No worries, terminology tends to vary with apps. I only make the point with ‘ziplinks’ as it invariably leads users to treating the results as a special type of link and thus looking for affordances for them that aren’t (can’t!) be there. 
I’m sorry it has taken me a while to produce this for all of you, but we’ve just been able to return to refining our Tinderbox file. As many of you have rightly pointed out, it’s far easier to do reproduce and analyze problems with smaller files. Here’s the file, which is a derivative of @jprint714’s template file:
Sample file with comments ziplinks.tbx (291.0 KB)
I’ve used the [[< {Comment-Note name} |COMMENT LINK:: >]] ziplinks syntax - code structure to create comments in notes.
As you can, I’ve used {Comment-Note name} part of the code to name the “comment-notes” (our shorthand vernacular).
Here’s the problem we’re trying to sort out: The notes that contain the ziplinks are colocated in the “I M P O R T S” folder, where they first land. However, due to the volume of notes that we’re managing, we tend to focus on alias notes that are organized in agents, either in the Outline or AB views.
We are trying to figure out how we can setup agents that will locate / collect “comment-notes” that are generated by ziplinks.
For instance, is there a way that we could create an alias that for ziplinks-created “comment-notes” that relate to any of the Research Questions attributes?
We’re open to other, suggested approaches that will help us organize and group them together.
Thank you for your assistance in this matter.
The zip link-creation method creates text links. The term ‘ziplinks’ thus has no useful meaning for those trying to help you other that you used a typed syntax to create some links. This makes it hard to help as we don’t know to what you’re really referring.
Using the zip method tells us how you made link but not what those links are as … they’re just text links. It would help if you referred to the nottes by name (ir unique) or by path.
Re the reasons above, how do we know which folders they are.
