We’re talking about different things here, so let me clarify: I’m not talking about map XY values, but rather plot XY values. In a Tinderbox xyplot, each of the notes contributes a single (x,y) pair to the plot.
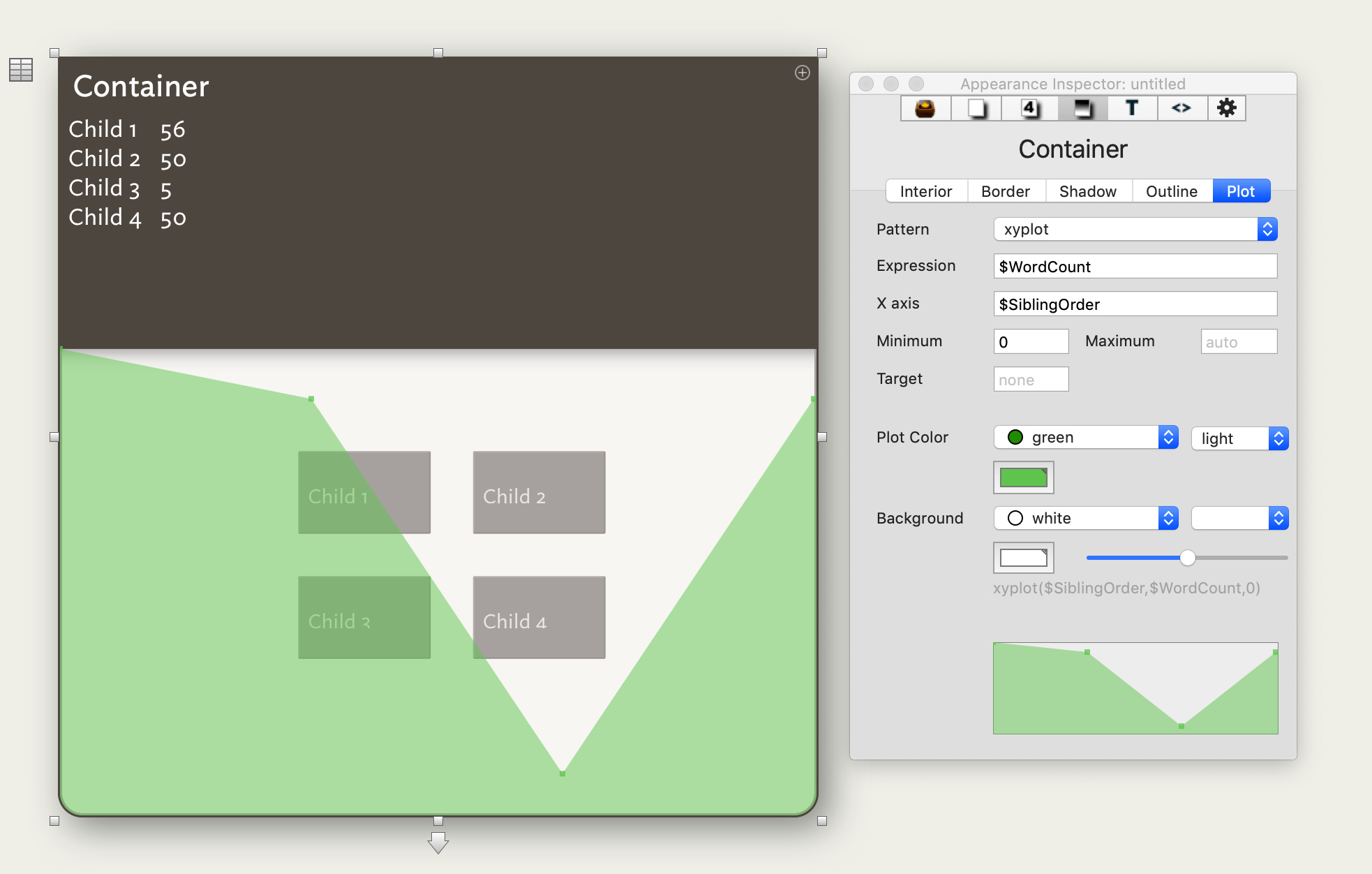
For example, here I have a container with 4 children. The y value for each child is its $WordCount, and the x value is $SiblingOrder. Here there is no aggregation required, because each note within a set has a unique value for $SiblingOrder. Note that this setup matches the behavior of the vanilla plot and bargraph commands, which also use $SiblingOrder for their x values.
