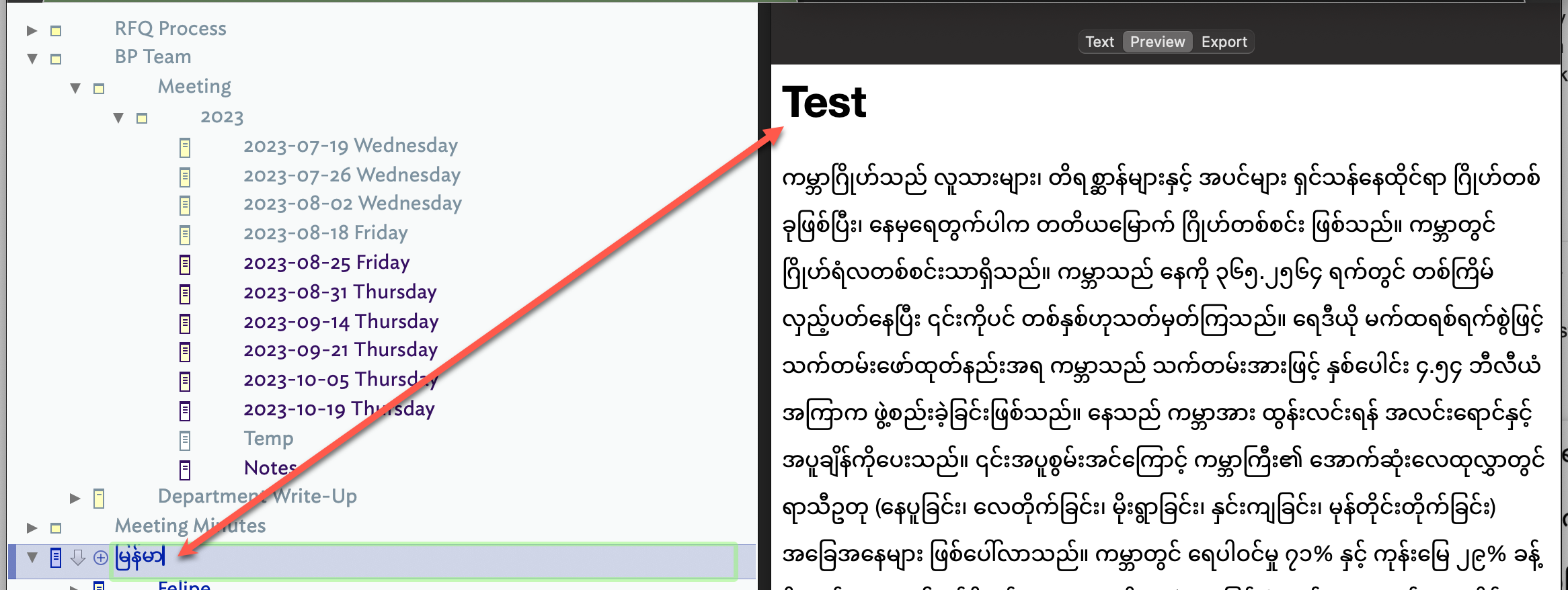
For some of my notes, I write in Burmese (Myanmar) and I have noticed that some words are not cut-off properly when moving to the next line. It is easier to explain in example as below.
If I understand correctly words are either (line) breaking where they should not or hyphenation is not occurring as expected.