Unfortunately your file doesn’t contain such a folder!
How do we know what those are.
A polite suggestion here is to get a co-worker or family member to step through (wirthout assistance) your instructions to check that what you describe is actually present in the demo/description. This isn’t snark. We all make these mistakes: what is in our mind’s eye isn’t necessarily present in the materials provided.
I seem to have used the wrong terminology once again. I apologize for causing additional confusion.
By your account, I should instead be using the term “text links” instead of “ziplinks.” I’ve produced two screenshots of my file to better explain what we’ve done, and are aiming to do. This first screenshot shows the two notes that contain “text links,” denoted by the blue font “COMMENT LINK”:
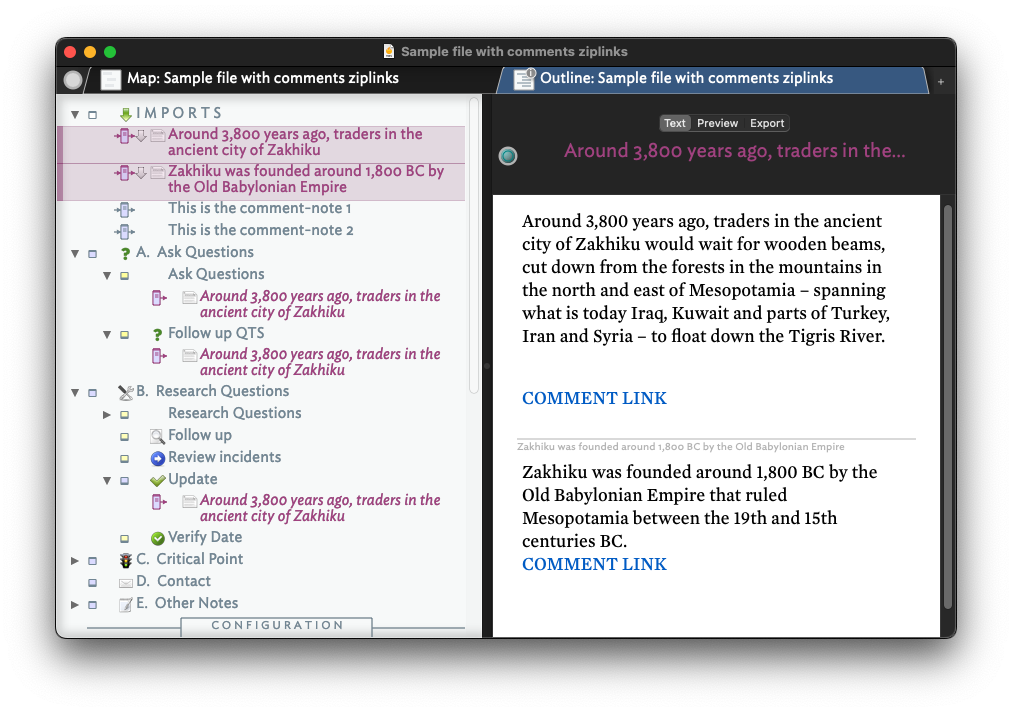
This next screenshot highlights the location of our “I M P O R T S” folder, the “comment-notes” (our term) created by “text links,” and some of the agents we use to look at our notes:
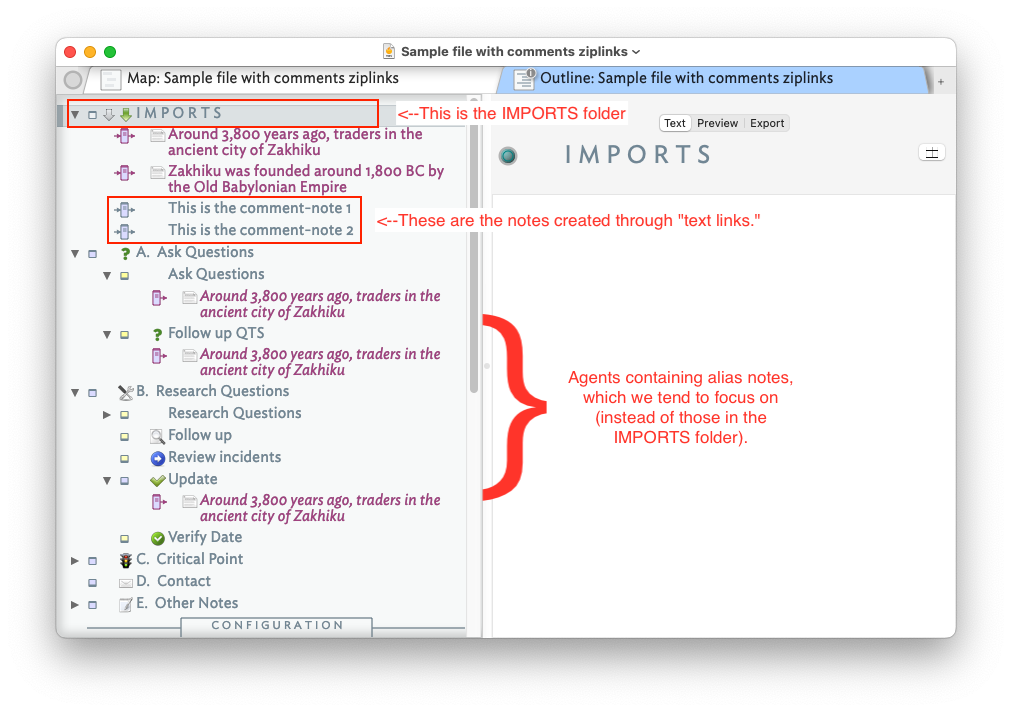
Again, we lean on our agents to focus on select notes, especially as the volume of our notes grows over time.
We’re trying to see if there’s a way to create aliases for our text link-created “comment-notes” that relate to any of the Research Questions attributes.
As I said, we’re open to other, suggested approaches that will help us organize and group them together.
I hope I’ve been more clear about what we’re seeking to do.
Thank you for your assistance.
No apologies needed. I only noted the ‘ziplinks’ reference as it makes meaning generally less clear to the reader, which I’m sure wasn’t your intent.
I was wrong, so my apologies, it is the top line of the outline and must have scrolled off-screen. Anyway, I was wrong to say it wasn’t there!
Yes please, if only because it stops people assuming ‘ziplinks’ are somehow identifiable as a type of link, when instead it just means the link was made be a typed shortcut. Also the ‘zip’ linking method has so many options, the result of method might to more than create a text link!
