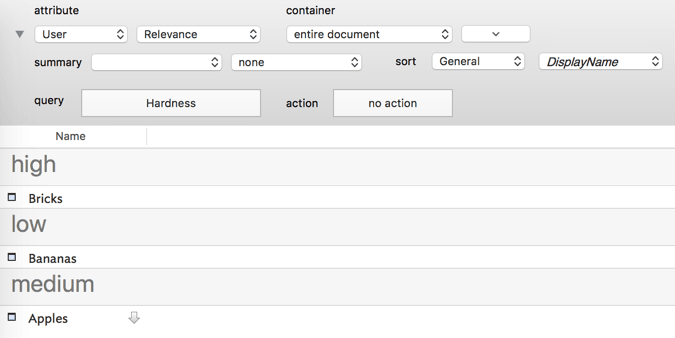
As a side note to the thread “User Attributes or Tags?” I thought I’d show an example from some of my current PhD research. in this case I’m looking at behaviour and outcomes in discussion surrounding bot use in Wikipedia. In this case there are some 4.5 topics spread over 75 archive pages. Here you see some items from archive page #10. I’d copied the topic headings from the page indexes and then used Explode to create per topic notes.
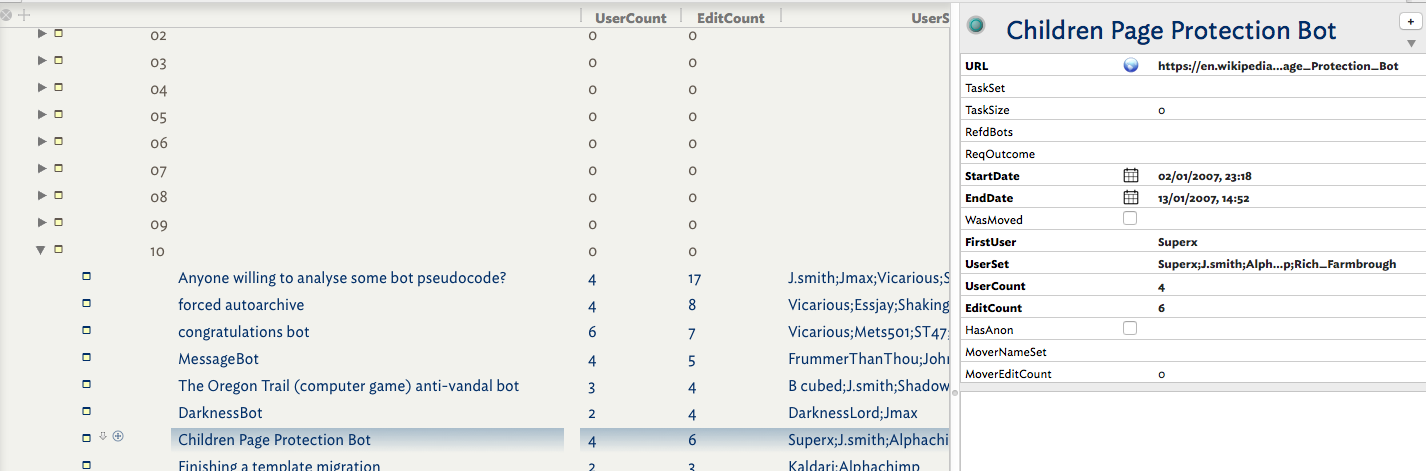
There’s nothing tidied here ‘for show’, this is data done earlier today. Notice a large number of key attributes. Apart from $URL, $StartDate and $EndDate, the rest are user attributes whose rational I’ll describe below. Many are empty as I’m using a 2-pass process, firstly getting date/person info whilst looking for incomplete source data (unsigned edits, wiki mark-up errors) and secondly reading for the purpose and outcome of the topic - in each case (supposedly) a request for a bot to do a task.
$URL. To save file bloat and because Wikipedia is reliably online and I’m in a setting with 24/7 access I’m reading the actual source web pages online. For research provenance purposes I have copies saved but as these are archives it’s easier to use the online pages so as to access other parts of the wiki to trace broken/missing data. To make the URLs I used the topic name, URL-encoded it than used a stamp to create the full URL (a stamp as I wanted more control with 4.5 items in scope).
$TaskSet. (Set). The range of task(s) being requested discussed.
$TaskSize. (Number). The number of pages to be edited (if mentioned).
$RefdBots. (Set). The name(s) of any bot account(s) actually named in the discussion.
$ReqOutcome. (Set). The outcome(s) of the request (if any!).
$StartDate. First edit in the topic.
$EndDate. Last edit in topic. Gives thread duration.
$WasMoved. (Boolean). Was this topic moved from elsewhere, or re-directed to another location
$FirstUser. (String). Name of the original requester (normally the first edit unless moved).
$UserSet. (Set). List of all contributors to the topic.
$UserCount. (Number). Number of discrete editors in the thread.
$EditCount. (Number). Count of discrete edits (some people post more than one comment), i.e. thread length.
$HasAnon. (Boolean). Are any edits by anonymous (IP-based) users
$MoverNameSet. (Set). For moved topics, the editors commenting re the move.
$MoverEditCount. (Number). The number of edits in the topic relating to the move as opposed to the request.
Note how the attributes mainly include a word indicating the data type (I find this useful to separate list from single values and Sets from Lists - as sets de-dupe and Lists don’t).
This set of Key Attributes arose from several restarts on the early part of the corpus and and sampling some later content. For now I’ve probably got what I need, with the granularity I need for later analysis. However, only a couple were created before I started working on the data. Before I’d read some of the data I simply couldn’t guess what might be there (indeed some of my assumptions were duly wrong and would have been wasted effort if pre-defined. Were all/most of the above just a set of keywords (e.g in $Tags) it would be far harder to get at the threads within the metadata.
Sorry for all the detail but I hope for those starting with Tinderbox and trying to see why one might want more than just ‘tags’, I hope this helps. Obviously, not everyone will be doing a task like above but hopefully the deconstructive process is clear and can be applied to your own projects.
Edit: I meant to add, note the use of columns here. I don’t generally edit into them but use them to check I’m completing important attributes and to look for emergent trends. Avoid the temptation to display loads of column and turn the display into a spreadsheet. I find it doesn’t aid clarity of thought and adds visual noise. I find 2-3 is fine, maybe about 5 if they’re booleans as they are tick-boxes when in columns so take little screen width.
I hope this helps - if not please ask. Sometimes picking apart and example can help anchor what is otherwise a quite abstract discussion.