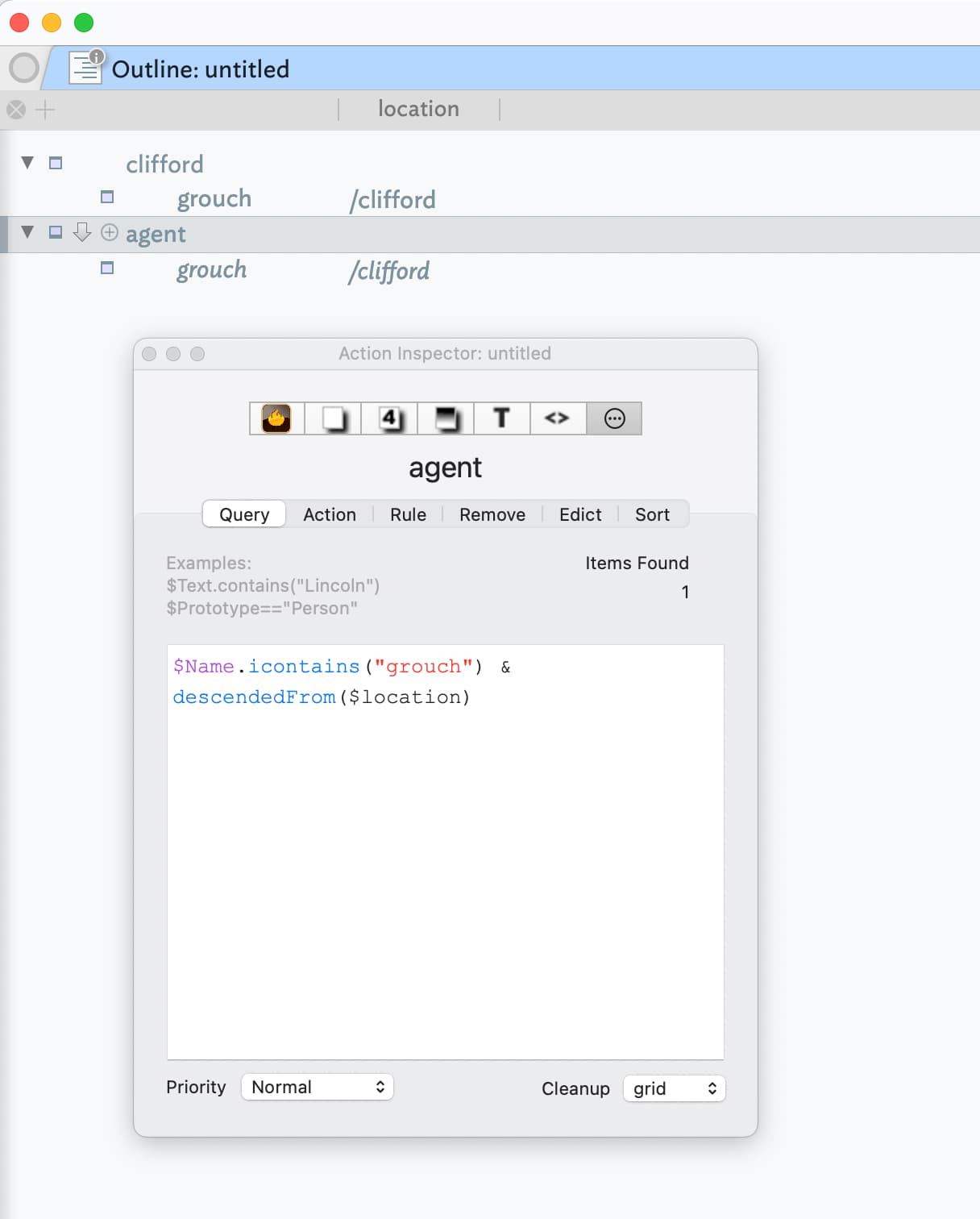
The agent query as it is written clearly does not work. In this example I would like to define the path for search in $location and have an agent query notes descendedFrom all notes in $location.
The issue is not the overall syntax but your incorrect referencing of the $location. As written, you are asking Tinderbox to test each note using the tested note’s $location value. What you actually want is to test using the agent’s value for $location. A special ‘agent’ designator is provided for this purpose and which can be using in either/both the agent query or agent action to refer to an attribute value in the agent and not the tested note.
If I use this query (tested in v9.1.0), following your existing layout:
A tip. In a test with a few notes the order of terms doesn’t matter. But .contains() and .contains() use regular expression matches with involve more (CPU) effort than other query terms. So, it is a good idea to place them last in the query. The works well with a general premise of writing multi-term queries so each term reduces the number of queries for the next term.
I’ve added spaces around the & AND join for clarity but they aren’t needed as Tinderbox ignores such whitespace.
Also see my article on Controlling Agent Update Cycle Time at the section on Making Agents More Efficient, which discusses the latter can be bookmarked for reference until the optimal ordering of query terms feels natural.
Testing this did cause me to add some ducmentation on which operators can (i.e. may) use regex in their operations and, by inference from above, are ideally placed later in multi-term queries.