Ah, OK, that helps - no {} involved! given you refer to agents to look at you notes, I assume that by “a way to create aliases for our text link-created “comment-notes”” , what you mean is “how to I write a query that matches my new comment notes?”. If so…
An agent can only query for something unambiguous; the test for any note/item should return at true or a false. Sadly, two things the ‘zip’ method can’t do is to set a link type for the link or to set $Tags in the new comment note. So, we can’t query by link type or via a keyword such as a value in $Tags. But, fortuitously, it looks like you use a convention of starting all your comment note names “This is the comment-”. So, that could be your query:
$Name.beginsWith("This is the comment-")
The .beginswith() operator does a case-sensitive, non-regex match so it ideal here lessening the need for using .contains() or such. If you know that all the comments come in/under the “I M P O R T S” container (or only the ones there are of interest), you could use this more scoped query:
descendedFrom("/I M P O R T S") & $Name.beginsWith("This is the comment-")
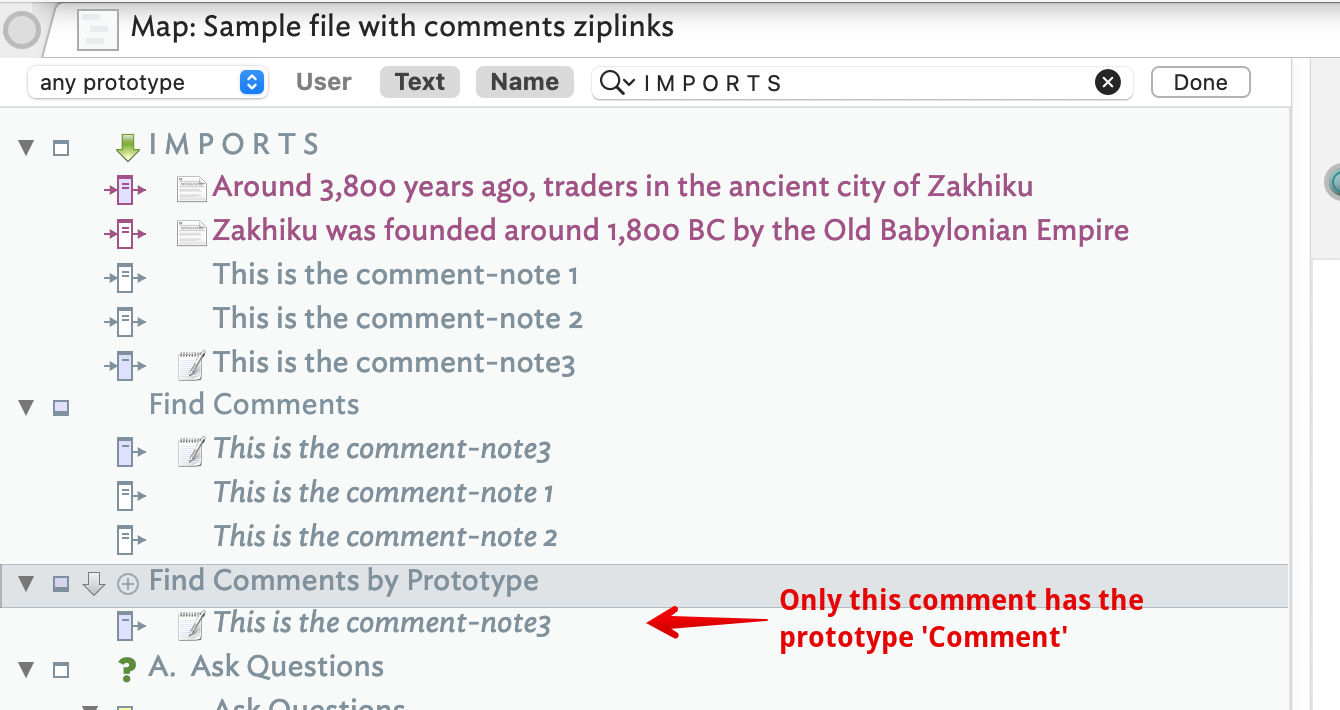
Here is the latter used in your source document in a new agent called “Find comments” and whose query is the last example above.
