Still learning tinderbox and am finding the aTBref guide incredibly useful. Unfortunately when I use the tinderbox format it seems to overload my memory (I have an old Macbook Air so this could be the issue).
Was just wondering if this documentation is in pdf form? The reason I ask is because I want to search the manual and the Google Search embedded in the online manual does not seem to work. I realise I can search through the site map but this only helps me find subheadings and not all the text within the documentation.
If not PDF, are there any other ways to search the document other than using hte underlying Tbx file?
PDF format, no. In theory, using the method to make the PDF version of TB Help. however, this TBX is more complex and it’s a project for which I just don’t have time at the moment.
The Google search is broken because of some bug in the Google indexing system which seems to think the site restricts googles bots, which it doesn’t, As the system is free, there is of course no help (or any use). If there’s anyone in the forum who’s expert in this stuff I’d love to correspond.
If you have the TBX, why not export it to you own Mac (don’t forget to download the images, in a separate zip file). Then you can use Spotlight to search the data.
If you export the source TBX document for aTbRef, you can use Acrobat to create a PDF from it. Use the “Create PDF from Web Page” option, and make sure you configure it to use the entire site. DO NOT USE THIS ON THE ONLINE PAGE – that will put a drag on Mark’s resources and is not polite.
The resulting PDF is paginated, with page bookmarks etc. Because the PDF is page-oriented and uses the paper size you specify (A4, Letter, etc.) it will NOT be faithful to the original website. PDFs of web pages are generally ugly – not the web page developer’s fault.
These processes – exporting aTbRef to a local folder, and creating a PDF from the contents, is very time and processor intensive. If your small machine already has issues with aTbRef then it will no doubt have greater issues with the export and convert-to-pdf processes.
FWIW, if you’re just reading the TBX, if all the agents have populated you can turn agent updates off (File menu) at which point the document uses a lot less CPU resource.
Personally, i’d like google to make their indexing work as advertised, but I’ll not hold my breath.
Will try turning agents off and if I still have an issue I’ll try create a PDF from the website (I have the full version of acrobat at work where I have a much better machine). I dont mind if the PDF comes out messy as I can simply use it to find what Im looking for from a search and then navigate back to the online version.
FWIW I attempted to create a PDF from a local export of the entire aTbRef-7 site using Acrobat DC Pro. Acrobat churned away for 10 hours, when I gave up and aborted the process after a several GB file had been produced. I’m on a very fast, top of line MacBook Pro with plenty of memory and disk, so the issue is not the machine. Nor is it an issue with the aTbRef export – it is an issue with Acrobat’s limitations.
OK folks try the added search at this page. at present I’ve just hacked the DDG search box into one page.
It seems to work. Sadly, there seems no way to tell DDG embedded search to show results in a new window/tab. so if you get no useful results you’ll need to use the back button. Still, small beer I guess if it does at least give search results - which is the main background to this.
@mwra When it comes to Google not listing your pages, maybe you’ve already tried this, but I suggest creating a Google Search Console property for your site, and diagnosing from there. Google Search Console allows you to interface with Google, and see how it sees (or doesn’t see) your site.
Make sure you have a Google account. I think a Gmail email address is enough.
Create a “property” for http://www.acrobatfaq.com/ (side-note: it would be nice to have Tinderbox documentation at a dedicated domain.)
Go through the short steps to “verify” your property. This usually involves putting a snippet of HTML on your server.
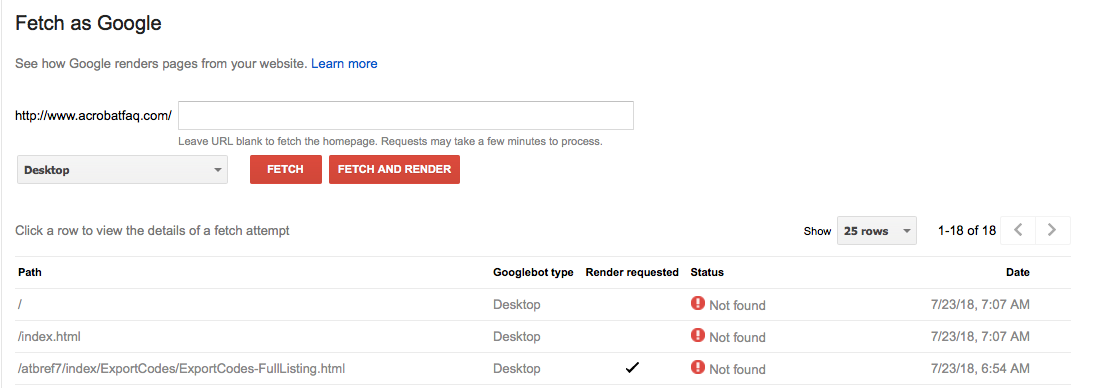
Once Google has verified you as the owner of the site, you can fetch your site “as Googlebot” and see what message you get back; you can submit your pages for indexing.
