Thanks @satikusala for reviving what remains an important topic for me. For me DT3 and Summarise Highlights provides a quick and effective way to collect chunks of text to be reviewed and interpreted within TB.
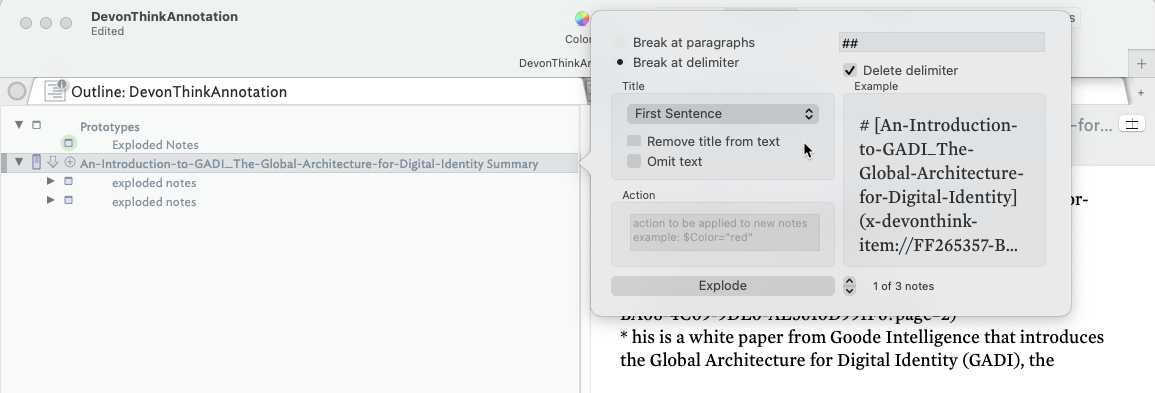
Unfortunately I don’t have an updated solution to the one I posted. I will however make one comment re. information that a DT3 provides in the summarise highlights document. Consider the following Summarise Highlight document produced by DT3 choosing the MarkDown format.
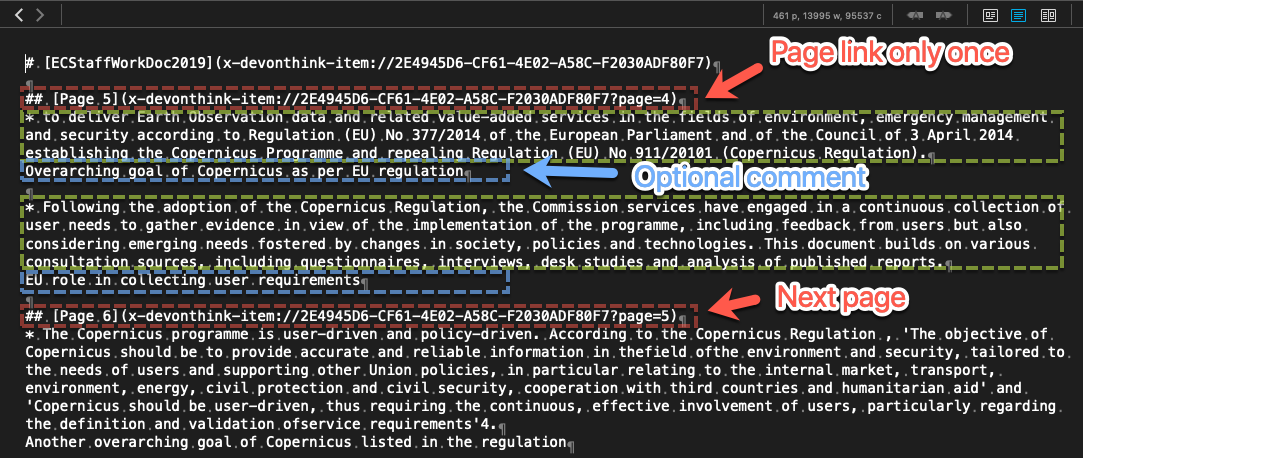
Some observations based on this:
- You will see that the page reference (red) is only generated once per page even if there are more than one highlighted text areas on that page. The Highlights app also has this feature. If you want to create a TB note for each text element (green) and want to reference the source page then you will need to repeat the page reference in the note attributes e.g. applying Explode twice or working with regexes somehow.