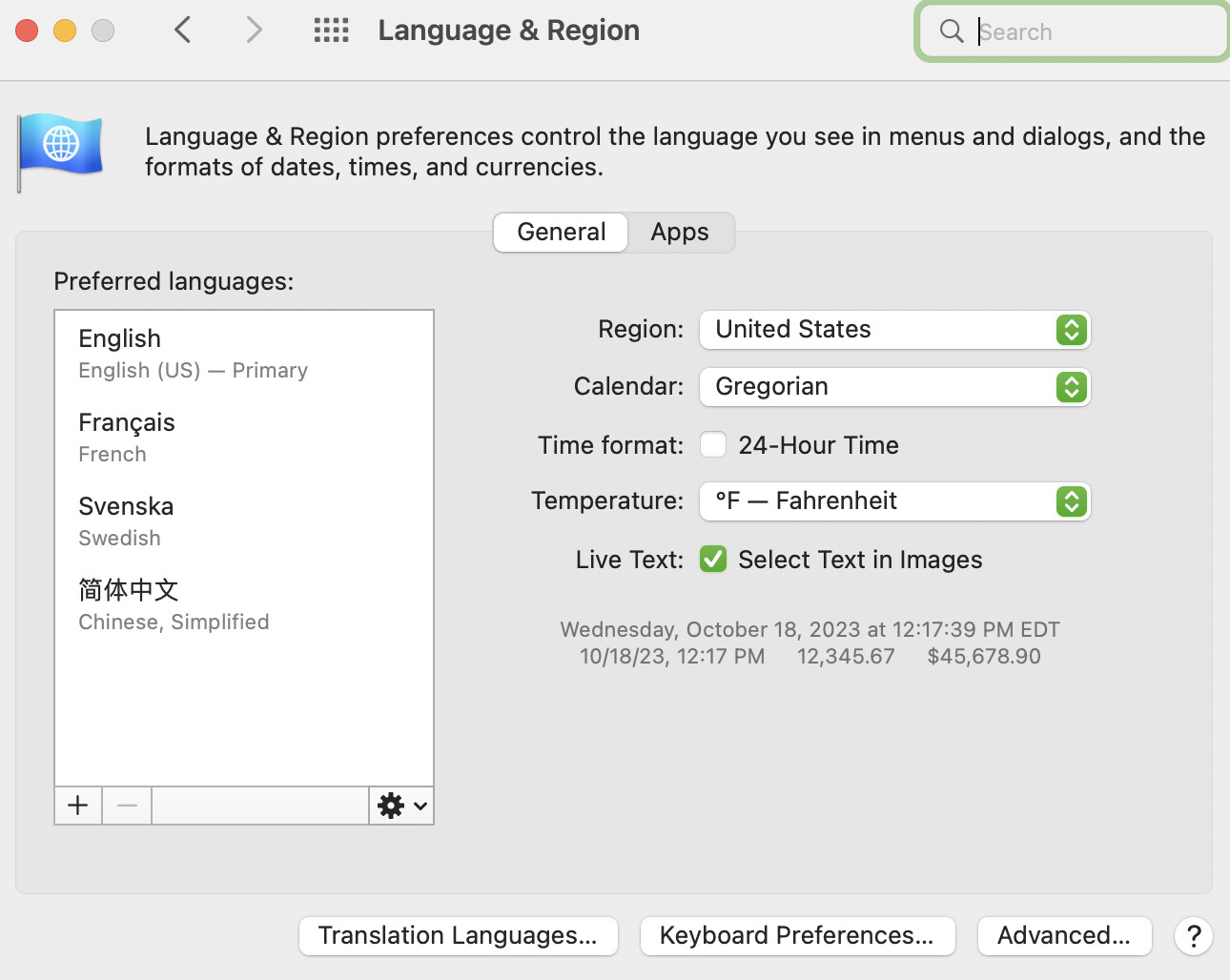
Tinderbox uses your Mac’s locale (country/language) settings by default, though these can be set differently using action code—see locale(). Why might this matter? No computers are Unicode capable It is not too hard to generate script/characters for different languages. So, on my UK locale system I can type in other languages that don’t use Roman script. But, getting the layout right involves a bit more than just the individual characters as other things come into play like where in a word may it break across a line end (or not at all/). I assume the latter are most closely used at the locale settings level. If your Mac is set to a locale other than Myanmar/Burma then it may help to use a more closely aligned locale setting. note that such a change might affect other things to do, so experiment with caution.
I suspect emailing directly to Tech support bight get you a faster/better answer: tinderbox@eastgate.com. As we here are fellow users of the app we can’t really see inside it, e.g. exactly how text locale rules are applied.
The key question here is whether the first entry in your list of preferred languages is Burmese or English. If the top entry is (say) English, then English hyphenation rules are used throughout.
If that’s the situation, an easy approach that might be satisfactory might be to allow notes to turn off hyphenation entirely. Indeed, if that were possible, it might even be practical to have an agent look for notes where the dominant language was Burmese and automatically turn off hyphenation for such notes.
This question has never been raised before, and I’m sorry to say that I’m woefully ignorant of Burmese. I think it ought to be solvable.
Thanks for the reply. Burmese does not have the concept of hyphenation and therefore it is more accurate to say that words are line breaking where they should not. I have tried changing the Mac locale to Burmese. However, the situation remains the same.