New to v9.5.0, the zip method can set a prototype. So if we make a prototype called “Comment” then this zip syntax makes a comment and sets the desired prototype: [[<This is the comment-note3#Comment>]]. This allows you to use a simpler query:
$Prototype=="comment"
or
descendedFrom("/I M P O R T S") & $Prototype=="comment"
Implementing the first of these two, notice how the agent matches only the new comment I made (via the zip syntax above):
Form that agent you can review the comments and set extra, appropriate data (e.g. $Tags or other attribute data.) so that you existing queries can now match the comments without needing their queries to be modified. In other words, the extra data you apply will be dictated by how your existing agents’ queries are structured.
Does that help? ![]()
1 Like
It does, indeed. Thank you very much for all of this. I think I’m getting there. Just a few more follow up questions, and then I think I’ll have it nailed down.
Before I embark down that road, I should say that I thought there might be a way to formulate an agent query by using the [[< {Comment-Note name} |COMMENT LINK:: >]] text links syntax - code structure. If I understand you correctly, you’re suggesting that we forgo that route and just use Regex in the form of: $Name.beginsWith(“This is the comment-”) Have I got that correct? It just seemed to me that the former was a bit sharper than relying on Regex.
I appreciate your suggestion regarding more using a more scoped query, namely:
descendedFrom("/I M P O R T S") & $Name.beginsWith("This is the comment-")
We haven’t used that often in our queries, though I don’t know why.
In most cases our text links will come from notes in our “/I M P O R T S” folder, but I think we might want to add some comments as we go. If most original notes will indeed be located in the “/I M P O R T S” folder, should we keep our query scoped, as you’ve suggested?
A quick sidebar: Is there a Tinderbox shortcut for hopping from an alias to the location of the original note? Thank you.
Also, my text link note names, “This is the comment,” were for expository value only. Instead, we’d like to opt for something like “COMMENT:” but wanted to first insure that wouldn’t confound Tinderbox’s syntax. Would it?
If not, I expect we could string together a query for an agent that would look something like this:
descendedFrom("/I M P O R T S") & $Name.beginsWith("COMMENT:") $Prototype=="pArticles" & $AskQuestions|$Prototype=="pDocuments" & $AskQuestions|$Prototype=="pInterviews" & $AskQuestions
I expect we would have to create such query code and agent for all research and topical categories. Although, again, we’re all too glad to consider another approach other users might suggest. I fear we’re accumulating too many agents.
Thank you again for your assistance with this matter.
Edit ▸ Show Original (⌘-R)
No, the zip linking method is only for creating text links:
- in the $Text area
- using keyboard-only input
The latter is the original drive for the feature: touch-typists resenting having to use the cursor/trackpad during link creation and thus taking their fingers off the keyboard.
The methods has never had any relationship to query building. Queries, in agents or action code (find(), etc.) are always manually created, even if in some case part of the query is modified by code. An example of the latter is where you want the query to look for a particular attribute value but want the match to occur to a value in the agent that you might change. So the 'manual ’ query might be:
$MyString=="Foo"
But changed (manually!) so the query uses the agent’s my string:
$MyString==$MyString(agent)
This is a very strange misunderstanding. What did you read that led you to suppose you would set a query using a mother for making text links in $Text? I’m truly scratching my head as the latter doesn’t involve queries.
Now I’m confused. For what reason do you think you shouldn’t use the method suggested.
But is doesn’t use regex … as I explained previously above. Do, please re-read the previous explanation. Had I suggested $Name.contains("This is the comment-") that would have used regex. The whole point of the suggested method is avoiding using regex when not needed. Why? Because is large documents (and projects may grow over time), regex are the most computationally expensive action code. In a small doc, no worries. In a big doc, if you’re asking why are things taking longer, it is often because we are using regex in always-on riles/agents … which often don’t actually need such an approach.
