I’ve gone in fits and starts with TBX for a few years and just starting to feel like i have a handle on things when …
On importing a .txt file, TBX seems to have “auto-exploded” the note, without any command from me (i.e. I’m not toggling the “Explode” command). This results in breaking the .txt file into a new note at each line break, using each newly created line (in full) as the Title (rather than the Text) of the newly-created note, each of these notes now preserved under a parent note bearing the Title of the original filename. This preserves the content of my original note - but makes it pretty unwieldy.
Have i inadvertently toggled “ON” the note exploder? Is there some way i can turn-off this “auto-explosion”? Or can I parse differently the note contents? For instance, if i import a filename Jia.txt, might TBX parse the newly created notes as Title=Jia1, Jia2, Jia3…, with my highlights inserted in the Text of each new note?
I’m doing a review of the technical literature. The .txt file is created by exporting text highlighted in a technical article.
There is no auto-explode but if Tinderbox detects (what appears to be) tabular information it will attempt to parse the CSV or tab-delimited records therein into per-record notes: see more. That’s a best guess, without seeing the file.
Regardless if the dropped file is splitting into notes, I suggest you just make a new note and copy/paste the contents - or use a different tabulation in the source file.
Given that i was working with a simple text file, i wasn’t sure how to modify tabulation (copy’n’paste of < 12 notes would’ve been a pain). But your suggestion did lead to a resolution.
In my original file (of captured highlights), the initial lines read (the full journal reference):
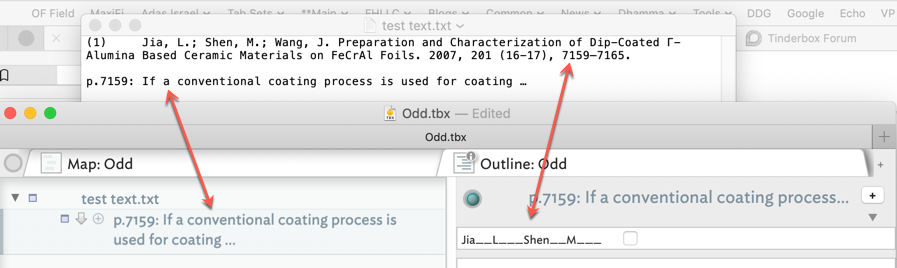
"(1) Jia, L.; Shen, M.; Wang, J. Preparation and Characterization of Dip-Coated Γ-Alumina Based Ceramic Materials on FeCrAl Foils. 2007, 201 (16-17), 7159–7165.
p.7159: If a conventional coating process is used for coating …"
I first tried stripping out the double-return separating “7159-7155” (the journal pages) from “p. 7159: If a conventional …”, to no avail.
But stripping out the leading “(1)” before “Jia” did the trick. That leading numeric must’ve triggered the “exploding”.
Note that the first line, without the “(1)” and tab, becomes the name of an new attribute, and the second line the name of a note. Strange.
But, I am not sure if it has to do with the “(1)”. This text does not behave the same way as the text @gfholland provided. There’s something else causing the parsing error.