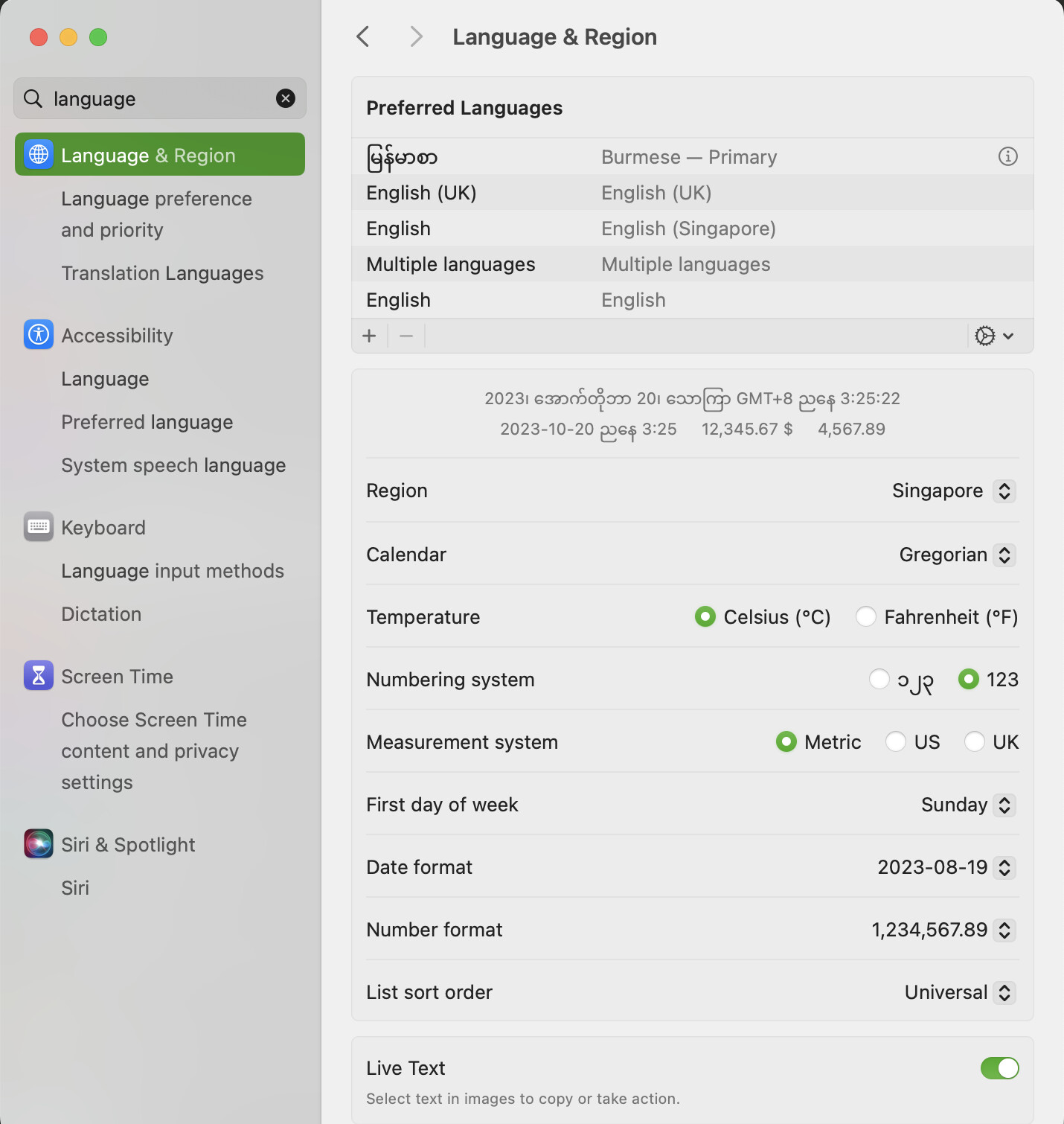
I currently live in Singapore and if I query the locale(), the result is still en_SG though, whether the preferred language is set to English (UK) or မြန်မာစာ.
I will do further tweaking and see where it leads me to.
Of the settings above, the ‘Region’ is what sets the locale. Locale affects more than the UI language, e.g. number and data formatting, though the user can often override some of these locale defaults via System Settings (see bottom of the screen grab above).
If any locale has support for Burmeses it is likely to be by setting “Region” to “Mayanmar (Burma)”. Or, you could try setting Tinderbox’s locale() to code: my_MM.
If Apple’s engineers haven’t encoded any hyphenation/word-break rules for Burmese script then I think you are out of luck. I wonder if organisations like SOAS might have some guidance on settings to use. I also fond this on ROMANIZATION OF BURMESE whilst Googling. Given that the latter doc draws on a document from 1908, I think it indicates this area is not well furnished in the digital arena. Things like Unicode allow for fonts to define glyphs for characters in various written scripts but they do not encode behaviours/rules of the language(s) using that script. The notion of a Locale allows for the latter but still requires someone to actually encode any necessary rules. The more a language is digitally written/used the more likely good locale support may arise, but it is not a level playing field where all languages/locales are treated the same.
Burmese is not a popular language and it is understandable that it would be totally strange to you.
I am wondering why the line breaking works as expected for Burmese in Apps like BBEdit:
FWIW, enlightened self-interest suggests you might ask the folks at BBEdit what they use for line-break/soft-wrap with Burmese text. The differing results suggest there is an algorithm (for Burmese text—or good enough for use with it), the question is where that is found in the tech stack. My hunch would be that Barebones didn’t write such a niche styling doc themselves.
