Here are some working models – not final. In all the cases below you would want to ultimately replace $Text with $MyTextStub – a step not shown below. I suspect there might be bugs when $Text runs to multiple lines but I haven’t got that far with these ideas yet.
1. Partial Solution
This stamp (or action) gets part of the way there …
$MyPage=runCommand("grep -o 'Page\s[0-9]*'",$Text);
$MyTextStub=$Text.replace("\[.*\)");
$MyURL=$Text.replace($MyTextStub);
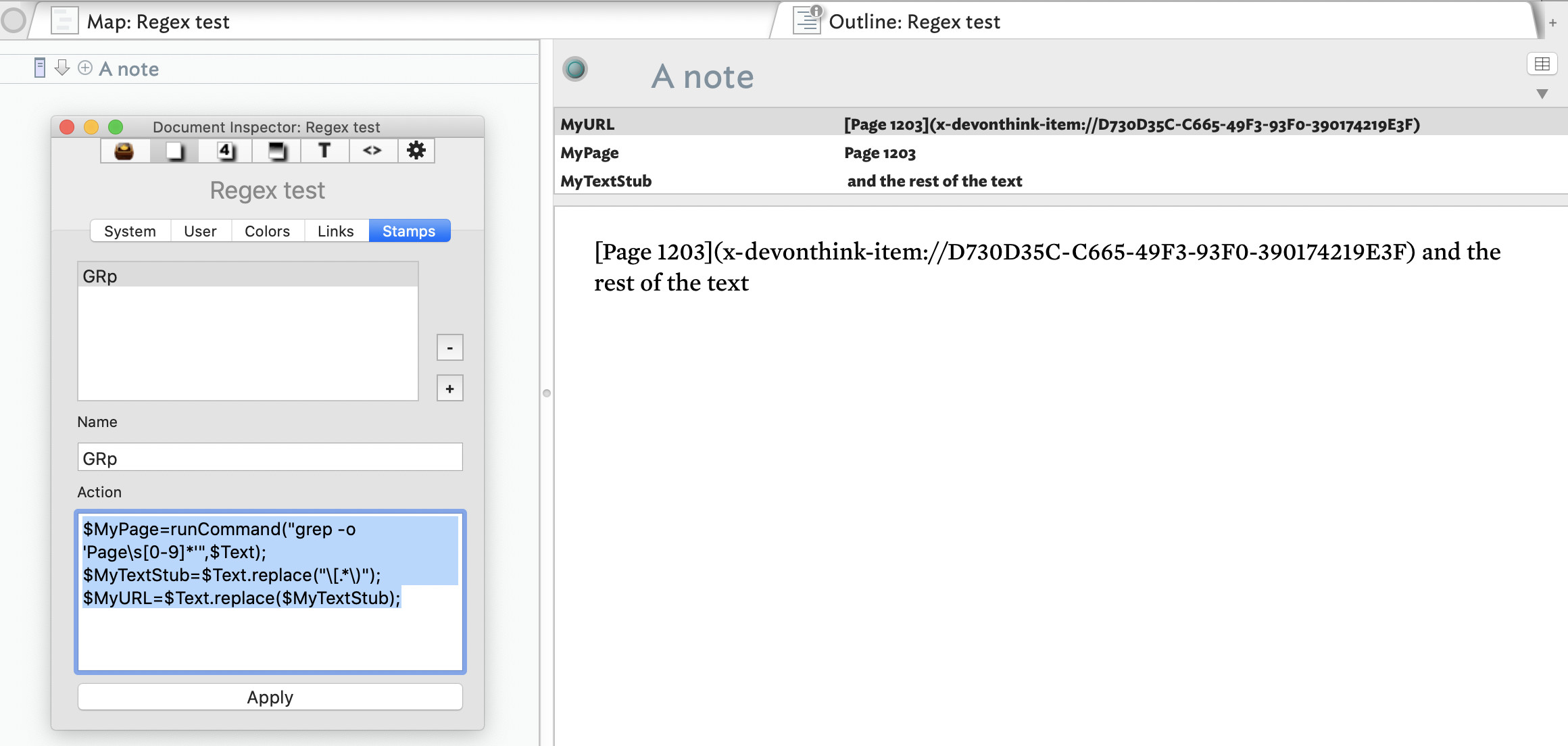
… but even though this should work to get the item link (x-devonthink-item://…) it is not working for me:
$MyURL=runCommand("grep -o '(?<=\]\()(.*?)(?=\))'",$Text);
nor does this alternate
$MyURL=runCommand("grep -o 'x-devonthink-item://[[0-9][-][A-Z]]*'",$Text);
2. Full but inelegant solution
$MyPage=runCommand("grep -o 'Page\s[0-9]*'",$Text);
$MyTextStub=$Text.replace("\[.*\)");
$MyURL=runCommand("grep -o 'x-devonthink-item://.*'",$Text);
$MyURL=$MyURL.replace($MyTextStub);
$MyURL=$MyURL.replace("\)");
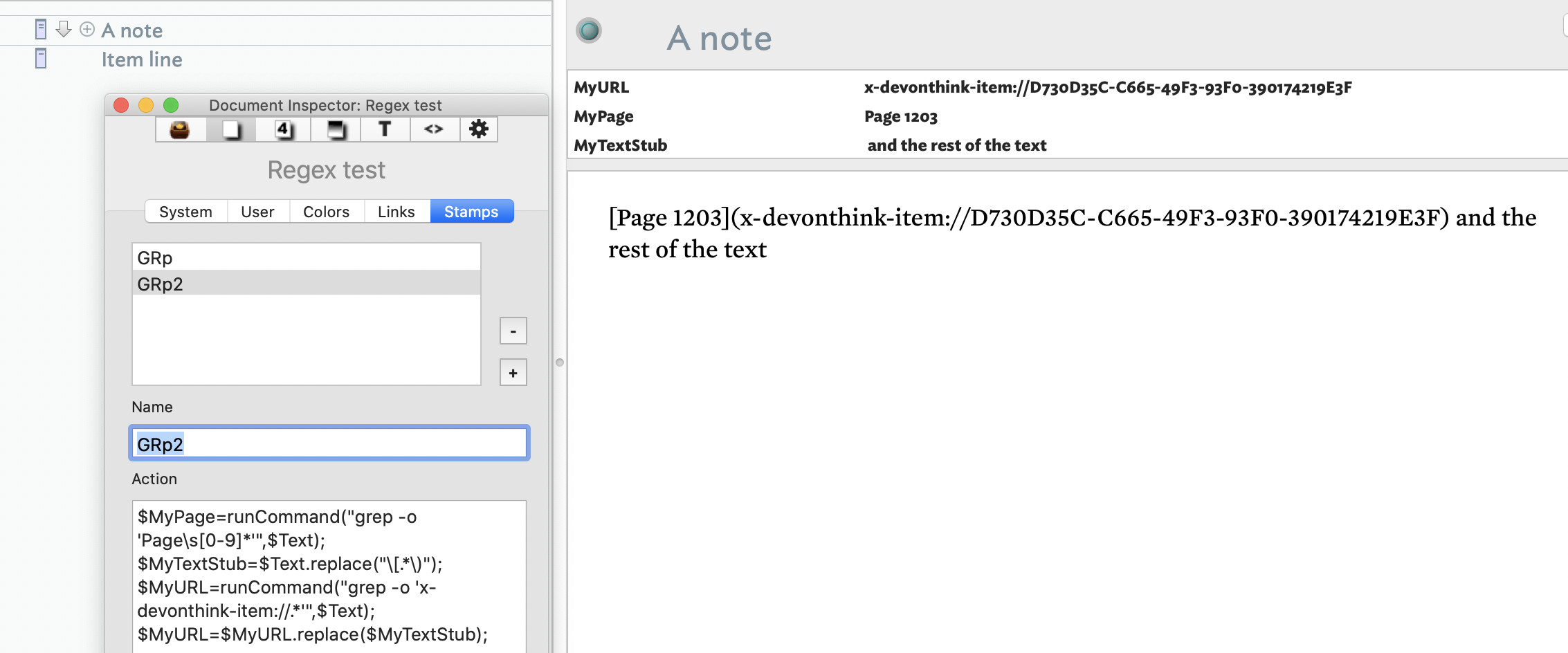
3. Better but still not great
$MyPage=runCommand("grep -o 'Page\s[0-9]*'",$Text);
$MyTextStub=$Text.replace("\[.*\)");
$MyURL=runCommand("grep -o 'x-devonthink-item://.*'",$Text).replace($MyTextStub).replace("\)");