- For a given DT highlight you have in principle three sources of information (the third is optional). 1) The Page and Doc reference (red), the highlighted text (green) and an optional user typed comment (Blue).
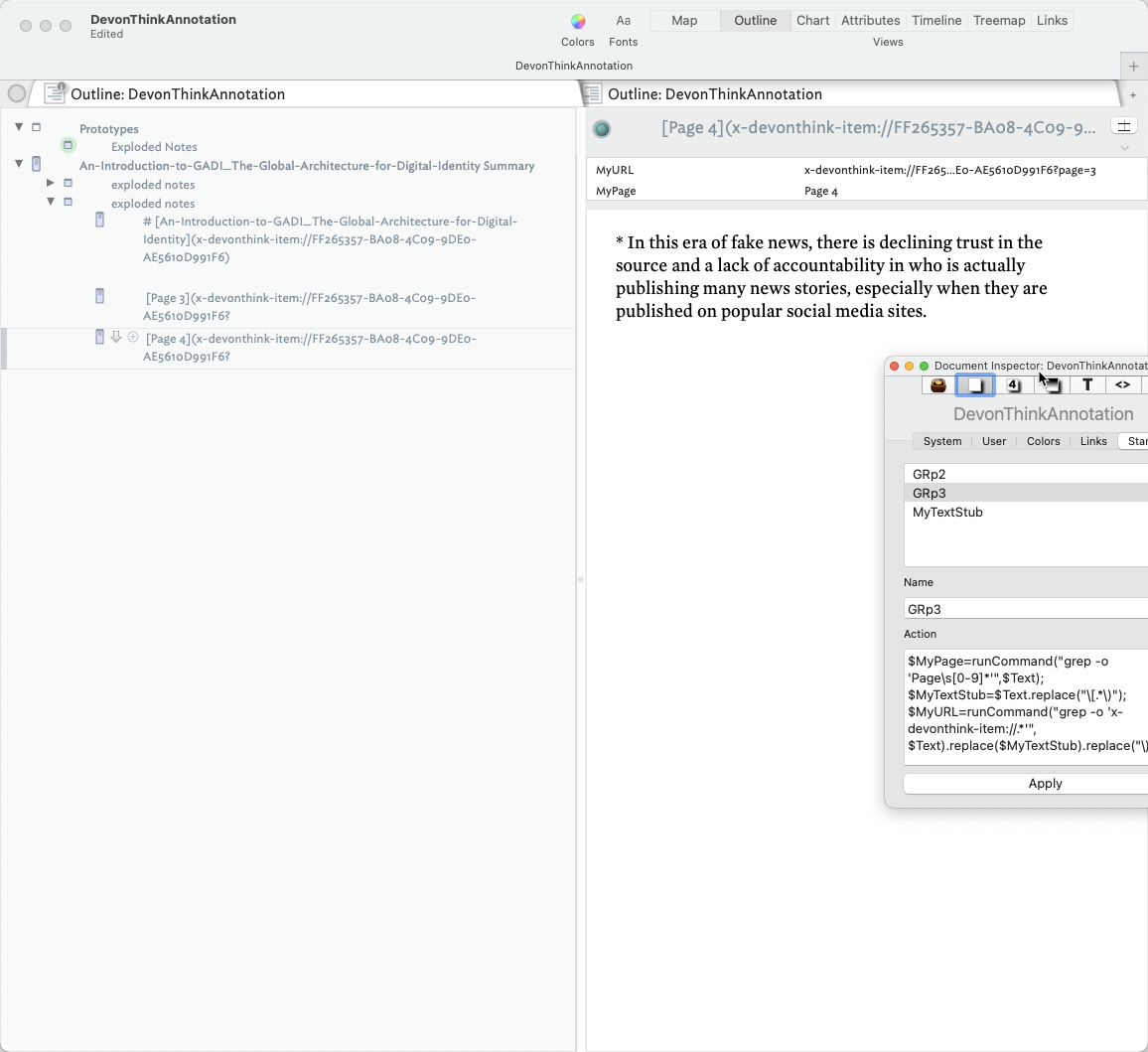
Missing in your post was your ideas regarding the naming of the TB notes. In my case I decided to apply the following mapping:
Page and Doc URL -> $DTURL (my user defined attribute)
Highlighted Text -> $Text
User Comment -> $Name
My DT Comment usually is chosen so I know roughly what the text is about. This has served me well (I had over 200 highlighted passages from the document in question).