Well, I have a Search console set-up. First it said the site was failing validation, now it says it’s passing, but only finds 4 files. The documentation is unhelpful as the error messages are so opaque. As the robots.txt for acrobatfaq.com is:
User-agent: *
Disallow:
It’s accessible here http://www.acrobatfaq.com/robots.txt (and has correct permissions, 644) so Google should have no problem accessing it. But if there’s a bug in Google’s system there’s not much I can do about it. I’ve tried accessing acrobatfaq ‘as google’ via the search console but it resolutely says it’s inaccessible. Grr.
I do have the domain atbref.com and it points to the index page of the current (i.e. v7). As there are a numerous of inbound links to the earlier copies I’ve endeavoured not to make too many links fail.
Anyhow, all the Tinderbox content on acrobatfaq.com is my own work which grew out of sharing some of my personal notes as I learned the app back in 2004 and has grown since then.
@mwra It looks like you’ve already done what you could with Search Console. Your robots.txt is totally accessible as it should be, no problem there.
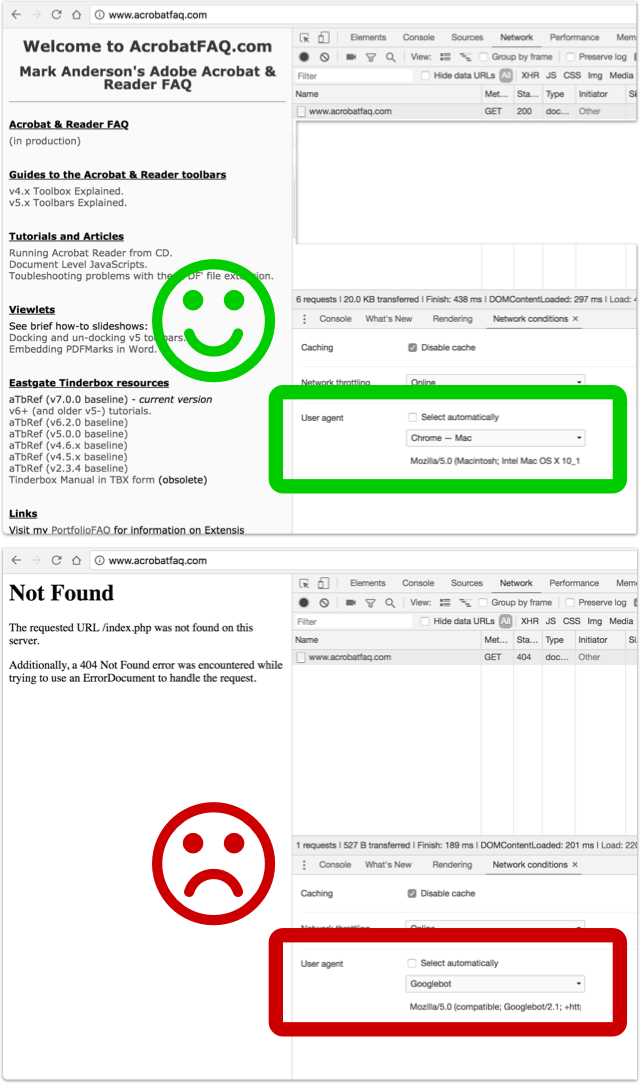
I suspect there’s something off on the server itself that’s blocking requests that have “Googlebot” as a useragent string… I say that because in the attached screenshot, you can see (1) your homepage fetched just fine with the default “Chrome Mac” useragent string, but (2) returning a 404 when I switch to “Googlebot”. What exactly is doing that on the server is beyond me (I’m not a server admin), but might be something security-related like a firewall or request-limiter.
Good luck, and thanks for all the work you’ve done making the reference available to the public!