Thanks. This again is an issue thinking ahead to scale. If ‘I M P O R T S’ holds 10 descendant notes and the document 1,000 notes, the scoping argument (descendedFrom()) means the query first test only to 10 of the 1,000 with the rest of the query. no one must do this but i like to weave this in as good practice to learn. Don’t text notes you don’t ned to. In most cases either inside(), descendedFrom() or $Prototype== will significantly reduce the umber of items tested by the test of the query.
Did you try the alias’ context menu (i.e. right-click) which offers options to:
- Show Original. Available when an alias is selected. Locates the position of the source note for the alias. (Shortcut: ⌘+R)
- Show Original In New Tab. The original is shown, but a new tab is opened and selected. (Shortcut: ⌘+⇧+R).
Of the above, only the Show Original option is available from a main menu, Edit.
You are causing your own problem here by asking (without clarification) open-ended questions for which you want closed-ended (i.e. precise code) answers. We’re trying to help, but we can only answer what you ask, not what you forgot to mention). Thus there is a difference between something you tried that worked/failed vs something you imagine might happen but you haven’t yet tried or even fully explained (i.e. why you expected the outcome). That detail helps us help you. Not least it can show that you’re either assuming the impossible or wanting something that can be done but perhaps by a different manner.
ArgH, assumptive question again. You guess it might work but haven’t checked, not in your original question did you say your example used placeholders. The word `COMMENT~ is, as far as a I know, not a reserved word in action code†. These nuances aren’t guessable by humans, even less so via code. For clarity, either these can work:
$Name.beginsWith("COMMENT:")
$Name.beginsWith("This is the comment-:)
…assuming the comment note to match has an appropriately-starting $Name.
Why, that makes no sense, and wouldn’t work anyway as there is no AND or OR join after the second term. Step back and try to explain clearly what is the agent trying to find and which parts—if any—will vary from agent to agent? So, why not take that query, and in an answer post make each term a bullet point and explain why each query term is needed (and why it needs an and or join). Put another way what is each agent trying to match (and as importantly not match). I sense part of the complexity of your queries stems form copy/paste use and just adding on extra terms.
For instance. If it takes 7 query terms to find one group, you’re likely overlooking setting additional attribute values to hold that relationship.
†. But all known words (operators) in action code are already listed so be looked up.
I feel like I need to jump in here and answer this part of your exchange, because this code comes from a template file that I set up:
$Prototype==“pArticles” & $AskQuestions|$Prototype==“pDocuments” & $AskQuestions|$Prototype==“pInterviews” & $AskQuestions
To back up a minute, we’re using a Tbx file that include three different types of annotated text: Articles (news pieces), Documents (official government records or archives), and Interviews. These file types have the exact same attributes; they just have different badges and colors to differentiate them as separate prototypes (i.e., file types, so we understand their provenance).
We’re more than happy to change how we’ve set up and structured our prototypes if you and other users feel there’s a better approach.
But I’m responsible for the query code configuration using the pipe for the and / or function. I’m also happy to change that as well if you think there’s a better way of setting up the query. (I spotted the missing ampersand before that code, but understand what he was attempting to do.)
I’ve never included (descendedFrom()) before, but we’re happy to include in in our queries – especially since we keep our original notes in our IMPORTS folder – and we’re all to glad to include other code that makes Tinderbox work better.
@Roma has more experience than I do with code, so he’s better able to explain his thought process with Ziplinks syntax v. Regex approach.
My sense is that he was just asking about whether the colon might affect anything, since I believe sometimes parentheses can interfere with Regex queries (if I’m not mistaken). He can talk further about this, but I just wanted to explain my role – and thought process – in the section of code that you flagged.
Thanks!
