I have been working with Tinderbox for some time and am now trying to push it further. I am using it to collect an extensive collection including books and items. What I would like to do is aggregate all items and books using agents. For example, if I have an author/creator of a book and physical item one of the attributes is $Name. I have a prototype ($Person) and would like to make this into an agent so all of the books and items would be ‘collected’ within each person.
I have a question and then would like to push this further.
The question is, is it possible to convert a ‘note’ into an agent?
If this is possible and recommended, here is the rub and how I am trying to push this a little but further. Although each $Person has a $Name attribute, it also has an attribute, $AKA, which is a set. I would like each of the $Person notes to ‘collect’ all books/items that have either $Name or any other names (also known as) in the notes for book/item.
I hope this question makes sense. For example, my collection has thousands of books and items in it and the $Name for a given artist might be Ed Mack, Eddie Mack, Edward Mack or E. Mack. I would like to have one single $Person note with $Name = Edward Mack, and the $AKA attribute as a set which includes all of the other names that have been used to label the various items/books in my collection (I want to keep the item/book names consistent with the actual name/spelling on the item/book within their respective notes).
Can anyone let me know if this is 1) possible using agents and 2) worth setting up my Tinderbox document this way.
In short. ‘No’. Actually, in this sort of scenario, agents aren’t the way to go. Rather, use edicts which are rules that run less intensively so you don’t cane performance. Like rules, edicts are action code run by a note on itself. The edict code ($Edict) can be generic and thus set via a prototype. Getting every item (note) to find mentions of itself of itself doesn’t scale well; I say this from experience with files with 0,000s of items. Edicts are the least intensive method of doing this and I’d recommend that if using on 00s of notes that you design your code so it only runs if the $EdictDisabled isn’t set in the prototype - i.e. turning off the prototype edict you do the same for all notes using it.
If you haven’t yet tried out Attribute Browser view, I’d do so as that might answer some of your issues.
Normalising author names is a chore. For things like books by all means store the author name as published but also store separately the canonical name you’ve chosen for that author and do all your querying/linking on the latter to ensure lack of ambiguity. Thus a person note would use the author’s canonical name as the note’s title and query book/film/etc notes based on their stored canonical author name(s) as opposed to the as-published variant. This is important as authors may be multiple and are therefore a list-based attribute, in your case a Set.
As Sets and Lists can only query-match via .contains() based on using complete values - i.e. not particle name matches) have the same author name in both a person and the book they wrote is an important step towards your task.
What’s not clear is how you intend to ‘collect’ the eventual data in the person-type note. As the $Text? As another list? As a set of links? Any suggestions here need clarity as what you want to do with the info. Read it (i.e. needs to be presented in a readable form, such as $Text)? Analyse it for further info such as counts of occurrence? do thing? …etc.
If you’re committed to agents, don’t make an agent pr note, for performance reasons above. However you could make a note whose query and action used attribute values drawn from the agent. For example instead of hard-coding a person name into the query, set a key attribute in the agent to an attribute listing all the person notes. Thus you might use $MyString to store those values and then query for CanonicalNameSet==$MyString(agent). Any note whose (user) Set-type attribute of canonical author name(s) matches the name currently set in the agent’s $MyString will return a match.
In summary, there’s lots of detail above. Don’t try and understand it all at once. I’d recommend making a test file or copy of your work thus far with the bulk of the detail stripped out so you can test the ideas above. Avoid the temptation to test complex and CPU-intensive actions you don’t yet fully understand on your whole dataset. It makes things slower and takes longer to figure out when things go wrong.
HTH and do follow up on the specifics of the above that don’t yet make sense.
Let me underscore (among his other tips, as well) this recommendation by Mark A. as a possibly useful avenue. Also you’ll find a lot more discussion and illustrations of the attribute browser in this thread.
For me the value of this feature, which came into TB a couple of years ago, is that it automates something that otherwise would require setting up a lot of agents or doing other detail work. That is: it automatically groups and displays notes by any attribute you specify, and it can fine-tune the display in ways that may approximate part of what you’re looking for. Without getting into a million details, I think if you look through both Mark A’s tutorial and this parallel thread you may find some approaches that are useful for you.
In a train to Paris this afternoon, I was rereading some pages of Umberto Eco’s work Come si fa una tesi di laurea (How to make a doctoral thesis) when I saw that the index cards he used for his own thesis were full of underlined words. And I was wondering/dreaming : if Eco had been able to use Tinderbox, what would he have thinking about the Attribute Browser, which does exactly the work he made using handmade index cards?
There was some Eco work in the early 90s on hypertext and timelines. I wasn’t a big fan – for such an adventurous thinker, this was a pretty staid approach – but he was certainly interested in this sort of approach. And of course his contributions to Theory had a big influence on the study of hypertext rhetoric.
