Yea, fairly straightforward question. Publicly available XML file that I want to get into TBX somehow:
XML NIST SP 800-53 Controls (Appendix F and G)
Any ideas?
Yea, fairly straightforward question. Publicly available XML file that I want to get into TBX somehow:
XML NIST SP 800-53 Controls (Appendix F and G)
Any ideas?
Is the tab-delimited version at this page the same content?
Tinderbox imports tab delimited content.
Yes it’s the same content. Just drag 'n drop then?
In the majority of cases Tinderbox import involves drag-drop or blind-pasting into the view pane. this can be initially confusing as it means there is no menu indicating how this occurs. File → Open is generally intended for opening TBX files. To start a new file based on existing external data, make a new Tinderbox file and then drag-drop the data file into it.
For more on importing Tab-delimited (or CSV) data, including considerations about attribute auto-detection and naming, see here and here.
Not directly. I worked with that file you said was the correct content and found:
My point is that it is strongly recommended when working with internet data sources that you first examine the data (e.g., in Excel or Numbers, etc.) to see if it needs cleansing before importing. It is frequently the case that it is a lot easier to fix data in Excel before a bulk import into Tinderbox than it is to slog though thousands of notes determining what’s wrong. Here, if you had imported the file directly you would have had hundreds of notes with missing values for attributes.
This ^^^^^^^ - yes!
Some data cleaning is often required. Actually, unless you are making the data yourself and understand the workflow & tools it’s usually required . To those of us used to such annoying but necessary steps, it’s easily overlooked.
Note to self, check aTbRef notes on TSV/CSV import and properly reflect this aspect for those less used to it. CSV, less so TSV, is a very variable ‘standard’. Lots of tools/apps do this structure differently, i.e. dealing with (or not) commas/tabs/line returns within ‘cell’ data within the overall TSV/CSV table.
So great, Paul, thank you!!
Just to make I sure I get it: xml-files can’t be imported by drag and drop!?
One has to do some steps in between … which, to be honest, I still don’t understand according to what I read here.
Any suggestion for easy digestion?
Drag a Tinderbox .tbx file into another Tinderbox document. See what happens? You just dragged an XML file into Tinderbox. Tinderbox did nothing except create a note with the name of the file and no content.
Open an XML file (or .tbx file) with TextEdit. You’ll see a structure that is easily read in plain text, but that also relies on either the application that created it, or on a custom routine to parse it. Either way, other than Tinderbox opening .tbx files in the normal way – someone else’s XML creation is not something that Tinderbox has a clue about if the data are dragged into Tinderbox.
XML files can represent all sorts of things: bank transfers, places on a Google Map, entries in Books In Print, software configurations, ancient manuscripts, Tinderbox needs to know how you’d like to map a specific XML file onto Tinderbox’s own constructs.
Some specific XML formats – OPML, Tinderbox color schemes – are imported to Tinderbox often, and Tinderbox handles them more or less automatically. In other cases, you’ll need to transform the XML into a Tinderbox file, or into another familiar format.
Of course, if your workflow depends on an XML format that you think has general interest, we’d love to know about it; we may well be able to support it directly.
I think one that could be interesting and perhaps useful would be to have wordpress export files (wxr, a type of xml). transform the posts, pages, various custome post types into notes with attributes…
Any interest in supporting an import of Pubmed XML data for medical citations?