This is very helpful as it offers a way to simplify your query. First we can clarify your existing query a bit. Consider this part—I’ve added line breaks to show what I think you are trying to test:
$Prototype==“pArticles”
& $AskQuestions
| $Prototype==“pDocuments”
& $AskQuestions
| $Prototype==“pInterviews”
& $AskQuestions
As written the first two $AskQuestions (the short form asking if that has a value) are redundant. Why? Because the query is parsed left to right, so the third test is not | $Prototype==“pDocuments” & $AskQuestions as I think you intend but | $Prototype==“pDocuments”. I’m not sure the different totally matter but neither to you want the wrong result and not realise. Better would be to add some parentheses to indicate the order (just as you might in a spreadsheet cell to indicate the order of evaluation). Thus:
($Prototype==“pArticles” & $AskQuestions)
| ($Prototype==“pDocuments” & $AskQuestions)
| ($Prototype==“pInterviews” & $AskQuestions)
If we want to simplify, we could do this
($Prototype==“pArticles” | $Prototype==“pDocuments” | $Prototype==“pInterviews" )
& $AskQuestions
So, first we test that there is a match is any of the 3 prototypes, and then test $AskQuestions. But we can do better. If the prototypes are the same we can set a simple user boolean $IsQueryData and set it true in each of the 3 prototypes. All notes using only those will thus inherit the $IsQueryData true value. this allows further simplification.
$IsQueryData & $AskQuestions
For a few seconds setting up the boolean, you now have a much simpler query requiring only two tests. Also, you can easily add to (or remove from the group of 3 prototypes by altering their $IsQueryData.
This is a nice real world example of where emergent structure (your original long query) can be improved by adding a user attribute.
Now, looping back to the newer part of the tread, re comment notes, we have:
descendedFrom("/I M P O R T S")
& $Name.beginsWith(“COMMENT:”)
& $IsQueryData
& $AskQuestions
which is a bit less complex. However is you already have an agent that matches $IsQueryData & $AskQuestions then even more efficient is to search that for the first two terms. So…
Let’s assume we have an agent called “aQuestions” (as I don’t know its name in you doc—if there is one) with the query:
$IsQueryData & $AskQuestions
Now, our query for comments only needs this shorter query:
inside("aQuestions") & $IsQueryData & $AskQuestions
instead of the 8 term query we started with.
There is no ‘must use’ here. You need to use what is pertinent to your layout and to understand how your queries work. If “I M P O R T S” only ever has direct children (and no descendants of those), or if only children are to be queried, then inside("") is fine; otherwise you may need descendedFrom().
to clarify, the only different between inside() and descendedFrom() is the first look only at immediate children whilst the latter looks at both children and all their descendants. Consider this nesting in the outline:
I M P O R T S
Note X
Note Z
Note Y
Here inside("I M P O R T S") would not match “Note Z” because it is not a direct child, but rather a child of “Note X”.
There are no colons here, as I read it. I’ve already pointed out that the zip syntax is not persistent, it is something you type in the moment to make a new text link (and a few other optional things). Thus the ‘zip’ syntax is never seen by a query, only any note name or text arising from its use.
If the questions is “Is a colon problematic in a Tinderbox note name?” the answer is No; see more on problematic characters in paths/titles when using actions or queries.
Personally, to accomplish this, I would use my automated note creation and linking method via the population of an attribute. You could create an attribute called “comment”. In that attribute, you put the title of your comment. Tinderbox can then create the note, link it to the base note, populate other attributes in the newly created note as needed, and then you’re off to the races.
The most common way to do this is to add the common as a note, linked to and from the source. There are two handy commands to make the new note and the links in once step: “Note /Footnote/Add Footnote As Sibling” and Note/ ▸ Footnote ▸ Add EndNote.
This is, indeed, extraordinarily helpful. I’m starting to gain a stronger understanding of how Tinderbox codes. And yes, @jprint714 clarified what I was trying to explain regarding problematic characters in paths/titles when using actions or queries.
I fear, however, that I’ve not fully grasped one crucial step in what you’ve outlined above in setting up the boolean.
We have an “Ask Questions” agent and an $AskQuestion attribute. I’m following up to this point:
That configuration is clear. Yet I’m not grasping how we’re assigning that to the user boolean $IsQueryData and then setting it true in each of the 3 prototypes.
Could I trouble to clarify what I’m overlooking in this particular step?
Thank you.
