Hi to all. I haven’t had the time to keep looking into the technical aspects of Tinderbox lately, but I would like to have a say on this, as it is not exaggerated to say that the rtf path will progressively exclude Tinderbox from my workflow.
Web links are my main problem with rtf. I use them in Tinderbox for inline referencing because it makes no sense to me to keep notes so short that it is feasible to write their source as Tinderbox attributes -otherwise great for classification purposes.
The XML format you are discussing is important for preservation, and perhaps for quick and risky editing. Let’s look at what happens with web links in TB’s bakstage. Here are the three takes at them I can think of:
This is what gets encoded in the test.tbx file:
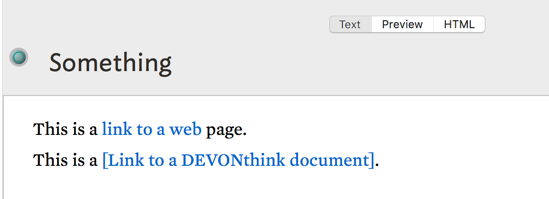
- For the web link in the first paragraph, there is no immediate way to view whether it has a source:
<text >At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.</text >
<link name=“*untitled” sourceid=“1521157429” … URL=“x-devonthink-item://F904B108-33C1-4B3C-A24B-4D2771D7BE8F” />
- For the second paragraph, I can see that the paragraph has a source, but there is no immediate way to identify its link because there are many untitled links in the .tbx file:
<text >Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet [@notitle2010, 203]. </text >
<link name=“*untitled” sourceid=“1521157429” … URL=“x-devonthink-item://B4FEE38B-E303-499F-A206-D65AA61BACA2” />
- Only for the third paragraph both the source and its link could easily be identified:
<text >Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet [@title2015, 408]. </text>
<link name="[@title2015, 408]” sourceid=“1521157429” … URL=“x-devonthink-item://7E780413-4FD4-4C09-9146-0089874A3801” />
Therefore, it is important for me to follow the third procedure: write titles for web links. The problem with web links in Tinderbox is that they seem to be placed to a specific location in the pane, not integrated in the text. For me this has proved to be an unsormountable problem to use Tinderbox effectively.
This problem would be perfectily solved with markdown, because the link would be in the text, written as [@markdown2015, 408](x-devonthink-item://3ADA3328-585F-404A-9CF9-EC60447B25F1), automatically rendered as @markdown2015, 408.
I understand Tinderbox as an app centered in content. It has great export options to other file formats, so that the file can be further processed with specific tools, either its content or its formatting for final publishing in the web or pdf. The customizable import and export options are a great strength because TB does well what is thought for, and then it can be integrated in a wider processing workflow.
Both for content and format processing I find markdown superior to rtf. As it happens now, I cannot even reelaborate the text content of annotations in Tinderbox because their references get displaced. For the same reason, text cannot be transfered back and forth to Sublime Text for heavier text manipulation tasks.
If I may give my opinion as a user, I already find important for TB to follow the more modern markdown path. Admittedly, I don’t know how hard it would be to implement. There are many inspiring open source markdown editors, both for the desktop and mobile: Leanote, Turtl, Markdown Edit, Meemo, Dillinger… and my favourite, because of its live preview: Typora, although not open source.