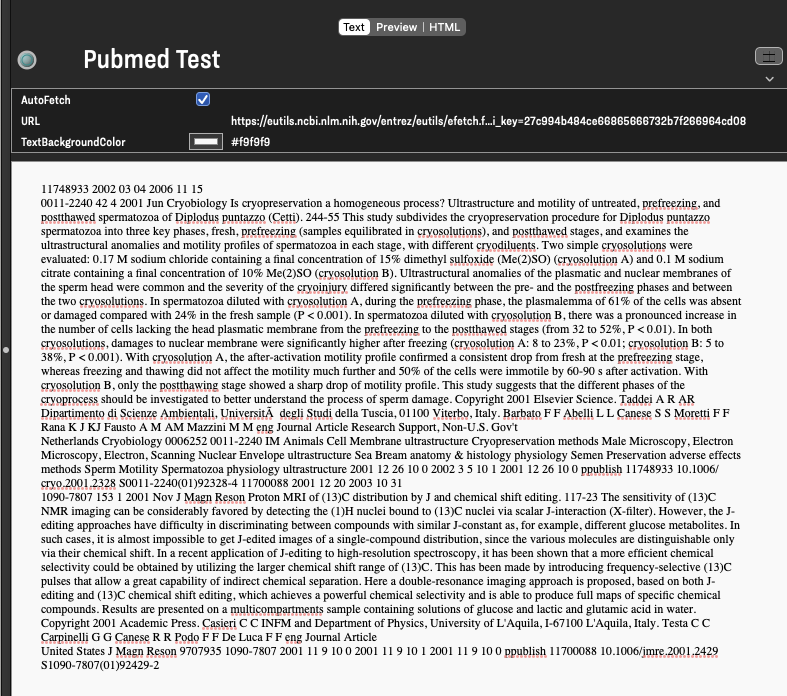
Here is an example of a search output which gives output in XML format:
I tried setting up an AutoFetch as per one of your other posts; that only imported one of the citations and did not import any of the field as Attributes.
What would be involved in parsing this data so the various XML fields become Attributes?
How well does Tinderbox scale, i.e. how many citations of this sort would reduce Tinderbox performance to not be practical?
Tinderbox works best with hundred or thousands of notes. Its visualization tools will have lost traction with hundreds of thousands or millions of notes.
ok thanks
Can I enter multiple paragraphs as an attribute? How do I handle the CR or Enter?
You can – but it’s probably not a good idea. (You can paste text with paragraphs into a string attribute, or transfer the text of a note to an attribute.)
Most of the things you’d typically do with attributes benefit from short, specific values. But there are exceptions; for example, when importing references from RIS, the raw RIS is stored in $ReferenceRIS.
To go back to an earlier question, we could certainly import PubMed if there’s call for it.
That would be great - I’d be glad to help beta test as you bounce off ideas on how to implement it
If I import Pubmed data (or any other academic citations) and would like to attach some textual analysis/commentary, is there anywhere you would suggest other than $TEXT?
A common annotation idiom used in Tinderbox would be to place the annotations in the same notes and link those to the PubMed reference be it in Tinderbox or in something like DEVONthink (you can link direct to items in DEVONthink).
A say this as the only attribute you can read other than in a small value box is the note text. Also while you can import lots of data into a note, big notes (i.e. ++ paper pages of text) load more slowly (more to render) so switching notes is slower.
Given that do you need the PubMed docs to actually be in Tinderbox document or are you assuming so in order that the notes and the source are connected.
There’s no ‘must’ here, but generally source documents, e.g. PDFs of academic papers, are stored outside Tinderbox and accessed via links to DEVONthink, Bookends, or the like; or, by using Finder via direct links to the papers on your hard drive.
It is worth stepping back an assessing what must be done in a particular way and why (e.g.: why must the PDFs be in the doc?) vs what assumed to be necessary. This helps surface assumptions and allows the unverified ones to be tested against the intended workflow tools. There’s no failure in doing so; indeed, it often helps clarify the process and avoid diving in and just hoping all the assumptions hold true.
That is good advice - thanks
I agree that storing the PDFs in Tinderbox would be excessive for multiple reasons.
I do want to store the abstracts in Tinderbox however - that is necessary so that I can create Agents to act on the citations.
Bookends does a good job now of importing citations including abstracts and Zotero can do so somewhat less elegantly. But neither imports the full metadata. In particular it would be nice to bring over the MESH categories which PubMed/National Library of Medicine use for searching/categorizing citations as well as the metadata for articles cited and article cited by. That info is all in the full Pubmed XML data, which can be retrieved programmatically by a URL with search parameters. If we can import and unpack that XML metadata into Tinderbox by referencing such a URL, it would be quite helpful for anyone using Tinderbox for medically related projects.