The new AppleScript support has made it practical to import several long, meandering chains of emails into Tinderbox where I’m trying to organize and analyze them.
I’ve run into a snag trying to “chop off” the extraneous bits and keep just the text of each message, not the text of messages to which each message replies.
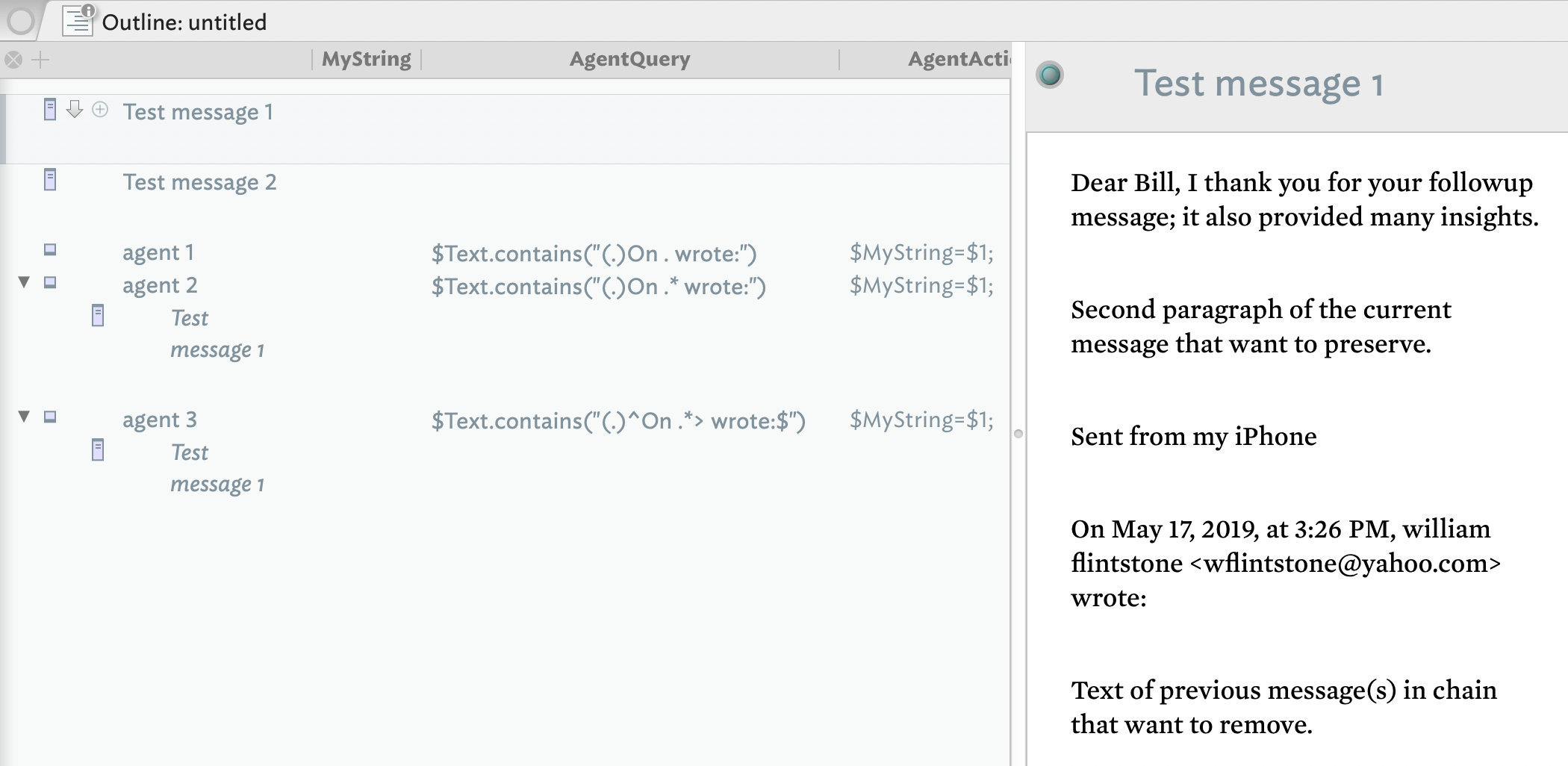
For example the text imports as something like this:
Dear Bill, I thank you for your message; it provided many insights.
Second paragraph of the current message that want to preserve.
Sent from my iPhone
On May 17, 2019, at 3:26 PM, william flintstone <wflintstone@yahoo.com> wrote:
Text of previous message(s) in chain that want to remove.
I want to keep the part up to the On … wrote:
I thought this might do it:
$Text=$Text.split("^On .*> wrote:$").at(0)
That works in some cases but in this case chops off at the semicolon after the word message. I have a tough time with regex but assume this may have something to do multi-line mode or some such thing.
[Admin post-edit to add code formatting as regex characters in code sample getting misinterpreted as italicisation markup]
The problem here is the special meaning of semicolons in sets and lists. As you know, split returns a list. In this case, the result is a list with two items:
Dear Bill, I thank you for your message; it provided many insights.
Second paragraph of the current message that want to preserve.
Sent from my iPhone
Text of previous message(s) in chain that want to remove.;
But the first item has a semicolon, and that confuses the list processor.
Since you’re looking for “everything up to the delimiter”, which not use an agent?
I’m wondering the problem is. Is it because the . doesn’t apply when there are new lines?