The reason I use Summarise Highlights to RTF is mainly because the RTF file repeats the page reference so that each Highlight contains all three information sources (if I provide a comment which I usually do) as you can see below for the same original highlighted PDF document.

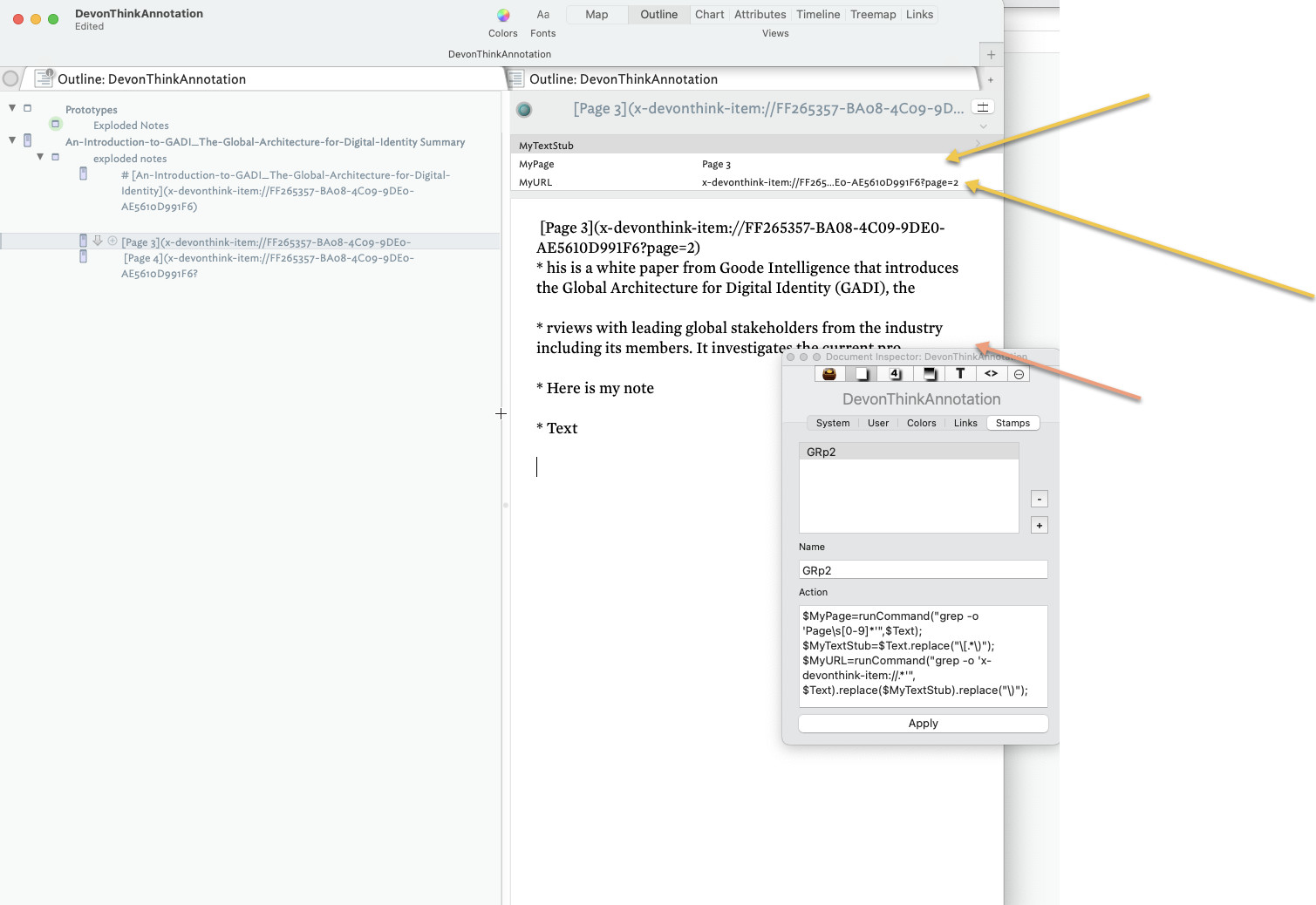
