I’m facing the same challenge as @dominiquerenauld, to whit to import the the file output through the Summarize Highlights in Devonthink v3. In this case there are 210 notes and I do this quite often so I’ve spent more time how to streamline the process. I share my solution as it could be useful for other TB users who also store and highlight their documents in DevonThink:
- Generate a Summarize Highlights output file in DevonThink selecting the RTF output option
- Run the AppleScript found under the following DT community thread to convert the RTF links into their URL equivalents e.g. spell out the links
- Create a blank TB file and a single note to serve as the basis for the import
- Select and copy the RTF text (with URLs) into the $Text field of the TB note. This serves as the basis for the import and helps me get around the automatic import mechanism for TB.
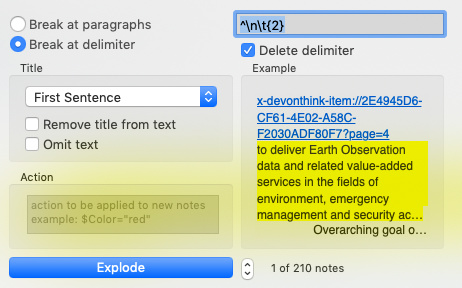
- Apply the TB Explode function to the note using the following settings to generate a single TB note for each highlight
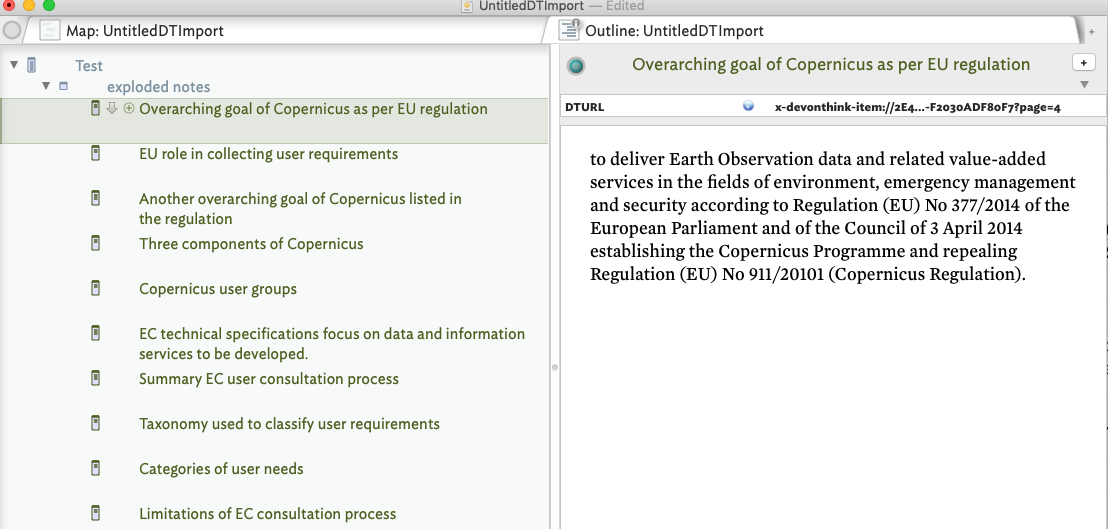
NB: the structure of a DT3 Summarise Highlight file uses a Return to identify each highlight and 2 tabs to identify the link to the PDF file/page, the highlighted text and (optional) the user defined comment for each highlight. See the example below which includes 1) the URL link in blue, 2) the highlighted text from the PDF file and 3) my comment. The 2nd link at the bottom belongs to the next highlight but is included to provide the overall structure of the file.

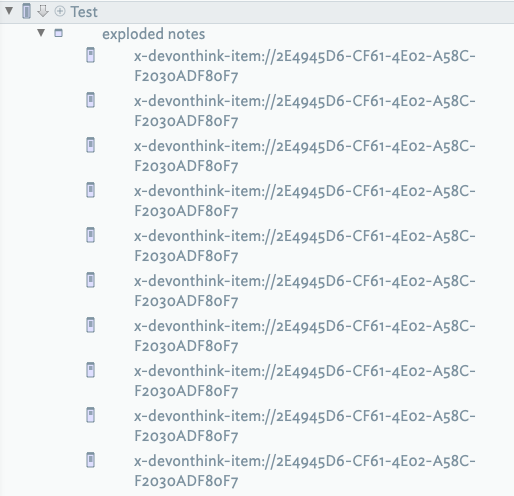
If all goes well you should have exploded notes that look something like the screenshot below with each note title given by the link to the corresponding page in the Devonthink PDF document.
- My goals is now transform all of the imported notes into the structure that allows me to analyse their content within TB. Specifically I want to 1) Extract and store the link in my own key attribute $DTURL, 2) Set the $Name of the note with my comment text and 3) set $Text to the quoted text from the PDF document. For this I use the Stamp code below applied to each of the exploded notes. NB: For the case where I’ve highlighted text in the PDF file but not provided my own comment about the highlight there will be only two elements to deal with, the text and DT link. Here I simply set the $Name to the highlighted text.
$MyList=$Text.replace(“;”,“\;”).split(“\t{2}”);
if($MyList.size==3){$DTURL=$MyList.at(0);$Text=$MyList.at(1);$Name=$MyList.at(2);};
if($MyList.size==2){$DTURL=$MyList.at(0);$Name=$MyList.at(1);$Text=“”;};
The final result looks something like the screenshot below with all notes now properly labelled and containing a link back to the original highlight in the PDF file stored in DevonThink. From there on I can analyse within Tinderbox and make sense of the notes in the usual way.