I like this proposal a good deal. I don’t think I would ever use the “contiguous” function, so my preference would be for it to be “off” by default (the sequence of values doesn’t matter in my usage, only that certain values appear together in whatever order). I really like the “constituents” flag, as I could see using that to narrow analysis in possibly interesting ways.
As for @mwra concern about degrading gracefully if too many notes are provided, I suppose there might be some error message (similar to the messages that pop up when Agent queries are running amiss) that says the coOccur is going to cause problems and needs to be scoped differently.
I also agree with MarkA about chaining off “list” or “set” instead of “collect.” This makes sense to me.
@PaulWalters thanks. I wasn’t disparaging the idea. I’m with you in being open to the ideas/needs of others but (a) failed to think of an actual use case (which is simply a failure of my imagination and not the use case) and (b) would require working only off Lists-type data** as Set-type cannot be assumed to return a consistent sort which underpins the sense of being contiguous.
If implementing this (and if supportable at likely scale of use) I’d agree matched value pairs might be a sensible default but for analysis being able to extend to matched N-value sets might be of interest. This is aptly informed by a remembrance of a number of recent research tasks where I ended up painfully grinding multiple values down to a (pre-eminent) single one in order to do further analysis.
** noted that collect() returns a list so your chained idea makes more sense on reflection.
So, I think we’re actually on the same page (bar fine detail on input sort order!).
The other part of this is what .coOccurence() would emit. Although not a formal data type, TB now has look-up lists and perhaps that might be an outcome, a list of “value set:count” items, e.g. “red blue:2;blue green:4”. However I’m not sure what the delimiter used in the value set part would be as both space and underscore might form part of actual attribute values.
Are we thinking of .cooccurrence() or .cooccur()? I’ve been using the original formulation that @derekvan proposed, but either name for the function works for me.
Output. If it output a .plist it would be a key/value pair. Can a structure like that exist in Tinderbox? I understand the issue about delimiter. Perhaps /n ?
As to the operator name, for my 2¢ I’d suggest the shortest compound variant that makes sense (less typing!) and using internal camel-case so as to follow the style of other compound action names. Thus list.coOccur() would seem a choice but in truth the inputs/outputs are of more interest.
As to output, unless Tinderbox were to add some new form of view (or in-map visualisation) it might be best to pump out something that can easily be consumed by the likes of an open system such as R (as well proprietary like Office Excel). I may be wrong, but I think both those apps (and similar) would most easily ingest a table with notes ($Name or some UID) on one axis and all the discrete values of the analysed attribute on the other. Working this notion further with example data from up-thread, I’d expect tabular like this:
Name red blue green purple orange white
Note1 1 1 1 0 0 0
Note2 0 1 1 1 0 0
Note3 0 1 1 0 1 0
Note4 0 1 1 0 0 1
Note5 1 1 0 0 1 0
One might add a per-row value count but I suspect that, if exporting to another app for process, the value count might more easily be created after ingest into the other app.
The above data table might appear easily created by exporting an agent with the header line as the $Text and the data rows via ^children^. However, unlike the above example, for more than a few values of $OpenCodes (or whatever multi-value source) iterating through the values might be a complex task for many users so an action or export code to do this would help.
Once the data is exported it might be possible to run the likes of R in context of the export folder so output could be seen from within Tinderbox by viewing the exported page’s preview after the contingency analysis had been run. It does, however, depend on what exactly the user wants too see: a plot of all contingencies (perhaps a a from of heat map)?, a listing of most common, co-occurrences?, etc. A problem for this sort of exploration is that you may often need to try several approaches if you don’t yet know the relationships hiding in the data.
In summary, unless Tinderbox is actually going to visualise the contingency table in some fashion within the app, this task might be better handled as an export code (or an action primarily intended to be called during export). These is offered for discussion and is not a firmly-held viewpoint.
I think a tabular export code output such as in the example would be a possibility. But the original request seems to be a different output form:
So, output like that needs to be the $Text of a note. Let’s say we have an agent whose query find all notes where $OpenCodes (for example) contain a value, or some other condition. Say the agent is named “Coded Notes”.
Some other note (call it “Co-occurrence Report”) would have a rule like this:
EDIT: the link here now points to a revised version of the file that uses a stamp rather than a rule for reasons described in the thread “Annotated co-occurrence example code”.
Building off @PaulWalters’ demo “Open Code Example with Export.tbx”, I offer “OpenCode Example with co-occurence.tbx” (zipped TBX) with two extra agents. One uses the unique sorted string** of all code values for a given note and finds occurrence. this means shorter strings are detected within longer ones as both use the same sort order in construction.