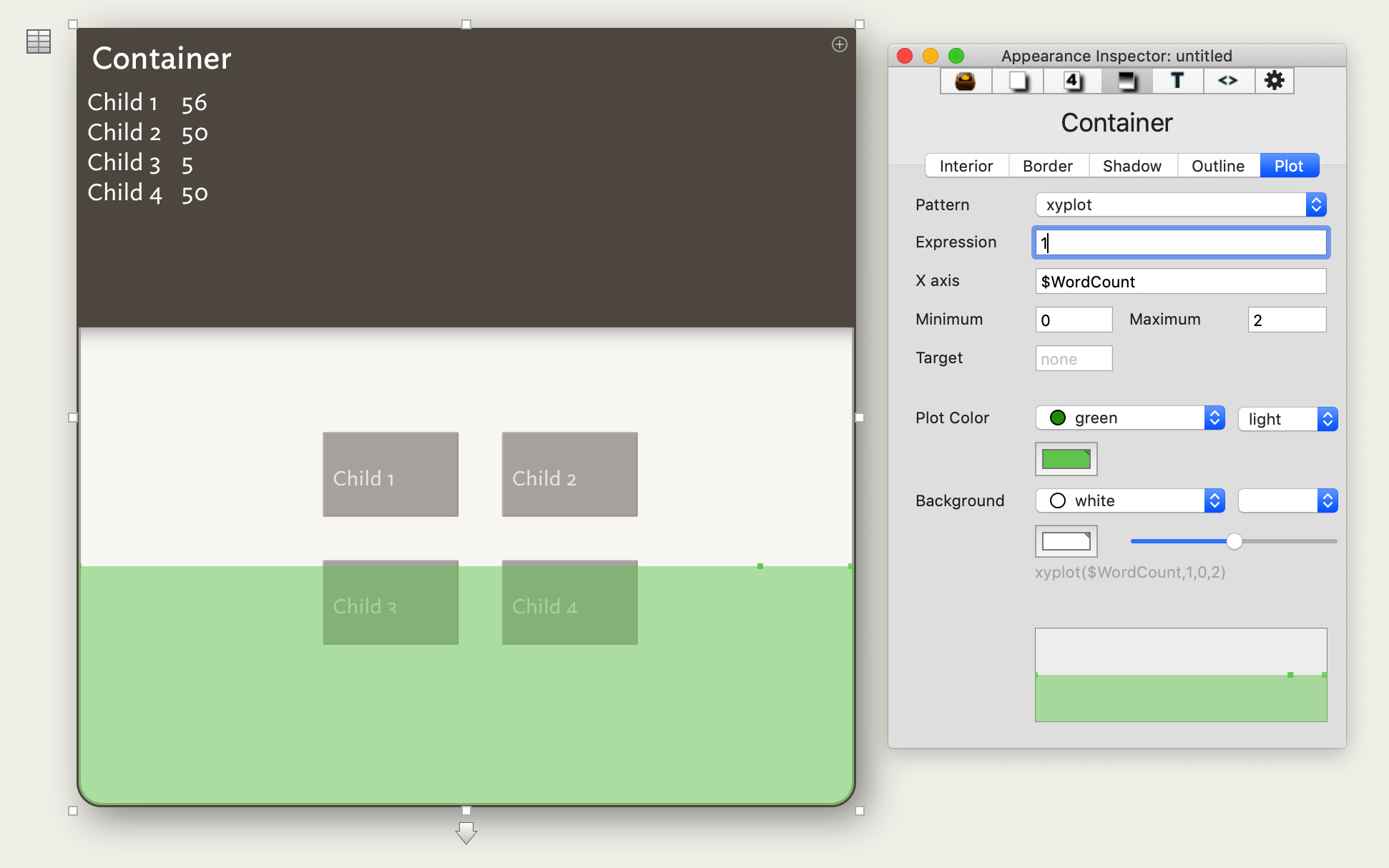
Now, what if we wanted a histogram of wordcounts instead? This would mean that the x value should now be $WordCount, and the y value should be the number of notes that have that wordcount. Setting the x value is easy; just plug in the correct attribute. But what about the y value? I think that 1 would be perfectly reasonable – after all, we just need a yes/no marker for whether a note falls on that x value – but this doesn’t work.
There are two issues here. First, Tinderbox does not aggregate the y values when notes are mapped to the same x location, so we don’t see any variation in the plot. The other is that it simply bridges the distance between the plotted points linearly. (The latter is fine, given that we used xyplot, but it does also hint that bargraph might benefit from an xybargraph version.)
Aggregation is a solved problem with a standard solution: you provide a reduction function which describes how to combine values. Such a function needs to take a set of values to a single representative value, and is called for each x in the plot with the set of values that mapped to that location (which may be the empty set). Consider how we would implement the histogram. We need to get the count of the notes for each x location, so we have each one contribute 1 to the set. Then we take the sum of all the 1s at each location (the sum of the empty set is 0). For my OP issue, where I want to see the issues resolved on each date, I would use $Date as the x value and do the same.
As another example, motivating more expressive operations, if we wanted to visualize entries in a lab notebook we may want to plot the mean of the note values along some axis.We would need a more complex reduction function which finds the sum of the values and divides by their number. Another view may plot the variance or standard deviation of the data, to help eyeball whether the results are significant.
Unfortunately Tinderbox doesn’t have a way for users to define their own functions. In Emacs, by comparison, sum would be trivial to implement as the lambda function (lambda (vals) (apply '+ vals)), as would mean: (lambda (vals) (/ (sum vals) (length vals)). Tinderbox action code would require another attribute to be bound during the execution of the reduction function so that the set of values could be referenced. (Perhaps $PlotYValues or something.)
Anyways, in the plotting case I think sum makes a pretty good default: it reveals when there are overlapping points and handles most cases pretty well. Adding more complex expressions is probably required if sum doesn’t get things right. Right now the behavior seems to be “pick arbitrarily” which is confusing, but also could be easy to implement as a reduction function.
I hope that clarifies things a bit!