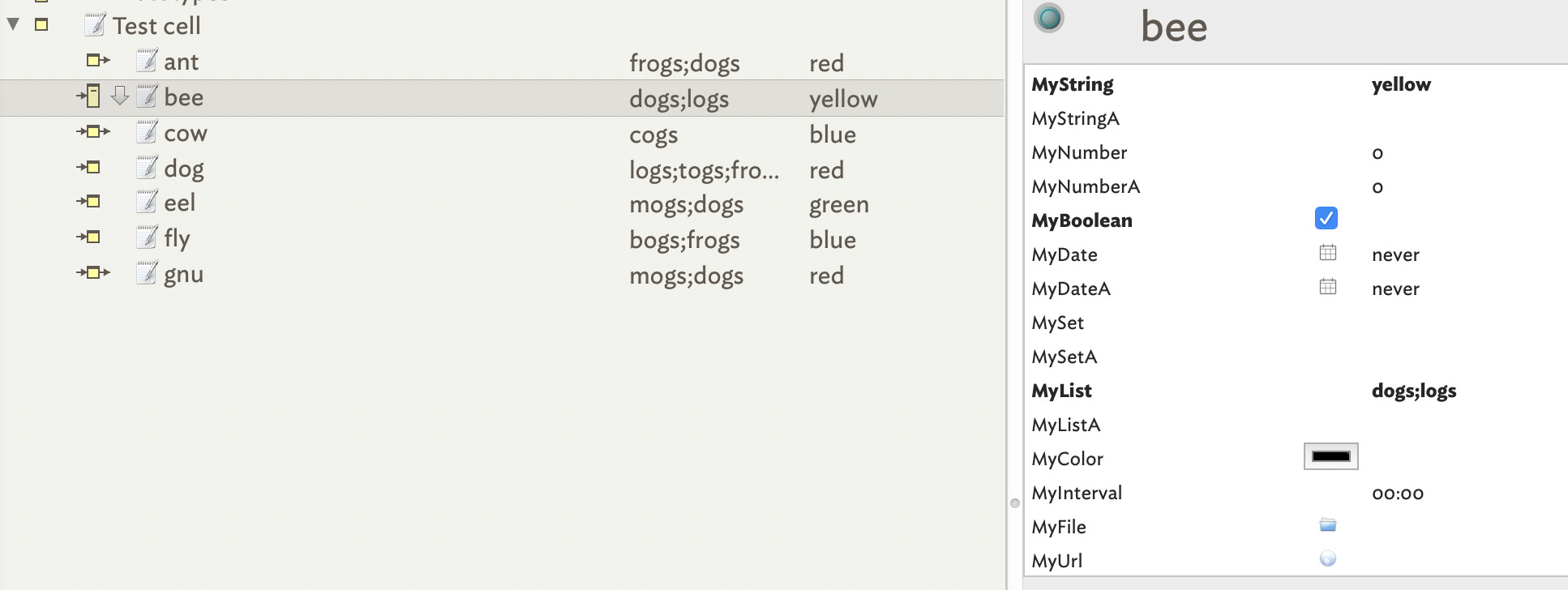
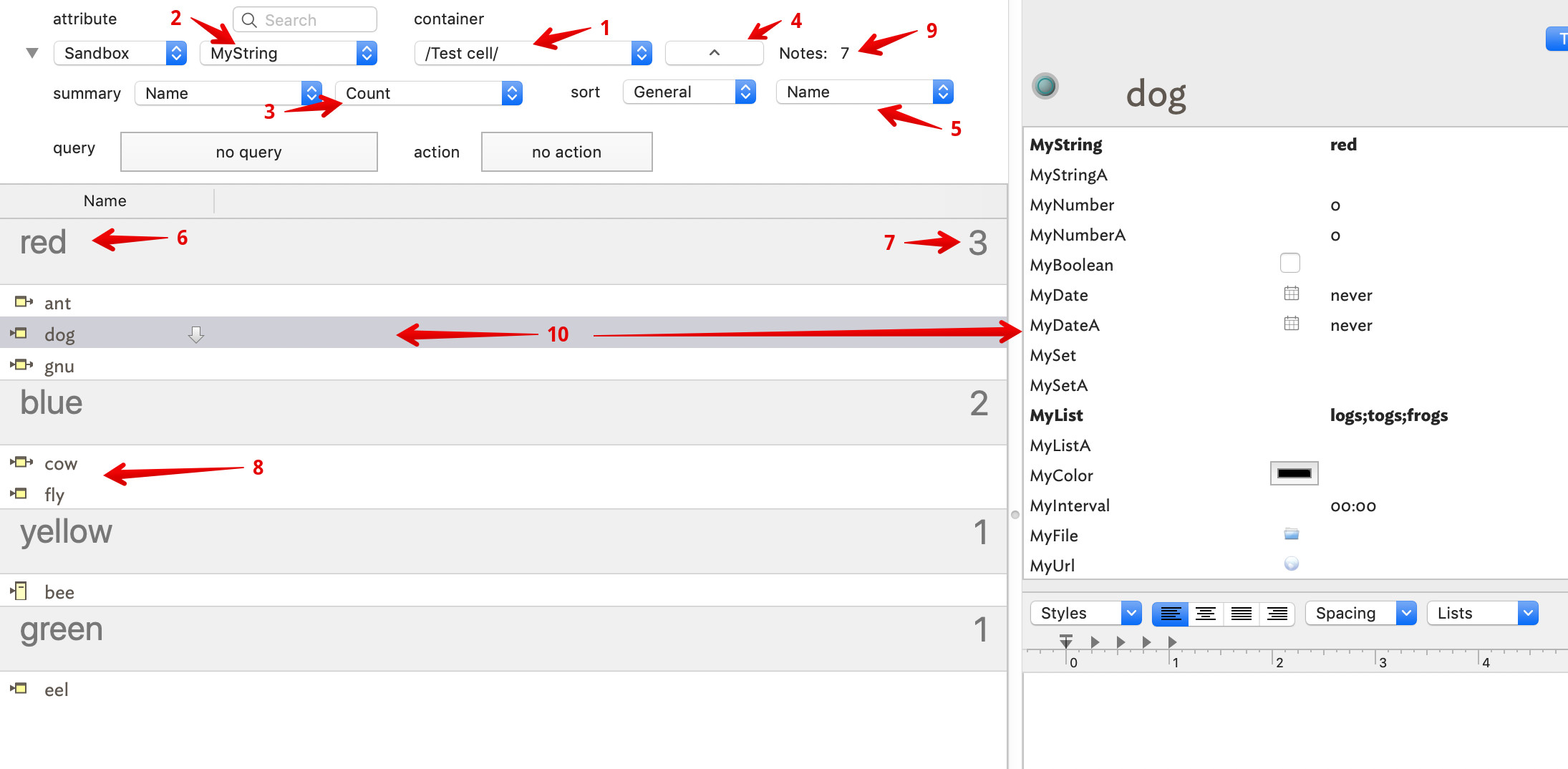
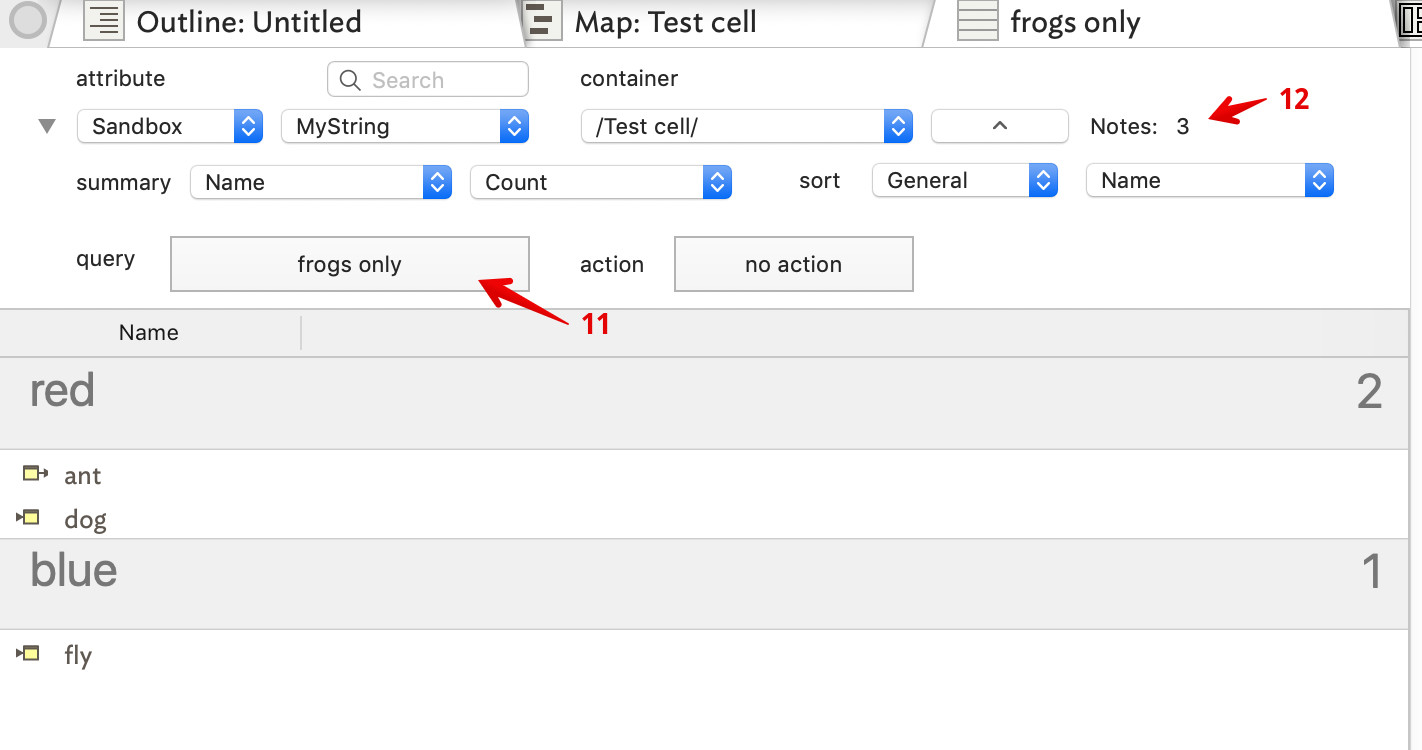
I’m importing a set of notes, in an OPML file format, into Tinderbox. The OPML file contains notes that have been organized in folders, arranged by categories and their respective values (or hashtags). Unfortunately, the OPML file contains many duplicate notes.
Is there a way to transform these duplicate notes into aliases (in a batch function) or is there some other way to achieve this, e.g., by creating aliases of the notes duplicate notes, and then deleting the original duplicates ?
Quick background… I first create these notes in another app, import them into OmniOutliner, and run a script (AppleScript) in OmniOutliner that re-organizes and re-formats my notes: it creates folders for my research categories, and then populates those folders with notes whose hashtags are paired with their assigned categories (e.g., the folder for B.RESEARCH: would contain all notes with the #Review_incident tags , the folder for 2.BACKGROUND: would contain all notes with #key_historical_event tags, etc.).
This process helps me prime complex note organization for Tinderbox, thereby freeing me up to use its other features more effectively. (I’m currently refining this process so that there’s better inter-app workflow between OmniOutliner and Tinderbox.)
BUT…unfortunately, OmniOutliner doesn’t yet support aliases. So, I’m trying to figure out a solution to transform my duplicated notes into aliases for my OPML -> Tinderbox file – through a script, another app, or any other approach.
Any ideas / suggestions on how I can achieve this?
Thanks very much for your help…