First in summary, then detail:
- Add a new user attribute
- In each affect prototype set a vale for that attribute
- Update the agent query to reflect the above
Adding a user attribute
Open the Document Inspector’s ‘User’ tab (it might be good to have that link open whilst you do the task. click the gear-wheel button:
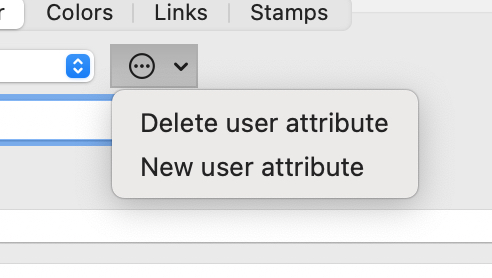
…and select new user attribute. Here, I’ll assume the attribute’s name is ‘IsQueryData’ to fit with the previous example†. Now we set the name and a ‘boolean’ data type from the pop-up menu. In addition add a description (press Return to save the description) so you and collaborators remember what the attribute is for: don’t use my specimen text but write something that makes sense to you‡.
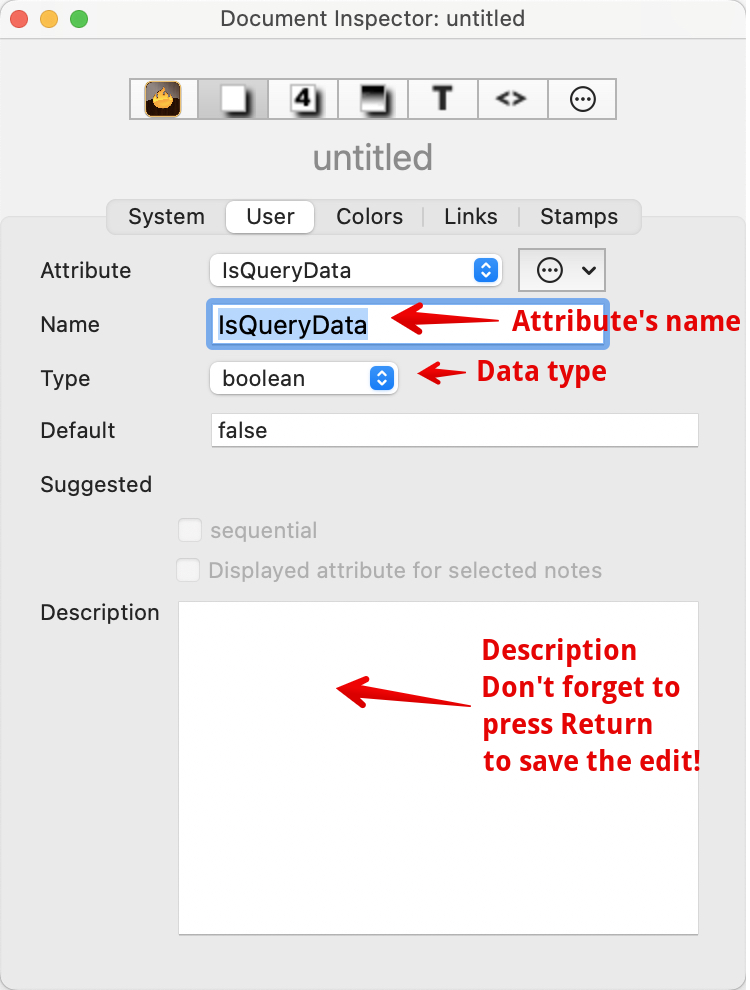
(Notice I forgot to save my specimen Description before clicking away from the Inspector to take this grab)
Your document now contains the new ‘IsQueryData’ boolean attribute and which is available for use by all notes/containers in the document (including prototypes, adornments, agents, etc.).