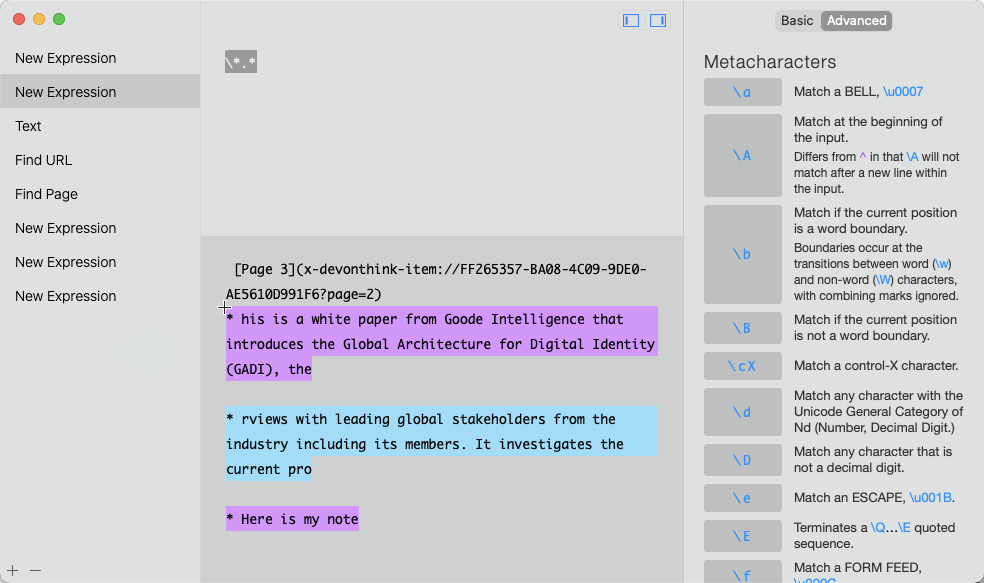
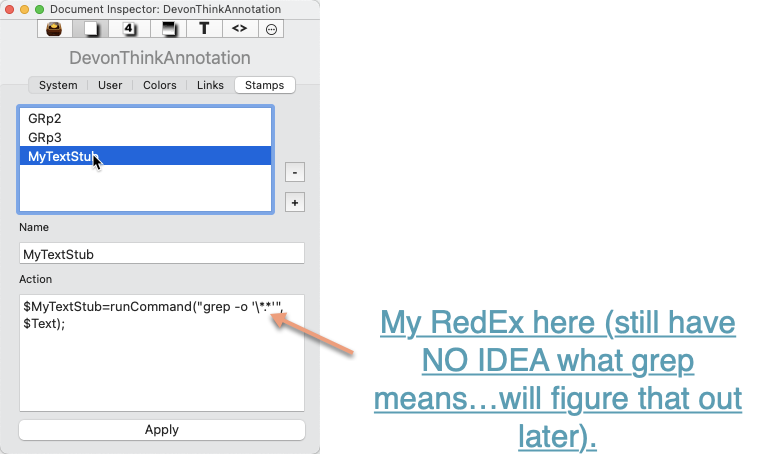
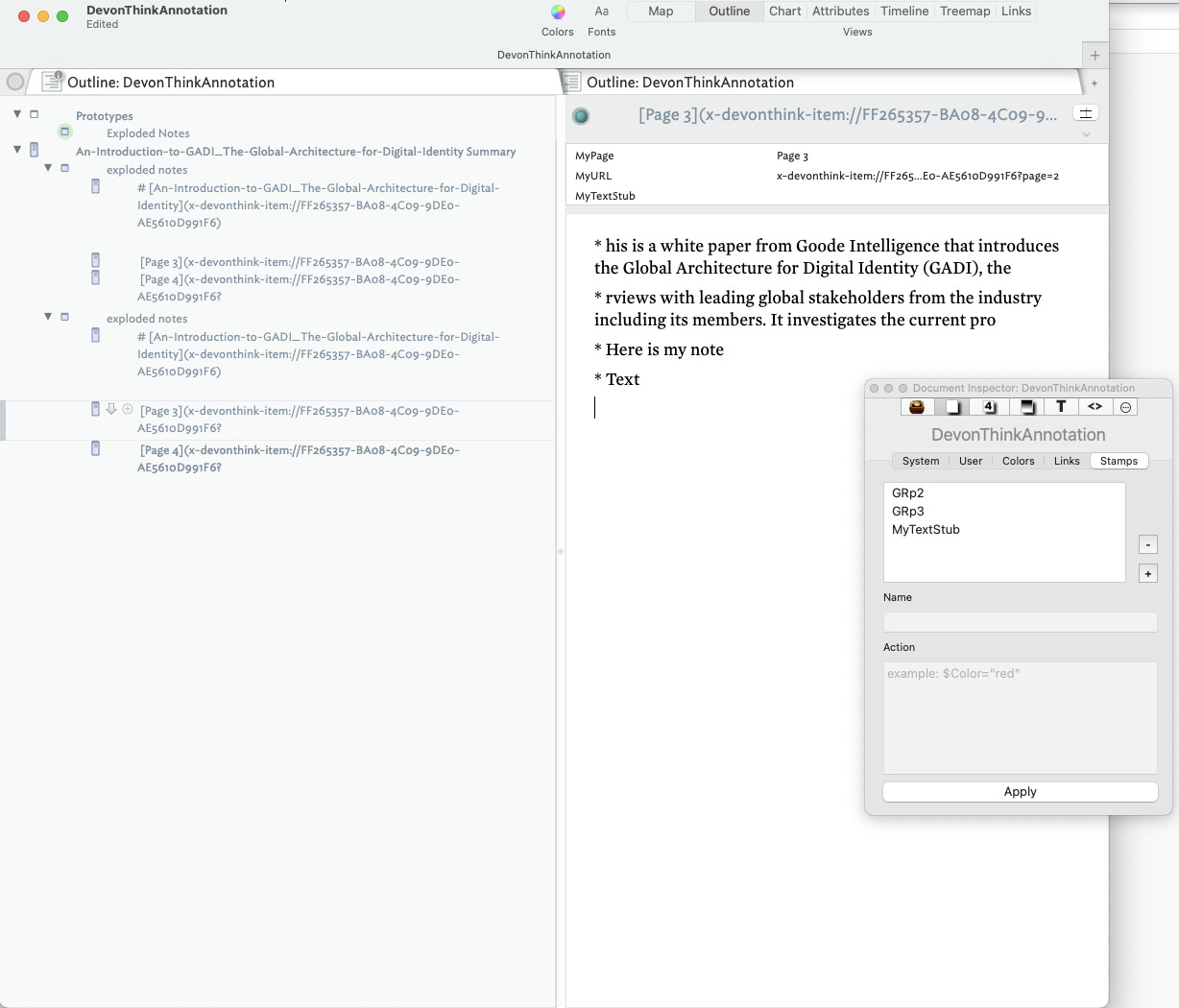
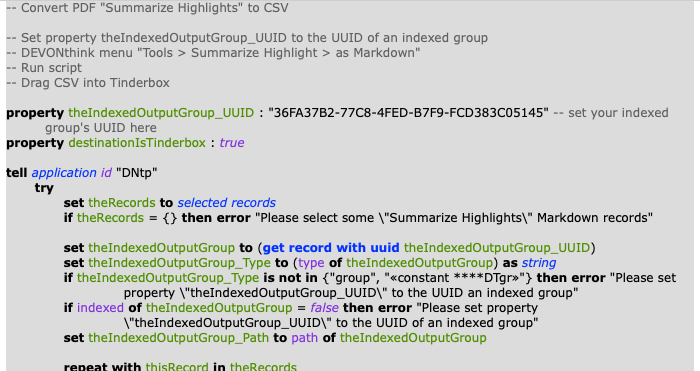
 Thanks. Tried the script above and I got super close. The Page and URL are being pulled perfectly, but the $Text body is not; ideally, the page and URL references would be removed and only the text would remain.
Thanks. Tried the script above and I got super close. The Page and URL are being pulled perfectly, but the $Text body is not; ideally, the page and URL references would be removed and only the text would remain.