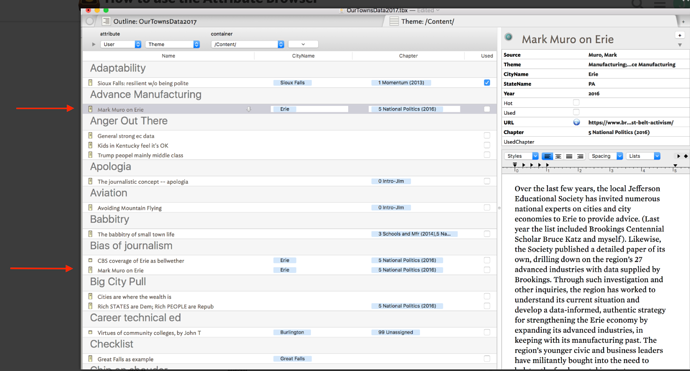
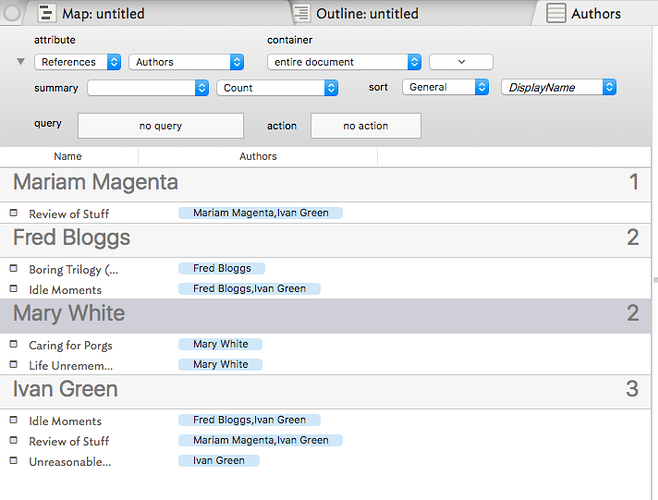
I commend the above answer.
Don’t worry unduly about getting the ‘right’ type. With user created attributes, Tinderbox will let you change the attribute Type, e.g. from Set to List or vice-versa. I say this to help breakdown the natural inclination to want to be right first time. Happily, unlike many apps, Tinderbox is quite forgiving in this regard.
Having decided you need an attribute allowing multiple values, i.e. a List or Set, you simply need to decide if any given list value can appear many times (a List) or is de-duped so each discrete value is stored once (a Set). A good worked example is above.
Now, following the above example, the general manager of several restaurants my have notes for different venues. So for the note on the Krusty Krab, the info might be set as
$Servers = "Mary;Ed;Kim";
$LeadServer = "Mary;Ed;Mary;Kim;Kim;Ed;Mary;Ed;Kim;Kim";
But in the note for the Chum Bucket, the same attributes might set:
$Servers = "Fred;Esther;Luis;Mina";
$LeadServer = "Mina;Esther;Mina;Fred;Fred;Esther;Mina;Esther;Luis;Fred";
In each case, the same attribute, in different notes, has a completely different set of values. Assuming only those 2 notes uses these attributes. If we ask for values("Servers") we get a list of 9 values:
"Mary;Ed;Kim;Fred;Esther;Luis;Mina"
We can sort that list if we want but the key point is we know that we have a total of 9 servers working for us across all outlets. values("LeadServer") also returns 9 items as the operation de-dupes the output. However, if we get a count of a note’s lead server per shift (LeadServers.count) we get the figure 10 telling us there are 10 shifts.
So practically, the difference in use reflects what you want to do with the data, and which is why your opening question is less simple than you might suppose.
Also be mindful of the fact that many simple/free apps limit user metadata (data about your data) to a single tagging (keywording) feature - a single bucket into which numerous strands of data must be poured. By contrast, the TBX I am working on uses 34 user attributes all holding important discrete strands of analytical data for my research.
If still unsure, try adding a Set and a List to your document and add the same data to each; as separate attributes there’s no bleed-over of data. However it will allow you to experiment with the differences described above and illustrate how Lists and Sets best fit your work.
HTH