The second does what I think Derek’s after. It finds all co-occurrence of value pairs (where AB is considered the same as BA) regardless of the number of $OpenCode values per note; notes with zero or a single value are ignored as no pair exists.
I’m sure there are edge cases and I’ve not even tried to extend to triples or quartets, etc. I hope this puts us all back on the same page again. I’ve only tested o the example in the TBX I used, I suppsect with 100 discrete $Opencode values performance might be less snappy!
** I fixed one error in the original TBX as when casting $OpenCode to $CodeCollector, .isort wants to be chained before.format() so it is the sorted list that gets formatted rather than a single formatted string (that can’t be sorted!).
Hi Mark A – Was curious to give this a look, but I get a 404 error at the link. Here is the way the link is registering for me (when I do the right-click “Copy Link Address” command):
Thanks! This is a level of analytical complexity that is beyond my own real-world needs, but it’s interesting to see how everyone here has approached it.
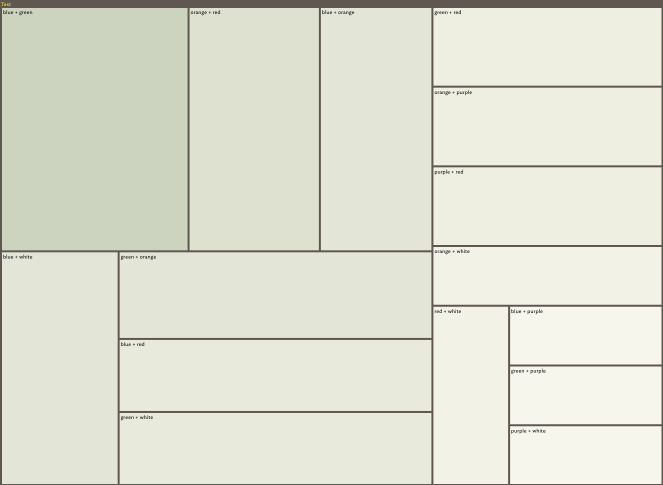
The nice aspect of this general approach (aside from actual method of implementation) is that it nurtures incremental formalisation, avoiding the need to over categorise to single topics when the ‘best’ (most appropriate) topics may not be self-evident. The data from the above pair experiment came out as:
blue + green: 10
blue + orange: 6
blue + purple: 2
blue + red: 5
blue + white: 6
green + orange: 6
green + purple: 2
green + red: 4
green + white: 5
orange + purple: 4
orange + red: 7
orange + white: 3
purple + red: 4
purple + white: 2
red + white: 3
The following was mocked up manually, using the co-occurrence number for both treemap cell area and colour-shading (but I’m not visual designer!). Still, this feels as though it points to one way of looking at this data within Tinderbox - it’s scaled by 50% here just so as not to be to big in a post:
Edit: this additional stuff is not in the file posted earlier.
Hmmm. I’m not sure what that means. (I don’t know what “topic” refers to.)
Are you suggesting there’s no need for the .cooccur() action that’s been discussed above? I think there’s still a very good case for adding that new action.
By ‘topic’ I was referring to the values (or tags, keywords, metadata - pick one of many common terms) used in the co-occurrence evaluation. In this particular, case the attribute values set for the user attribute $OpenCode.
Err, No. As the treemap is of the co-occurrence output, the exercise above would otherwise be nugatory.
Rather, I re-iterate, that having a means to investigate (with ease) co-occurrence lessens the pressure to over-reduce the number of topics (attribute values) during early investigation of data. Currently, it’s easier to analyse single-value data, some form of co-occurrence reporting would broaden the scope of choice.
I’m just now having the chance to check this out. I plugged in my real notes into the sample file Mark provided and it did present the pair co-occurences as requested. So, thanks Mark!
However, I’m not sure what the path forward is. I don’t think I’m going to be able to understand all the working parts to the agents in this file, so it makes a bit nervous to depend on it through successive TBX versions. Also, it’s not clear to me how to manipulate the results (the co-occurence all pairs example isn’t sorted by number, which might be nice, but I wouldn’t know how to do it). Also, I’m getting pretty frequent crashes with the file. So, it seems to me that asking @eastgate to implement the features discussed above is still worthwhile.
(also: I’m not sure I understand the differences between the “co-occurences all codes” and “co-occurences all pairs” agents. The “pairs” agent has lots and lots of hits in my real data. Yet the “all codes” agent has very few. I would expect that the “all codes” agent would return all pairs, plus triplets and others. Yet it doesn’t seem to contain any pairs.)
I suppose the question at this time is for @eastgate – whether the dialog in this thread, above, is persuasive and provides enough sense of what the .cooccur function might do. Or if @eastgate believes the concept needs further explication and Mark B has questions for us to dialog on.