The new info in not in the online aTbRef yet (I’m rather busy ATM) but here is a grab if the operators in scope:
The listing below shows those operators that are able to use regular expressions (‘regex’). Not all require use of regex, but rather regex are allowed in some contexts. For instance, a .replace() operator’s pattern argument that defines what to match could be a literal string such a a particular word. Or, it can be a regex.
For link and unlink commands the regex use only applies to selection of link types. For runCommand() is it relates to parsing of the input string.
For query efficiency in larger documents, it is generally beneficial if a first—or previous—term(s) are used to reduce the number of matches before regex operations are applied. Regex operations are potentially more cpu-intensive task (i.e. take longer than simpler tasks); very complex regex will also take more time that simple ones. The burden is individually small, but in a large document with many agents running, the sum might become noticeable. By writing efficient queries, e.g. putting regex-based operator as the last term—where the query allows, it is possible to pre-empt any such slow-down occurring.
Regardless, the latter issues applies to large and or heavily queried documents. A new user is very unlikely to need to worry about such issue in their initial exploration of use of agents.
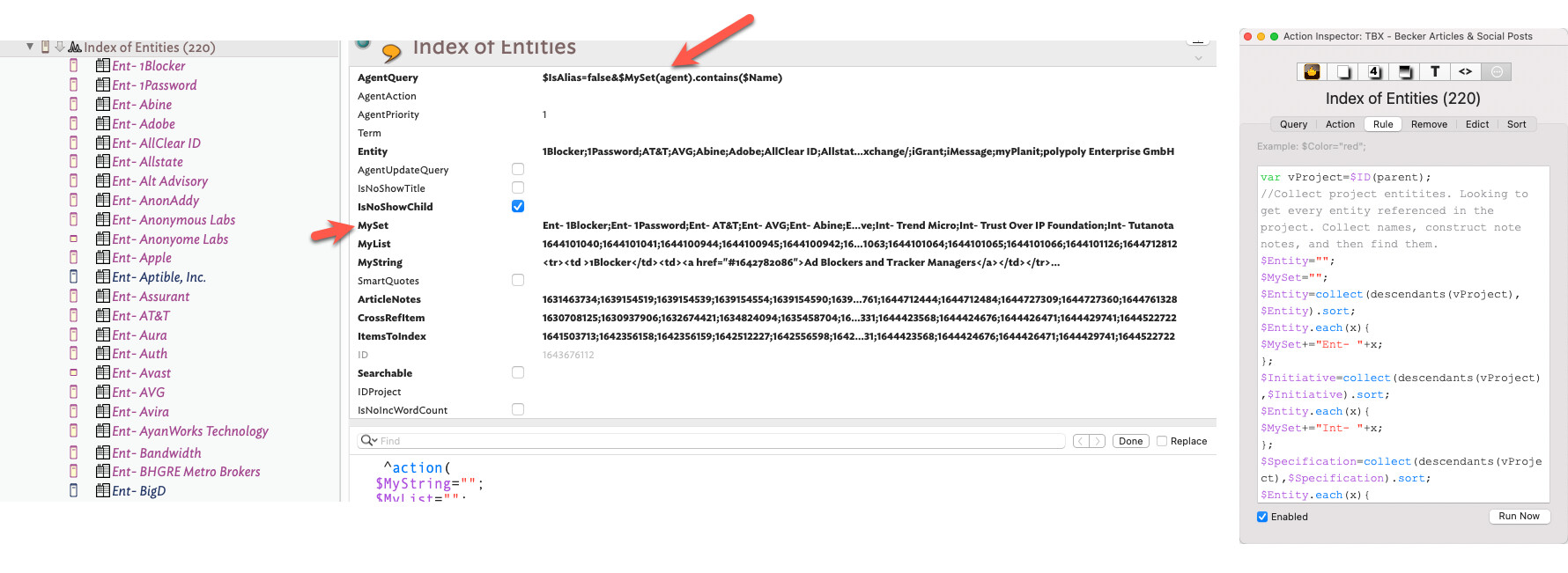
To pique your imagination, leveraging the process the @mwra explains above, check this out.