I would like to ask about the word ရှင်သန်နေထိုင်ရာ .
As I narrow the window, Tinderbox tries to break this in three places:
ရှင်
ရှင်သန်နေ
ရှင်သန်နေထို
BBEdit does not:: either you get ရှင်သန်နေထိုင်ရာ on one line, or it wraps to another.
Is there any sensible rhyme or reason that you can see for the places that Tinderbox is choosing for the line breaks? I notice, for example, that double-clicking on this word in the Safari text field selects ရှင်သန်နေ, and double-clicking elsewhere selects ထိုင်ရာ. Google translate tells me that even ရှင် is a word, but perhaps it is hallucinating?
This is perhaps idle curiosity, but it might help figure out why Tinderbox is choosing these bad line breaks. I confess, I spent a few days in Myanmar some years ago, and I have never felt as illiterate since I was 4.
Compared to English, Burmese written language is far more complex. In Burmese, there are 33 alphabets, such as က, ခ, ဂ, etc. In addition to this, there are alphabet modifiers such as ု, ျ, ့, etc. The dotted circles get replaced with alphabets and the unique combinations result in words, for e.g. ကု, ချ, ခက်, etc. It is to be noted that one word can consists of more than one alphabets, e.g. ခက် mentioned. A single alphabet without any modifier may itself form a word, e.g. က by itself means ‘dance’.
Therefore, ရှင်သန်နေထိုင်ရာ is not a word, rather it is a clause. Its literal meaning is “that … live in” where “…” is replaced by nouns mentioned in front of it. The word order in English and Burmese is different. The individual words in this clause are then ရှင်, သန်, နေ, ထိုင်, ရာ. In line breaking, the aim should be not to break up the individual words. Following this, all of the below combinations are fine for line breaking:
ရှင်
ရှင်သန်
ရှင်သန်နေ
ရှင်သန်နေထိုင်
ရှင်သန်နေထိုင်ရာ
In other words, it is fine as long as individual words stay together. ထိုင် is one word and it should not be broken into ထို and င်. င် by itself is not a complete word.
It is great to know that you have been to Myanmar. And you sure are not illiterate as you know another complex language, which is programming language itself.
I will be happy to support with any additional information needed.
This is an attempt to write Burmese in Roman Alphabets. For example, Indonesian written language is mainly in Roman Alphabets. However, it is not popular in Myanmar, as Burmese has its own alphabets and written language. Some people do use this style in chats though when they do not know how to type in Burmese. We term it Myan-galish. Some people though frown upon it.
I hear you. My earlier link wasn’t English-speaking distain for other languages. Far from it! I just wondered if the info might help shine a light on the line-break/wrap issue.
Burmese text is more complex than English and which [sic] has 62 characters (26 uppercase letters, 26 lowercase letters and 10 numbers). In the Myanmar scenario, there are not only 75 basic characters, but also a total of more than 1881 glyphs
… although it doesn’t seem to suggest there are multiple alphabets. Further down it states:
Myanmar has 33 consonants, 12 vowels, four drugs, 10 figures, three asatas, one kinzi and 12 independent vowels.
So, I guess the 1,881 glyphs come from the 67 characters described above (plus diacriticals?).
Anyway, that likely add to complexity of hyphenation/soft-wrap rules. The fact that an native speaker/writer can spot errors doesn’t itself indicate why those formatting errors occur.
Anyway, I’ll step back here as I’m not sure I’m adding anything useful, i.e. it’s not helping. But, good luck getting this sorted.
This would be linguistically more correct. By alphabets, I meant to say 33 consonants. Consonants and vowels combine together to form words in general. Beside these, there are other independent vowels as mentioned such as ဪ, ဧ, ဥ, etc. All these add to complexity for soft-wrap rules for sure.
Thanks for taking an interest in this. Hopefully, there already is an existing algorithm that we could reuse to implement in Tinderbox itself, which would make this wonderful program more complete.
Yes: I suspect it’s just a setting. It might take a week or two to fix; probably not more, and perhaps less. (This is slow, but I have a conference coming up and a new chapter to write…)
FWIW, the previous exchange occurred whilst v9.6.1 was current: see the Change Log.
At time of writing v9.7.3 is the current public release. I believe the issue of line breaks in Burmese text is noted as an issue (#4178) but—as a fellow user—I don’t have access to its current status. My best guess is it is still and open issue at this point.
As we are some months on it might be useful to know your macOS and Tinderbox versions and your macOS locale. IOW the language in use for your Mac (Tinderbox inherits its locale for the OS) as these might impact on how things work. There are a few who are from country/language X who study text/language Y, writing in locale Z. By comparison the daft for most is that X and Z are the same and normally Y too. These factors generally don’t matter until they do!
Sorry I can’t solve the problem but HTH in the interim