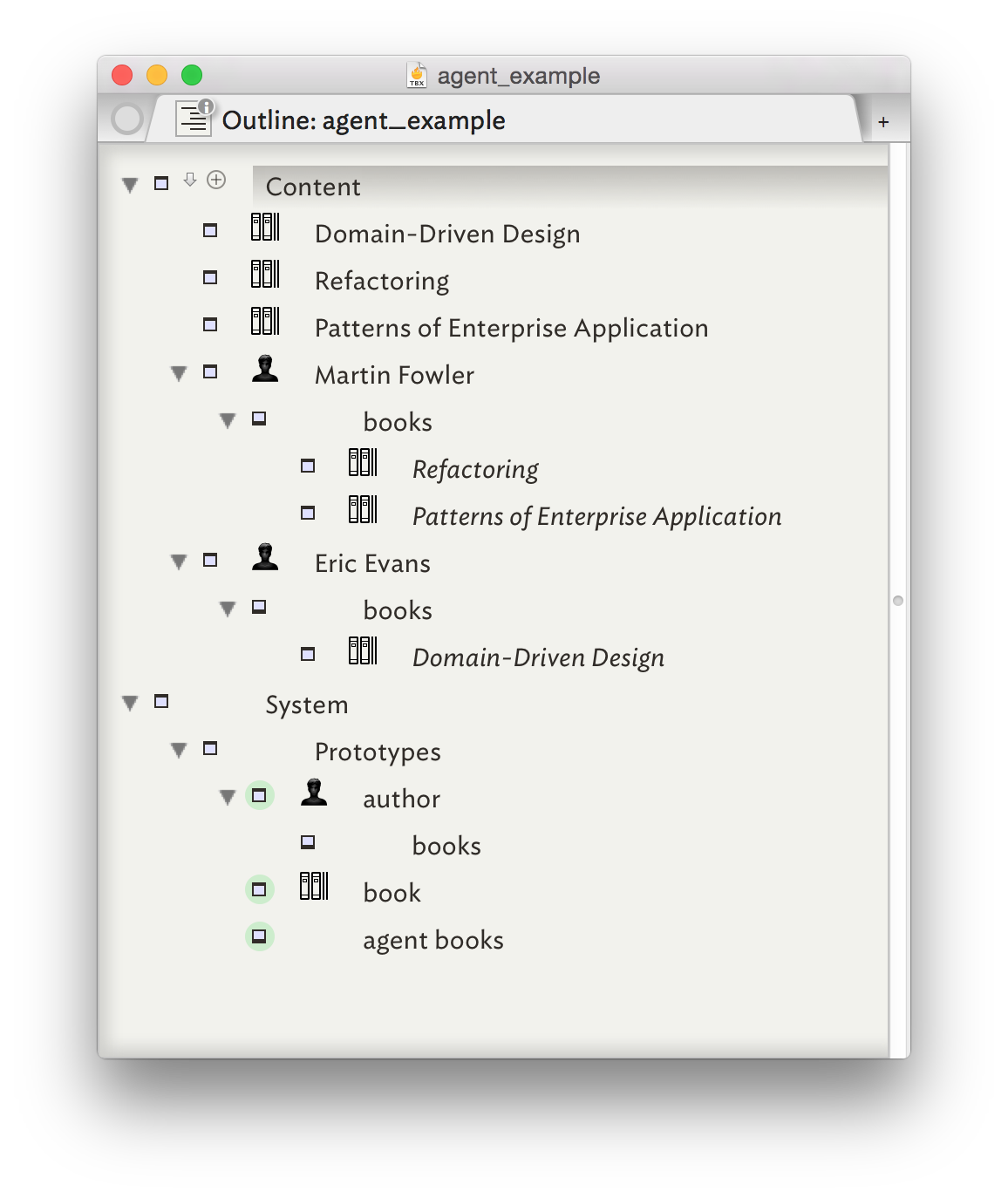
Here’s an idea you can try… make an agent which references its parent to look up the name. Then put that agent in a prototype. When you assign the prototype to a note, the prototype will bequeath its children to the note.
The agent itself uses a prototype so you can update the prototype and it should update all the agents that inherit from it.
To bequeath the children, simply set the prototype of an author note to “author” (you may need to unset it). If the author note already has children, you can create an agent as a child of the author note and set its prototype to “agent books”.
Caveats: I haven’t tested this exhaustively, and have no idea how it scales
In thinking of scale, I looked at one of my research files and just part of the file is around 1.3k notes on individual books/papers with around 2.1k discrete authors. The sort of rule or edict I was running might have code like this (in this case a rule):
Here the code links this item (an author note) to any note where the $Name of this note is matches any individual author of a note representing a paper. Anyway, notice how the outer condition makes sure the note’s main rule code (the potentially heavy duty stuff such as .contains() calls) is executed only if the prototype’s rule is enabled. The same code is excluded form actually running in the prototype itself.
Admittedly, each note still has an a Rule and if you look at the Agents & Rules Inspector you’l see the rule cycle indexing through - but fast as all codes are likely failing the ‘if’ test when the prototype rule is not enabled.
Anyway, far easier to manage than >2k agents and leaves the 10 or so agents still needed to run with less extraneous load. Also, each author note is now essentially acting as low priority agent but with less clutter on the outline.
Please don’t read this suggestion as a competitor to @pat’s neat suggestion above, but rather an alternative as things scale. Indeed, this might be overkill in a file with 100 or so notes in all. Tinderbox is very flexible for adding structure as you go or replacing existing structure. So, if you start out with a few agents and find you’re getting too many to handle, it’s really not too hard to migrate to a rule/edict model like this.
When this question first came up, I thought: I believe there is a way to use prototypes and rules to set up this kind of search. But I hadn’t ever used the .intersect operator so hadn’t thought of that as a way to get to the destination. Thanks for this clever solution, which points the way for me in dealing with some different issues I’d been wrestling with.
Also appreciate Mark A’s suggestion on how things change with increasing scale.
I remember a scholar who told us (I was still a student) that he had a thousand of hand-written index cards he reviewed regularly and that he found regularly a lot of similar notes about the same topic. His example was suicide: he had collected a lot of notes about suicide. We were in France at the beginnings of Internet and universities used the web to share some parts of their library. I wonder how that learned man could do that work nowadays with the Attribute Browser and $Tags. What would he discover if he would set an agent to search in his notes? Would he work otherwise than with his index cards?