Here’s a problem that the community might enjoy. I have a container /draft in which I’m gradually writing a paper. Citations in the paper look like this:
{Bernstein, 2025, WWW ’25 Companion Proceedings of the ACM Web Conference, 829-832}
I want to define an agent that tells me how many citations are currently in the paper. Details:
It’s OK to count repeated citations to the same work twice
Remember that one note might have multiple citations
It’s OK to assume that there are few or no other uses of “{”
I’m tied up today, so can’t play with your pattern until the weekend, but here is a quick reply.
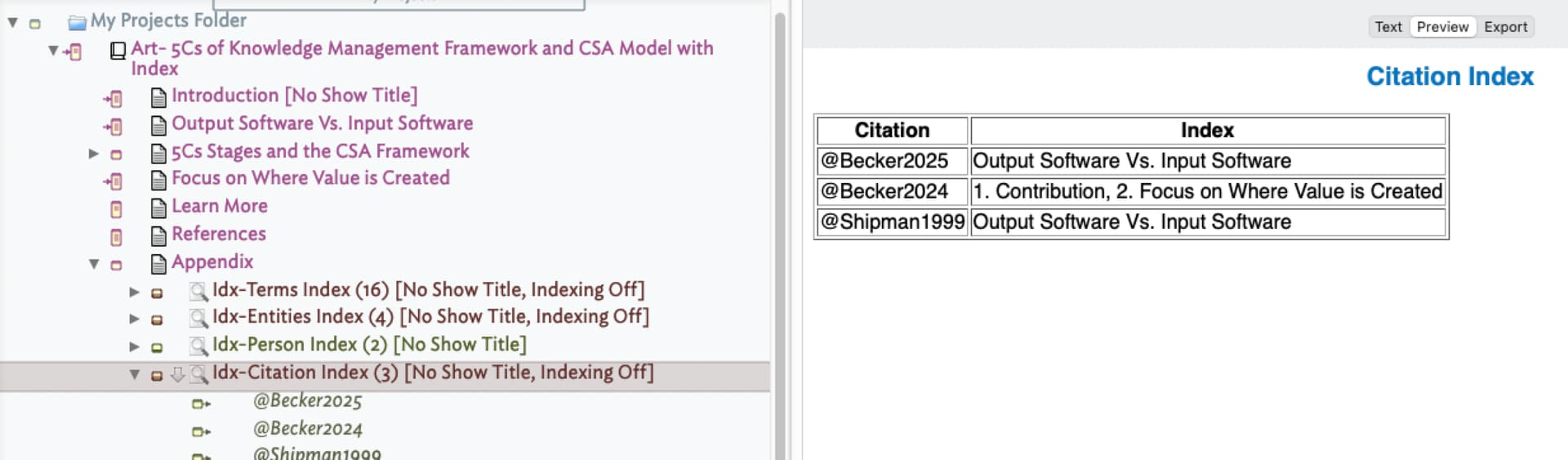
I use a different format for citations, as I use markdown and Pandoc to help me insert, track, and format citations. Here is the inline pattern [@CitationYEAR,@CITATIONYEAR] or @CitationYEAR [-@CitationYear]. I’ve set up several regex methods to parse these patterns out of the text into $IndexCitationKey:
This gives me a count. I also use it pull citations into an agent, and then with my indexing libraries and templates, I can create an index for which sections of the document the Citation is used (I intend to publish this library by the start of SummerFest).
For your pattern, I would do something similar but use this regex {(.*)}.
There are lots of assumptions and questions. Are citations the only use of the curly brackets pattern? Do you want or need to parse the caution when captured? How do you want to report on the use of the citations? Where are you conducting the count? In a template? Attribute browser? Table?
Likewise, just heading out for a fe days. Given @satikusala’s point about false matches, e.g. a mentions of coordinates at {2,9} or such, I’d suggest a regex like:
"\{[^\d]+, *\d{4},[^\}]+}"
So:
literal open brace
one or more non-digits (assumes no literal digits in author names, post-nominal III does not use digits)
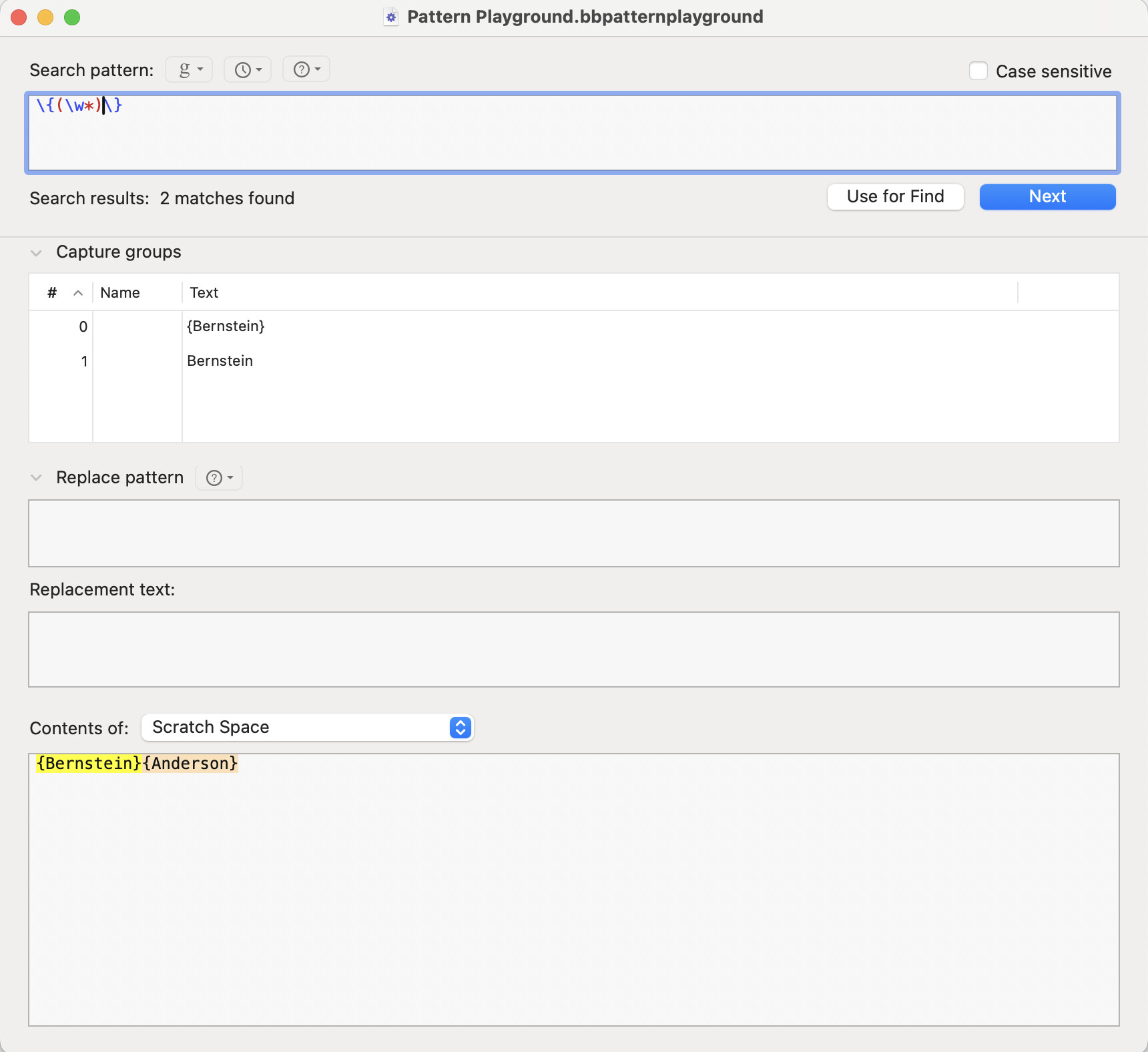
I believe each of these will detect the number of paragraphs that contain a citation. Ideally, I’d prefer to count the total number of citations; {Bernstein}{Anderson} should count as two.
My method pulls the citation into a set, which you can then count. It also indexes them so that you can see if you’ve used them multiple times throughout your document.
Forgive me if I’ve misunderstood what’s going on in your function, but AIUI, the regex \{(.*)\}, will normally match everything between the first { and the last one, so it returns Bernstein}{Anderson in this situation.
List:set— this is an excellent point! It gives me flexibility to measure either (a) the total number of citations, or (b) the length of the References section. Both would be worth knowing.
Alternatives: If I wanted to avoid regular expressions and was willing to assume that every { starts a citation, what would be the easiest way?