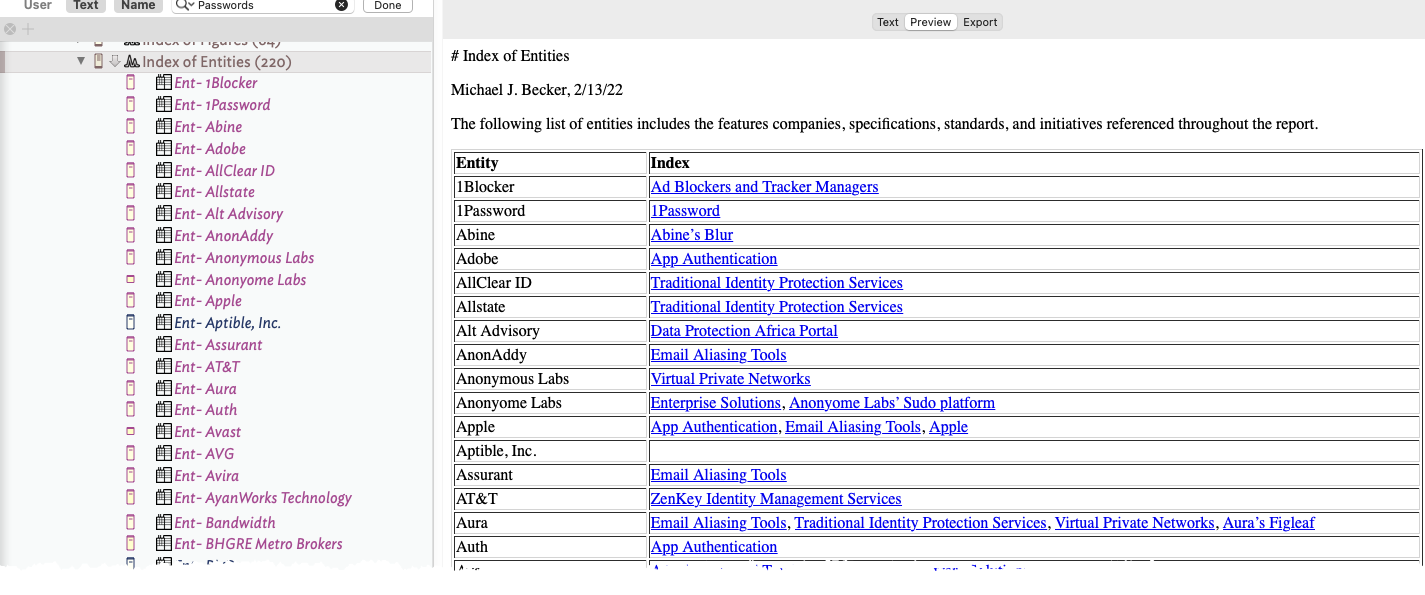
I have a $Rule that collects all the times I’ve referenced an entity (e.g. company, spec, standard, initiative) throughout 200-page book (in this example so far 220); it populates the agent’s $Entity attribute. I then have my rule set $MySet to match the name of the notes to these aforementioned found entities. The agent then finds these individual notes. I then have an inline action in the $Text that produces a table from these found notes and indexes the entities to the section of the book that they’re referenced. In the final output (an HTML file, PDF, Word Doc) the index is interactive; when clicked the file jumps to that spot in the document. Note, by leveraging pandoc, this final final is produced with one stamp to any output I want.
Using a similar method, but slightly different action code, I have Tinderbox pull a list of entities, create a bullet list, hyperlink their name to their $URL, and insert their $Tagline.
This was the explanation that I needed to begin to understand agent designators.
A curious thing happened. Using the agent designator, the code worked in the sample file - once. I am not able change the $location (saved the file) and have the agent give results for the updated $location. Selecting “Update Agent Now” does not change this(update agents automatically is also checked off). If I close and reload the file, the agents update as expected.
I am using Version 9.1.0 (b542) with Mac OS 11.6.3 on an M1 Mac mini. I have restarted the machine, only to have the same results.
This same behaviour occurs with Tinderbox 8. I can not imagine this is a bug with Tinderbox since the behaviour occurs in both versions. I will upload the file in case anyone wants to look. agent designator as attribute.tbx (110.3 KB) agent designator as attribute.tbx (110.3 KB)
It appears it may be your choice of attribute name, i.e. location. Location would be a more normal style of attribute naming, and indeed if I use an attribute of that name, you demo works correctly. After validating the problem you described, I tried using a different attribute using normal Tinderbox attribute naming style making a string-type attribute called Source. The queries then worked correctly. so I made a new string attribute Location and that worked.Edit: my analysis proved incorrect. For a correct explanation see below. My points re attribute name are , however, still of use so I’ll leave the post here.
So it looks like there is some sort of internal name collision with the (case-sensitive) word ‘location’ used as an attribute name. Why, I know not.
Tips:
Unless you need (as opposed to prefer) attribute names that don’t follow Tinderbox’s attribute naming style, go with the latter. Note: user attributes can be renamed, though any use in action code (queries, rules, stamps, etc.) will need manual correction; thing like Displayed Attributes will auto-correct.
Don’t use italicised note names. I know you can’t, but if you don’t need be aware that an italicised note name normally indicates a note is an alias of a note. Italicising the name of one of your test notes only added to the difficulty of figuring out the problem.
Avoid using attribute names that are the same as things like designators (hint: the latter use lowercase inital letters!) or other named Tinderbox objects. IOW, see bullet #1 above.
A recent change identified operators that take designators as arguments. Designators are evaluated less aggressively, so that a note named “2+2” is not confused with a note named “4”.
But inside() and descendedFrom ought not to be flagged in this way. This will be fixed in the next release.
Mark, thank you for your help and testing. I made another file with an appropriately named $Attribute giving similar results. The designators inside() and descendedFrom() seem to be evaluated only when the file is loaded as noted by Mark B.