I have a couple of notes that manage informations about books. Each book has an author.
Now I’m looking for an agent that shows me a list of authors who have written more than one book.
This list should also show the number of books one author wrote.
Is there somebody with an idea to manage this task?
Helmut
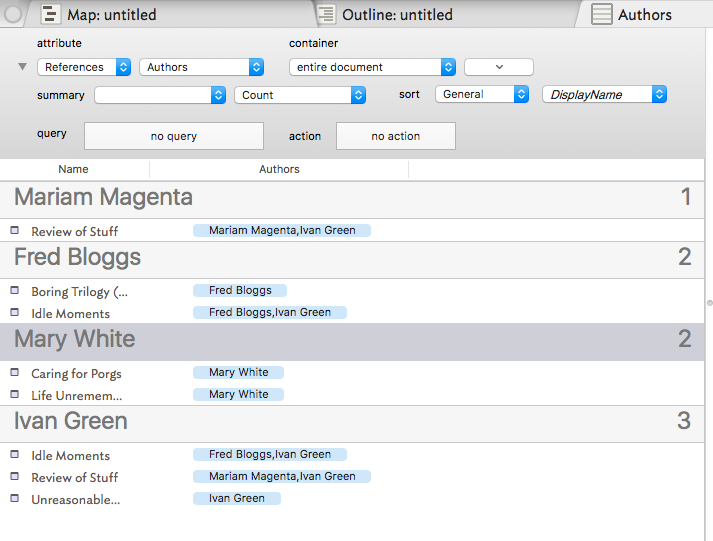
I’ve expanded the top panel of the view so you can see the settings. The view is listing by author. At the right of the author’s name is the count of books that she wrote. Here the note $Name is the book title - so choose your attribute for that if not $Name. I’m also showing $Authors as a column so you can see all the authors for a given book.
The neat thing about this is that there’s no ‘coding’ to do as with an agent. See more on Attribute Browser view.
@mwra is one of the invaluable go-to people here for guidance like this. I’ll just chime in to say that the Attribute Browser view is one of the underappreciated gems of Tinderbox.
When you’re dealing with info where the main relationships you’d like to see are text-related (as opposed to the visual relations you’d like to see in a Map or other graphics-centric views), the Attribute Browser often turns out, for me, to be the most useful way to look at things.
Thank you, Mark. I had no idea what the attribute browser is good for. Now I understand that not coding is necessary to solve my “problem”.
But (even if it is not necessary in this case) is there a possibility to use an agent to find the name of authors with multiple books and place the solution in a separate window like in other cases? This would give me a filtered list of authors with multiple books.
Not without some coding to establish the per-author-to-book(s) collection. That’s where the Attribute Browser is really useful.
I’m not sure I understand - the Attribute Browser is a tab just like Map, Outline etc. If you want the tab in a different window, just open the tab into a different window. Or, did you mean something else.
For an agent to work, you’d first need code so that each author note held (an attribute) value with the number of books where a given author was (one of) the authors.
If you create an agent you see the results of the agents action in this container. Tyhats what I meant when I told it a “window”.
I would like to have a filtered list of those authors who wrote more than one book. I understand that I can have this with Attribute Browser; but in the Attribute Browser you can see the authors who wrote only one book too. So I thought I could “eliminate” these one-book-authors when I use an agent which finds only authors with more than book.
Well, the Attribute Browser’s count of books per author is done on-the-fly. So you’re back to making per author notes and using some action code to calculate the number of book notes whose $Authors have values matching the author’s note.
With that you get only the books for ONE author.
But I want the agent to create a list of ALL authors with more than one book.
Maybe there is something like $Authors.Count >1 to produce such a list. This could filter alle authors with more than one book and produce a list (or map or what else).
That still has the same problem. Assuming your book author names are in $AuthorName, I would (not tested!):
Make a prototype ‘pAuthor’ to use for per author notes, and a Number-type attribute $BookCount.
Set a new note’s rule to $Text=values("AuthorName").sort.format("\n"); which will set that note’s text to all the unique author values, one per line.
Explode the note, at each paragraph, and set all new notes to use the ‘pAuthor’ prototype.
Set the prototype’s edict to $BookCount=sum(find($AuthorName==$Name(that)),1). Allow the edict to run or manually refresh agents. In a big file this may be a bit slower than most actions so better not to use an constantly running rule. Or, instead of an edict use a stamp on each author note.
Now you make an agent. Query: $Prototype=="pAuthor" & $BookCount>1. Sort on $BookCount anf then by $Name.
Your agent should have a list of all authors of 2 of more books.
…or you could use the Attribute Browser and ignore the single count entries.
I think this is an illustration of the lean programming / “what’s the simplest thing that could possibly work?” outlook that Mark B talks about in The Tinderbox Way.
If you had a large number (many hundreds, or thousands) of author-and-book combos, it would be worth the programming time and de-bugging to work out an automated system for seeing, in the Attribute Browser, only those authors with multiple books.
But in terms of efficiency and input/output ratios, I bet that an easier way would be either (1) as Mark A says, just ignore the ones with only one book, or (2) create some new Boolean attribute called, for instance, $MultipleBooks. Then when you have an author you know has multiple books – or that you see, in a quick scan in Attribute Browser, has many books – you could use a QuickStamp (or a rule or an agent) to flag that author as “true” for $MultipleBooks. Then it’s very easy to filter the attribute browser by that value, or an agent, or some other device.
Main point: if you have a giant data base, automating this process may be worthwhile. For a smaller set of data, the time it would take just to flag them manually is probably a lot less than the time it would take to work out the automation. FWIW.
I suspect the link approach will be more performant in a large document (because as I understand it, the find query will test every note). But I haven’t tested it, and I figure only @eastgate would know for sure.
store the $Authors in a book note,
will only work if there is a note for an author.
First I was collecting notes about books. All of these have an $Author. Then I recognized that there were many books written by the same $Author. So I wanted to have a quick look at a list of $Authors that wrote more than one book.
Marcs suggestion of using the AttributeBrowser works “on the fly”. As he wrote. With the disadvantage that I get list of ALL $Authors sorted by the number of books they wrote.
connect a book to an author via a link
Your idea of creating notes for books and nots for authors gives the possibility to create links in the mapview. And to create an agent for “multi authors”. That works fine and helps.
Thanks for that Pat.
Re @pat’s comment above about links, find(), and performance. I’d agree that a query including find() (within a agent or rule/edict) is likely to be a drag especially if the find includes regex operators like .contains(), noting that == tests don’t work against lists with >1 value.
If going down the link route be aware, in an agent context, of the difference between linkTo() and linkToOriginal()`. In most cases I think you’d want the latter but if you want to build a visible linked map in an agent, you’d likely use the format. However, such maps can get busy fast and may not suit a small screen. So do consider how you’re going to use this data before you dive into code and remember that whilst you may do initial tests with a few notes bear in mind the real number of items if you apply the code across your whole document.