Yes, that was my point – your version will pick up too much in the given scenario, if there is more than one citation per paragraph. I wondered if your function dealt with this problem in some way – e.g. does the use of extract get over the limitation of your regex?
I missed this too! The if() merely tests whether there might by any citations, since if there are none we need do no work at all. The extract makes a list of all matches,
In some situations, you might not need of if() at all. If there’s nothing to extract, then extract() returns an empty list.
Unless I have misunderstood something about TBX’s version of regex, \{(.*)\} does not work with multiple citations in a paragraph, because the regex is too greedy – it slurps all the citations into one. Please see the screenshots to see what I mean: {Bernstein}{Anderson} returns one citation (Bernstein}{Anderson) not two.
So, you either need to change the regex to be less greedy, or do some post-processing to separate the ‘too-big’ capture (with the .replace command I suggested, perhaps).
Which is why I asked you if the extract command somehow manages to overcome the limitation of the too-greedy regex so it extracts all the citations in the paragraph, not just subsumes them all into one.
Yes, this is why \{[^\}]+\} is a clearer expression of intent. Inside the matched {} we look for one or more (+) characters that are not a closing brace. One or more not zero or more (*) to avoid mis-matching a legitimate empty set of braces ({}) as a citation marker. This approach is flexible at is doesn’t care where in the string the citations occur or if there is more than one per line (or tested string)
It may the edge case that (depending on the subject matter) that the subject matter has braces containing content. In that case, the braces alone are not a clear enough marker. If you have (and apply!) a very rigid format for the string describing the quote you could write a more complex regex to capture that structure. But, if {author, yyyy} is the pattern and Prof. A. B. Clump has 3 papers published in 2001, you’ll be tweaking your regex. and so on for each edge case that breaks the existing one.
Simpler, if braces-with-content sequences are an insufficient marker, would be to place another marker either immediately before or after the citation. For instance, with an @ symbol using either of these:
{@ ... }
@{ ... }
Users of Markdown might need to take care as to the character chosen and its placement, so avoid sequences that signal (or no longer do) intent to the Markdown parser.
Even if using a complex export chain e.g. Tinderbox+Markdown → pandoc → Word, or such, do stop to consider is inserted extra markers can be deleted before or at export.
IOW, the constraint isn’t what it appears, but you can choose when (necessary) extra markers are needed. Also, there isn’t a button /menu option that ‘just’ does this, in no small part due to all the (unstated) assumptions in this process.