I have a text I need to split into smaller pieces.
The text consists of paragraphs each of which starting with a number – like so:
“Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.”
“Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.”
Two Questions
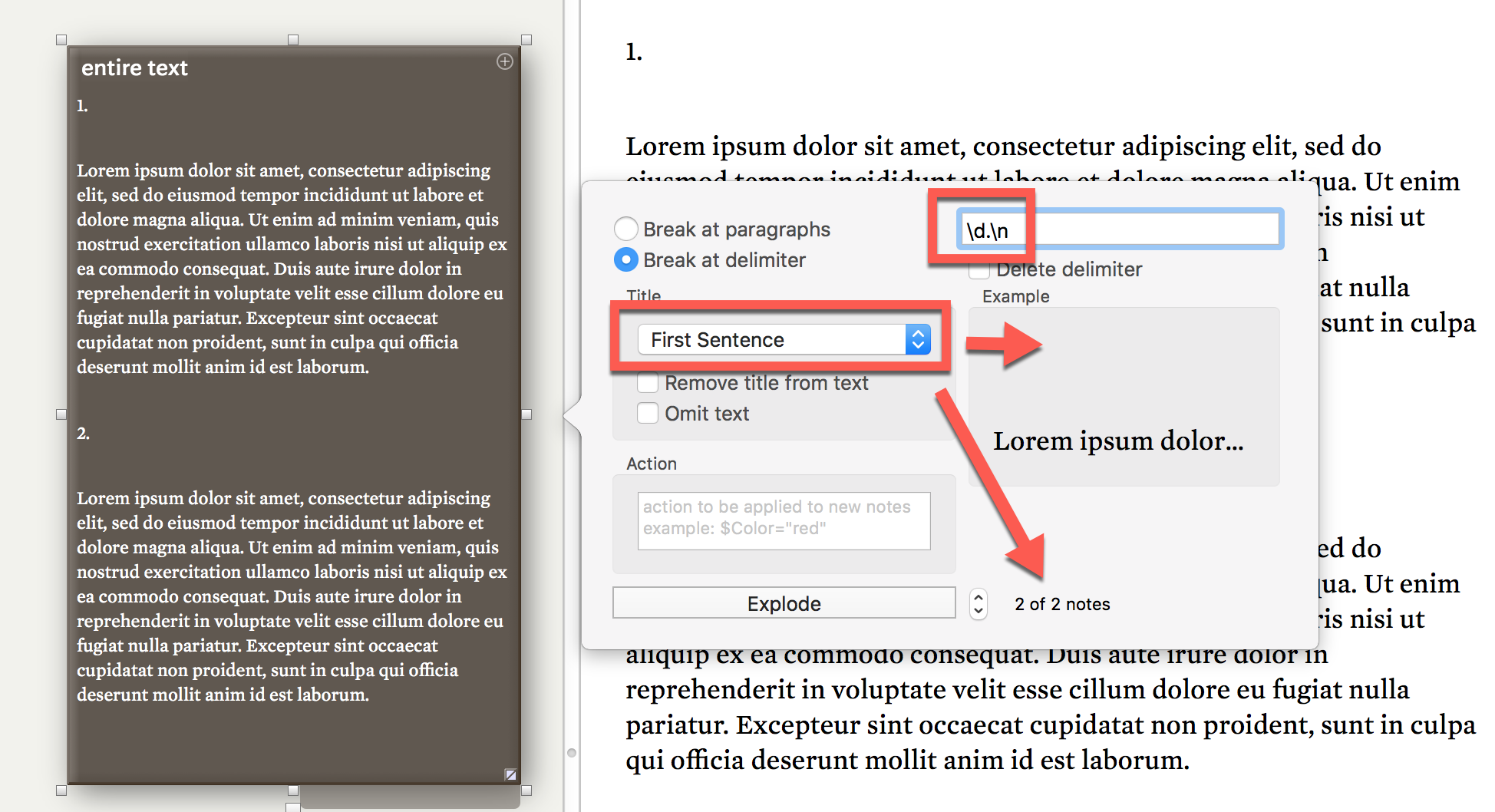
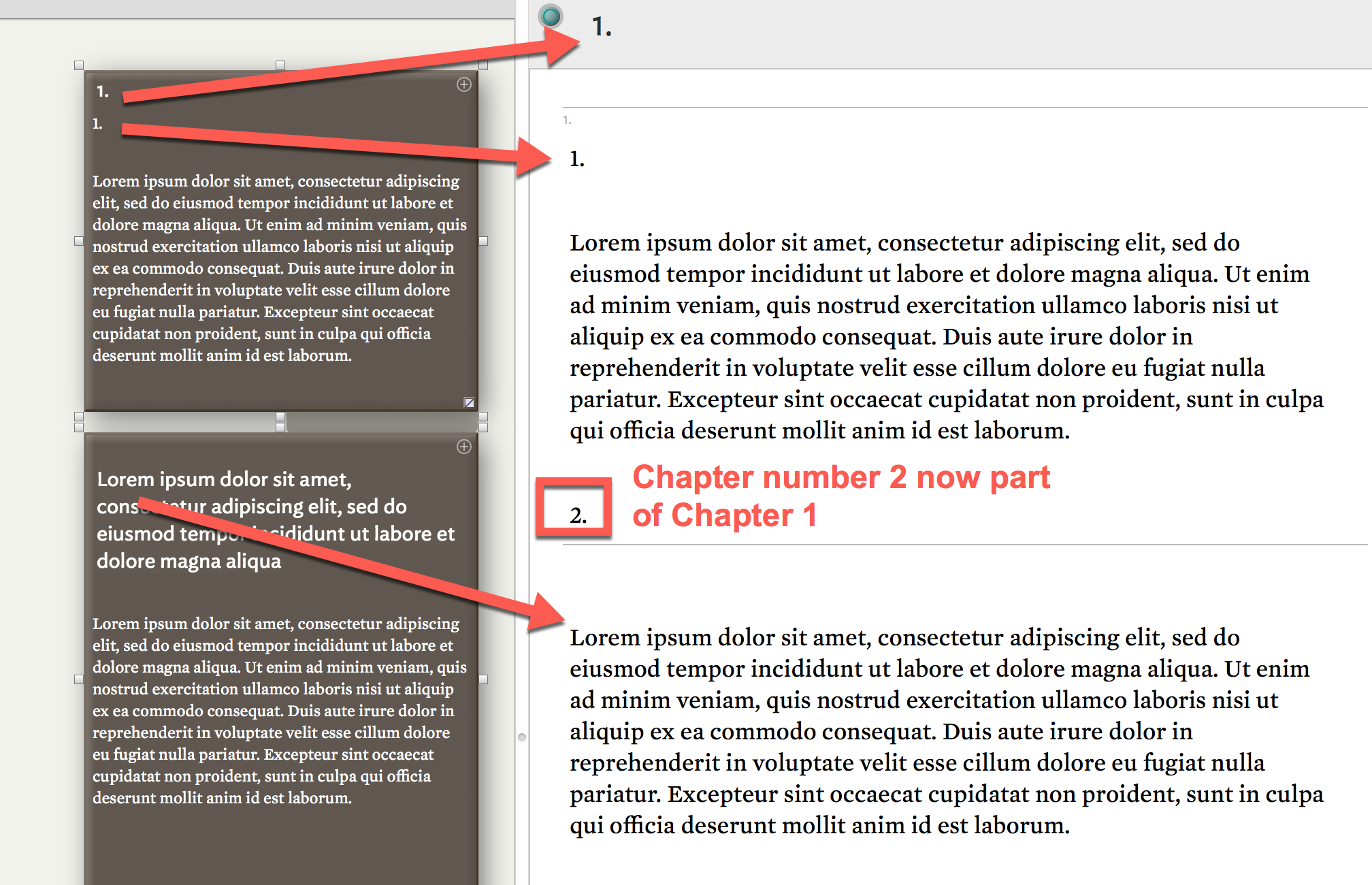
Using the RegEx “\d.\n” as Delimiter in Explode leads to unwanted result that the Chapter Number 2 is placed at the end of Chapter 2. **Is it possible to change that – and how?
Why does one have to choose “First Two Sentences” for Title in order to have a title for the second Chapter-note at all?
This appears to be an error I thought was fixed. Testing your example and variants of the delimiter regex I got varied results - none of them correct.
However, this is easily worked around. Put ###before before your numbers: e.g. ‘1.’ -> ‘###1.’, etc. Now explode using the custom delimiter ### and tick the option to remove the delimiter. I then get a clean extraction.
It seems one # works but I used three incase the actual real text contains hash symbols.
Any suggestion how one can easily cast “###” in front of 600(!) such number-headings without getting crazy. It doesn’t seem to be possible to find/replace within tbx’s text-view using RegEx. So should one go about it then? Using Third-Party-Software such as BBEdit? (At least this is one of the names I sometimes read her in the forum. But I’m not familiar with that particular software.)
If you do the first number (‘1.’) by hand** then this works for the rest, for me.
$Text=$Text.replace("\n(\d?\.)\n","\n###$1\n");
** as it has no preceding line break =-see above regex
But as ever with non-simple regex, do work on a copy of the text - at least until you’r happy there aren’t any unforeseen edge cases - regex are very precise in ways that are often counter-intuitive at first encounter.