyString starts with two digits, followed by two digits, followed by anything, then set $MyDate to the string consisting of the first two digits, followed by a slash, followed by the next two digits, followed by a slash, followed by whatever came after the digits.
I would import the data, putting the date-strings in $MyString, and then run this action with a stamp.
Good suggestion Galen. FWIW, @JFallows, for future reference, the regex parsing that @galen laid out can be included in the BBEdit TextFactory. I assume you are well beyond that stage, so I won’t update the TF.
Thank you to @galen and @PaulWalters for the clear and helpful guidance.
I of course have heard of regex but not ever used it myself in a complex / conditional way. And I had been vaguely aware of the back-reference possibility – $1, $2 and so on – but again had not actually put them to use. So this will help me convert this data, and will introduce me to another set of tools for future use.
This is similar to the MID text function you may have seen in spreadsheets: start at a specified character in a string and include a specified number of characters after that. Unlike spreadsheets, substr starts from character 0 rather than character 1. So:
substr($MyString,0,2) means start at the first character and include two characters, equivalent to =MID(ref to string,1,2)
substr($MyString,2,2) means start at the third character and include two characters
substr($MyString,4,10) means start at the fifth character and include 10 characters after that. Tinderbox doesn’t seem to mind if you use a value larger than 10 here to make sure you capture up to the end of the string.Preformatted text , though there are more sophisticated ways to do that using $String.size as suggested in the examples in Mark A’s aTbRef.
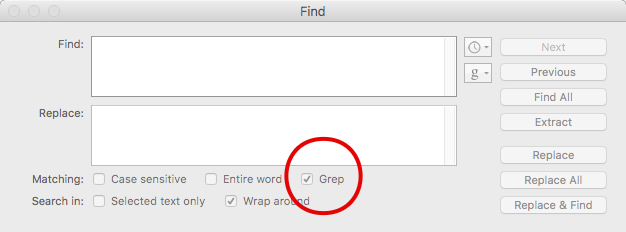
Also, if you use Text Wrangler or BBEdit, use this tick box to enable regular expressions in find & replace operations:
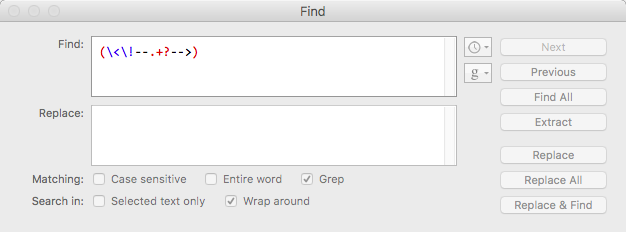
When grep is enabled, characters with special meaning in regex such as . are shown in colour:
In the above note that only the hyphen and more-than characters are in black. All others have a special meaning in grep mode. In grep mode a backslash is used to escape characters so they are intepreted as a literal character and not as their special regex meaning.
Thanks also to @sumnerg and @mwra for the additional explanation and tips. Helps me solve this specific problem and, by extension, deal with others in the future as well.
I have adapted @galen’s action in order to parse the body text of my annotations to fill $StartDate. They are imported from DevonThink and dates appear as “<2017-04-25”.
The code below works as a stamp, but not in the $OnAdd field of the “Imported From DEVONthink” prototype. In order to automate the procedure, where should I place it and should it be modified?
Using this on an normal container $OnAdd is works (as does your code). It may be that the watched group process doesn’t execute the container’s $onAdd. Why, I’m not sure but this new feature is still at an early stage.
Now, I can’t get this expression to work. I would like it to parse the beginning of $Text and if it finds a page number, fill $Page with it; otherwise, do nothing.
By the moderator: a polite request to not thread-thread. Althuogh involving regex, this is not a question about date parsing (the topic title), so in future would be better in a thread of it’s own. Splitting threads isn’t particularly easy in Discourse so I’ll leave this here for now Thanks!
There seem to be a few problems here:
You’re passing the match \A\d{1,4}\s to $Page when I think you mean to pass just \d{1,4}.
Are you targeting the built-in $Pages [sic] or a user attribute $Page?
to do the sort of match with back-references that you desire the regex needs to expan to the whole of text not just a match within a partial match.
It does work, and I have modified it to allow for referencing in between two pages (pages 1-8, for example).
I have created a user attribute $Page because $Pages is used by Bookends for journal articles and edited books.