Setting affected prototypes and notes
Here we will just be modifying your 3 prototypes ‘pArticles’, ‘pDocuments’, and ‘pInterviews’. There are many ways to do this. Here, I show using the Quickstamp Inspector. First we select the prototypes in the view pane, then in the Quickstamp:
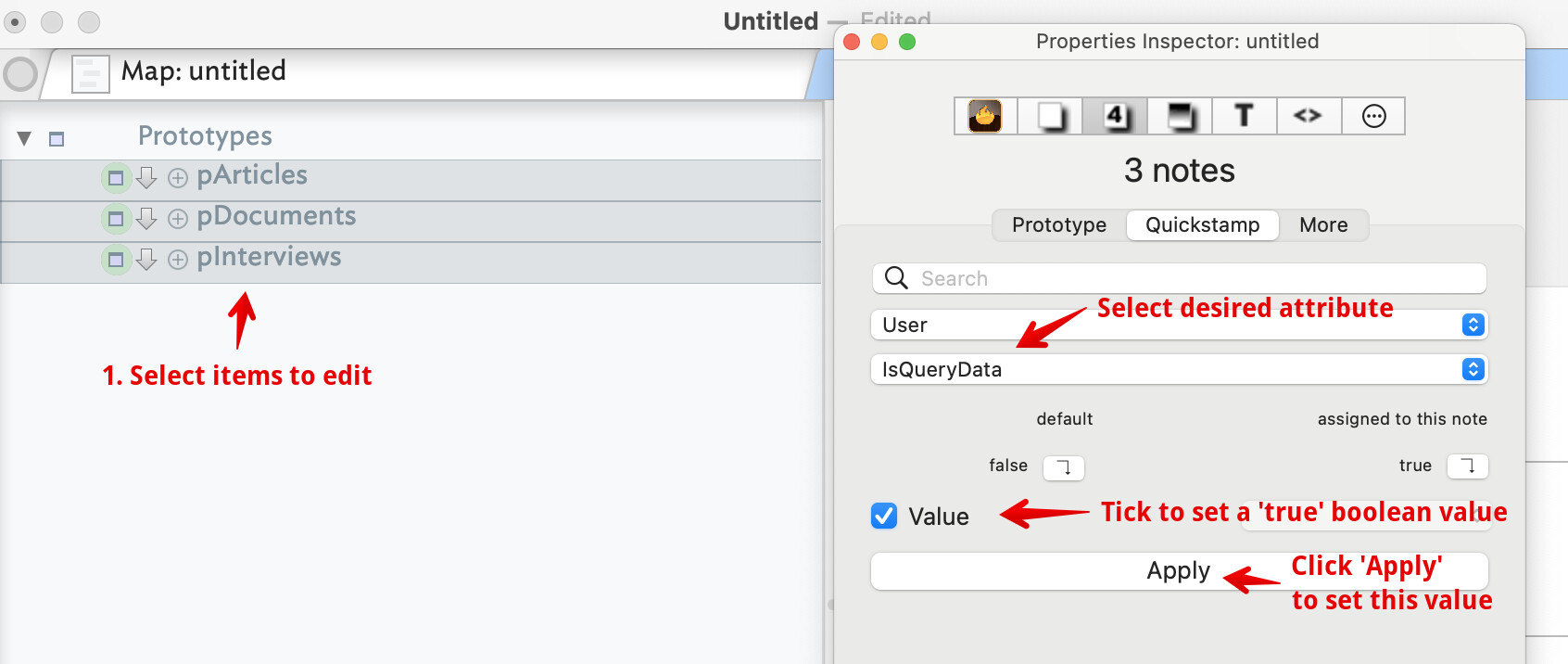
Notice that when a boolean-type attribute is selected, the value input box becomes a tick box. By default a boolean is false and the box is unticked. As you want it to be true for these 3 items, tick the box and then press the Apply button. It is not until you press the button that the value is written to the 3 prototypes.
Test the settings (Optional step)
Make a new agent with the query:
$IsQueryData
This should find only 3 matches—the 3 prototypes set in the last step. If you don’t, revisit the last steps and correct until you do get the right result. Otherwise test is done and delete this agent as you don’t want/need it anymore.
Revising the existing agents
Currently you have one or more agents with this query, or an older version:
($Prototype==“pArticles” | $Prototype==“pDocuments” | $Prototype==“pInterviews" ) & $AskQuestions
Find those agent(s) and edit their query to:
$IsQueryData & $AskQuestions
If you need to add other terms, e.g. arguments for Comment notes —as discussed above—then act as necessary to add them.
Done!
†. If you want a different name, use it and substitute it both in the inspector and in any queries/action later in the process.
‡. You’d be surprised how easy it is to forget the purpose of an attribute if you don’t apply it often. Months later, what was clear may no longer be so. A good Description is your friend in such circumstances.
1 Like