Meanwhile, the following seems to work in a stamp applied to test notes: replace any ; with a dummy character, split the string, take the first bit, and replace any dummy with ; . Somewhat ugly, but I think it’s working.
I was puzzled why I got (very) strange results when I first tried a pipe character instead of << but think I have found out the hard way that any characters that have special meaning in regex can’t be used as the search pattern in String.replace().
Anyway, it would be great to know if there is a simpler solution with capture in regex.
Generally if doing this (or assisting others) I first process the $Text to replace any semi-colon with a string such as ‘####’. The string wants to be (a) something unlikely to occur is the actual text and (b) does not use regex special characters: i.e. backslash, caret, dollar sign, the full stop, vertical bar (‘pipe’), question mark, asterisk, plus sign, opening or closing parenthesis, opening square bracket and the opening curly brace.
As you relate, you took this path but initially failed to allow for regex special characters.
I don’t think there is a simpler form. Tinderbox lists (Set, List types) are strings containing semicolon-delimited values. There is no method to escape a literal semi-colon in a string - as opposed to a value delimiter. I can give $MyList a value ‘ant;bee;cow’ which is treated as two list items as the first semi-colon is treated as a literal character and not a value delimiter. But If I set $MyString to the value of $MyList , the resulting string is ‘ant;bee;cow’ - now with a literal backslash, at least from the user’s perspective.
Unless/until the String.split() operator deals with literal semi-colons internationally (i.e. escaping them within the function then unescaping the output) I think it will remain necessary to escape in-$Text semi-colons deliberately before trying to split out paragraphs.
Thanks! Now I understand better why I failed when I tried both || and ** before blindly stumbling on <<.
By a possibly simpler approach I meant not the String.split() approach but the String.contains() with the regex capture group (if that is the correct term) in what Mark B first suggested above. It seems as if that should work but I can’t get it to capture anything.
In other words, display the (all-important, I now realize) * is suppressed by the forum software, at least on my machine. And that, of course, is why I could not get it to work.
This now works here in a stamp (after removing extraneous spaces from the cut-and-paste).
$Text.contains("(.*)On .*> wrote:$");$Text=$1;
This seems cleaner and simpler than the replace, split and replace approach.
The code is working in the last post because you’ve applied appropriate code mark-up. Otherwise text between single asterisks (i.e. *text between single asterisks*) is interpreted as markdown syntax for italic text. That is standard behaviour in all Discourse fora where markdown is the method used for marking up styled text in posts.
If quoting code in your post, always use the mark-up for code.
I was referring to Mark B’s post above. By luck my own posts quoted the code I was trying.
It appears that lack of quoting was the culprit that led me astray because I couldn’t see the * and didn’t know enough about regex to put it in. One part of my brain no doubt fell victim to argumentum ad verecundiam; if the expert shows an approach without * then who am I to differ? I clearly must be doing something else wrong.
On closer inspection of the post I see that it does seem to have an italicized closing parenthesis and the word on, hard for me to spot. With your explanation of the forum software I now know that should have been a tipoff to something being off.
My followup queries on the simpler regex approach didn’t get a response. So I continued to flounder. But I’m happy finally to have sorted it out.
Ah, I thought that might be the case, but thought to make the general point about markdown anyway. It is confusing as there as several ways to do most style mark-up. For instance, either a pair of underscores or a pair of asterisks produce italics (underscores is the variant used by the button in the message input box).
For code, a pair of `` back-ticks gives code rendering—trumping interpretation of possible mark-up characters therein. Thus, I can show the italicisation mark-up as typed: using _underscore_ or *asterisk* pairs to generate italics.
This code block form:
This could
be some
code
…uses four space characters at the beginning of every line and is the mark-up used if you click the ‘code’ formatting button in the message drafting box when more than one line of input text is selected.
If you want some coloured code try the following method:
$MyString = "A test of " + $MyList.at(1);
This form is achieved by placing a sequence of 3 back-ticks on a separate line before and after the code you wish coloured. Markdown doesn’t have a special Tinderbox code syntax colour library but whatever default it chooses seems to work agreeably well.
Using code mark-up for action/query/export code in forum posts is commended. A foible of the forum is to auto-convert quotes types as ‘straight’ into curly ‘typographic’ quotes. Here, I’ve typed straight double quotes in both cases but enclosed the second case in back-ticks: “Hello” vs "Hello". Same goes for single quotes: ‘Bye’ vs 'Bye'. By the time a post is made the reader can’t tell what quote type the user intended in their code example. Occasionally, you do want to use a curly quote, usually as a search character within a regex or literal find string: $Text.contains("“") will look for a single opeing curly double quote character. Gah - who know it was so hard to correctly record meaning.
Well, you are in good company then. Actually, in the underlying XML, the list is stored that way. If stored in an attribute defined as list-based (List, Set) Tinderbox will then know this is a multi-value list string when reading the stored value.
The problem with semi-colons comes in-process, so to speak, as it isn’t possible to tell Tinderbox "this semi-colon is a literal semi-colon, but that one is a list delimiter.
I think the easiest approach, even if it takes a few extra lines of code is to temporarily replace the actual semi-colons in the source then put them back once done. It might seem like more work, but once the code is in place you won’t see it and there’s no real overhead. So I concur with your earlier one-liner:
That makes it easy to remove the last part and look at the interim result without messing up the existing $Text. Of course, if you already use $MyString for something else, just pick another String-type attribute.