I believe all users participating here recognize that this is not a simple feature, the engineering needed to implement it is not clear to us (but is likely significant), the time-to-market is unknown (to us), and the base of potential users is not large. However, for researchers, especially qualitative researchers, the feature could be well received as an interesting addition to the Tinderbox feature set.
In case it helps, I’ve broken out the code used in my demo up-thread, clarified it slightly and posted it in a separate thread to aid discussion without causing thread drift here.
I concur with @PaulWalters’ last. I hope @eastgate has enough to consider whether something is feasible in an action operator wrapper. As my demo code, doing un-ordered pairs is do-able (but it’s not beginner’s code). going to triple and beyond is likely not feasible, as action code, but might be if done directly in the app. I’ve assume an output as text but perhaps there might be a way to use existing (new?) views to also help visualise the result.
We’ve been talking about list and set variables; do we also need to do this with numeric variables? If so, is it sufficient to adopt a “bin” strategy like Attribute Browser?
Is this ideally an operator (.coocur() ) or a view – like Attribute Browser?
The next question will be, “is the cooccurrence distribution random?” I think that’s Student’s t-test, but it’s been ages since I’ve used that in anger myself. I could use a hand on that.
Q1. So you’ve reviewed 500 papers and added added multiple values (tags, keywords, whatever) to each item, indeed possibly several different attributes on different aspects of the work. now, you want to get a feel for which terms cluster together. Whilst most individual note attributes may only have a few values the unique values across all notes maybe large so the agent-per-value approach doesn’t work. It’s thus useful to see how the values cluster - or don’t. Do ‘winken’ and ‘blinked’ turn up together (co-occur) a lot? Odd how ‘blinken’ and ‘nod’ never co-occur.
In you example (b) I’d imagine title and counties to be separate attributes’ values, though you could merge them for this purpose. TL;DR … “which tags co-occur the most?”. I think this is a feature you’ll go find because you have the need rather than one you’ll create data to use.
On the viz front, it did occur to me that if (aliases of) notes were placed on on a map as small shapes ($Height/$Width are intrinsic) with title as the $HE then you could plot clusters. Not tested, but I’ve a sense treemap could also use a co-occurence data to show things.
Q2. I don’t see why not, though I think binning would be needed. An opportunity to feature request something that AB view also needs - ability to set bin size and/or open max/min (i.e. an above X and below Y bin at each end of the range). In the case of this analysis, you might want to outside max/min rather than create a bin.
Q3. Ouch, if it is to be ‘cooccur’ please lets be consistent in name style .coOccur() - I see no upside for the user if we arbitrarily move away from the action code style of interCapitalisation for operators. (I don’t mean this in a snarky fashion - lest it read that way).
Q4. At this point I think we should be punting to R (or SPSS for the $$$ folk) via export. Here as in a number (not to mind as I type) of cases I think the best approach is export or a round-trip via command line. IOW, action if any might be to look as any changes to run-command that might be needed, included parsing of the returned values.
The name in this thread has just been colloquial and inconsistent; not a firm proposal. I imagine @eastgate would figure out the best term that fits into the existing taxonomy.
Lots of folks using TBX for task management. Let’s say you want to see a report of all your tasks tags to see where you’ve been spending all your time. Or maybe you’ve fed Tinderbox your time-tracking data and want similar analysis.
Let’s say you’ve got notes with some kind of geographic data in them (cities where X events are happening, or states with X health care features). You could run this to see the various connections.
More broadly, I’d say this is the kind of feature that maybe brings in new users. People who want to run co-occurences know who they are and may find Tinderbox’s implementation more straightforward and manageable than learning some stat package (that’s my case!). And, then they see TBX does so much other cool stuff, they’re sold. For me, adding this tool makes Tinderbox nearly a complete qualitative data analysis package–it would have everything I’ve typically sought. Lots of folks have been interested in that video whose author escapes me now, where he interviewed some folks, broke up the transcripts in Tinderbox, then “tagged” them by dropping them onto adornments in various ways. One logical next step is to find co-occurences in tags …
As for view vs. operator, I could see it working either way. The operator is straightforward, but with the right implementation, I could see AB being the best way forward, as long as it was flexible enough to provide the right results binned in the right ways. If the bins, for example, were pairs of tags with numerical counts, this would be great as it would give me immediate access to the notes themselves within the bins.
Interesting. If AB view could use an action code filter (that’s not an agent query or rule) that would be cool. A container (or agent) could scope the notes to consider but we’d need a way to configure the co-occurrence criteria but given that existing AB view feature could cope with visualising things.
I’d also the echo the point about qualitative tools. Please spare me NVIVO! For all the some-assembly-required element of aspect of Tinderbox it beats the you-are-feeding-a-predefined-database approach of so many tools.