I think this should be easy, but I have forgotten the exact syntax:
I have a group of notes whose $Name field is book titles.
About half the titles are entered with an opening “The” – “The Age of Reform,” etc – and about half have no initial “The,” as in “Pilgrim’s Progress.”
I would like to sort all the titles alphabetically as if the initial THE were not there.
This would be easier if they were entered in the form of “Age of Reform, The” – but they’re not.
I don’t see a built-in function that does this kind of “The-agnostic” sort, so I am wondering how to structure a rule or query.
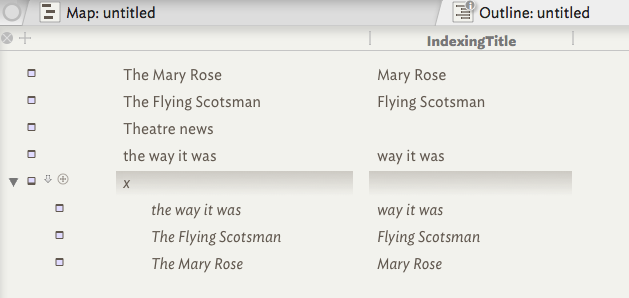
I think I need a new field called something like $IndexingTitle, and I need some transformation rule that will:
Search for notes whose $Name begins “The”;
For those notes, set $IndexingTitle to the equivalent of $Name-“The” or “$Name minus its first four characters”; [I’m aware that these quotes are being auto-transformed into curly quotes – let’s ignore that for now.]
For other notes, set $IndexingTitle=$Name.
I don’t know the right way to set the query – for notes whose names begin with a certain string, nor the way to set the rule or action, to remove that four-character initial string. Would welcome guidance, and asking “in public” for shared-education purposes.
So we’re 4 test cases: 2 starting “The”, 1 with "the"and a deliberate potential false positive. THe agent ‘x’ has the query:
$Name.icontains("^The ")
We use .icontains() for a case insensitive match of 'the ’ or 'The '. The ^ symbol in regex terms says match from the start of the string. WE also include a space in the match so things like ‘Theatre’ don’t make an unintended match.
Now the action:
$IndexingTitle=$Name.replace("^[T|t]he ","");
Only matching notes will have this action applied and an $IndexingTitle created. As .replace() works case sensitively we need a slightly different regex pattern: from the start of $Name ^ match either a ‘T’ or a ‘t’ `[T|t] character once followed by "he ". If that patter is found replace it with noting (i.e. delete it) and put the resulting string into $IndexingTitle.
Perfecto, thanks! I had not been familiar enough with ^ to remember that it’s the way to specify the start of a string for a matching query, and the $Name.replace operation is just what I was looking for too.
Also, I’m setting up my query with an else{ } provision to set $IndexingTitle to the same as $Name, if there’s not a match on initial-The.
Yes, for occasional use as ‘^’ is most normally seen in Tinderbox relating to export code. Likewise ‘$’ is used in relationship to attribute value references. It is also how you’d match the end of a string. If you wanted to find titles ending in ‘ment’:
After running the items through this process, I realize that I need another one, for titles that begin with “A” or “An”, as with An American Tragedy. But now I know how to set those up!
Just to extend the mutual-education exchange here, this is the way I ended up arranging the system. I mention it for an example to anyone who knows less about the program than I do, and for guidance and improvement from those who know more!
I added the string attribute $IndexingTitle to the main prototype. I also created a Boolean attribute $UnusualTitle.
I created an agent to find all the notes with “unusual” titles, beginning with A, An, or The. (The query asked for notes with the proper prototype and with one of the three initial strings. $Prototype=="Book"&($Name.icontains("^The ")|$Name.icontains("^An ") | $Name.icontains("^A "))
The action for that agent is to set $UnusualName to true (for reasons mentioned in the next step); and then to go through a series of transformations, separated by semicolons: $UnusualTitle=true;if($Name.icontains("^The ")) {$IndexingTitle=$Name.replace("^[T|t]he ","")};if($Name.icontains("^An ")) {$IndexingTitle=$Name.replace("^[A|a]n ","")};if($Name.icontains("^A ")) {$IndexingTitle=$Name.replace("^[A|a] ","")};
I suppose if some book had a title like “A The An Oddly Name Book” I could get into some kind of loop, but I’m not worried about that. Note that there are no "else{}"s in this sequence.
Then I have another agent, which looks for notes that don’t have the unusual titles. Its query is simply $Prototype=="Book"&!$UnusualTitle. And its action is simply $IndexingTitle=$Name, filling that field with the regular title of the book.
The two lessons of past seminars I’m applying here, and on which I ask the experts’ assent or dissent, are:
I’m having the system do this work via agents, rather than rules or edicts, on the theory that this is the cleaner approach. There are no other rules at work in the file; it’s all these two agents.
I’m separating the work into two agents – one to recognize odd titles, do the conversions, and flag them as odd, and the other to handle the non-odd regular titles – because that just seemed easier than trying to construct and debug a multi-conditional if {}/ else {} formulation for a single all-purpose agent (or edict or rule). I have a clearer sense of which gear is moving what part of the transmission this way.
Also, once the syntax was pointed out, it just took about two minutes to set this up, by cutting and pasting the complex-looking queries and actions, and it’s now handling a very large list. Thanks for the counsel!
because that just seemed easier than trying to construct and debug a multi-conditional if {}/ else {} formulation…
I heartily agree. Complex conditions are fine when there’s no good alternative, but it’s almost always better to have several simple agents than one terribly-complicated agent.