We can often be tripped up by characters that look the same but which are different: for instance, the space and the non-breaking space. The latter are often imported in content copy pasted in from web pages (where they are use to assist text layout): Consider these texts:
- Some text.
- Some text.
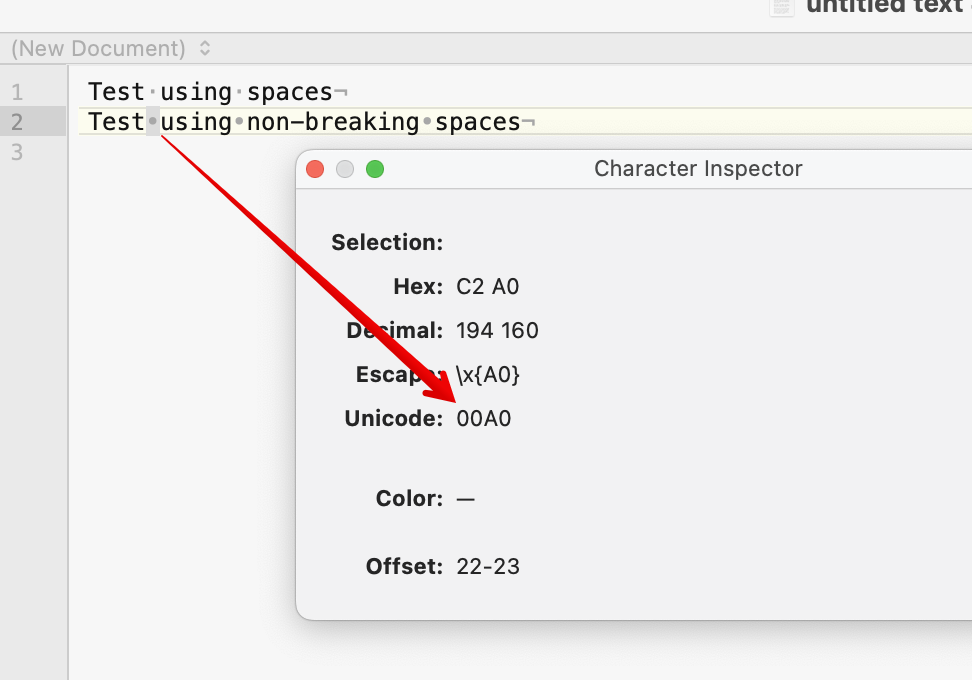
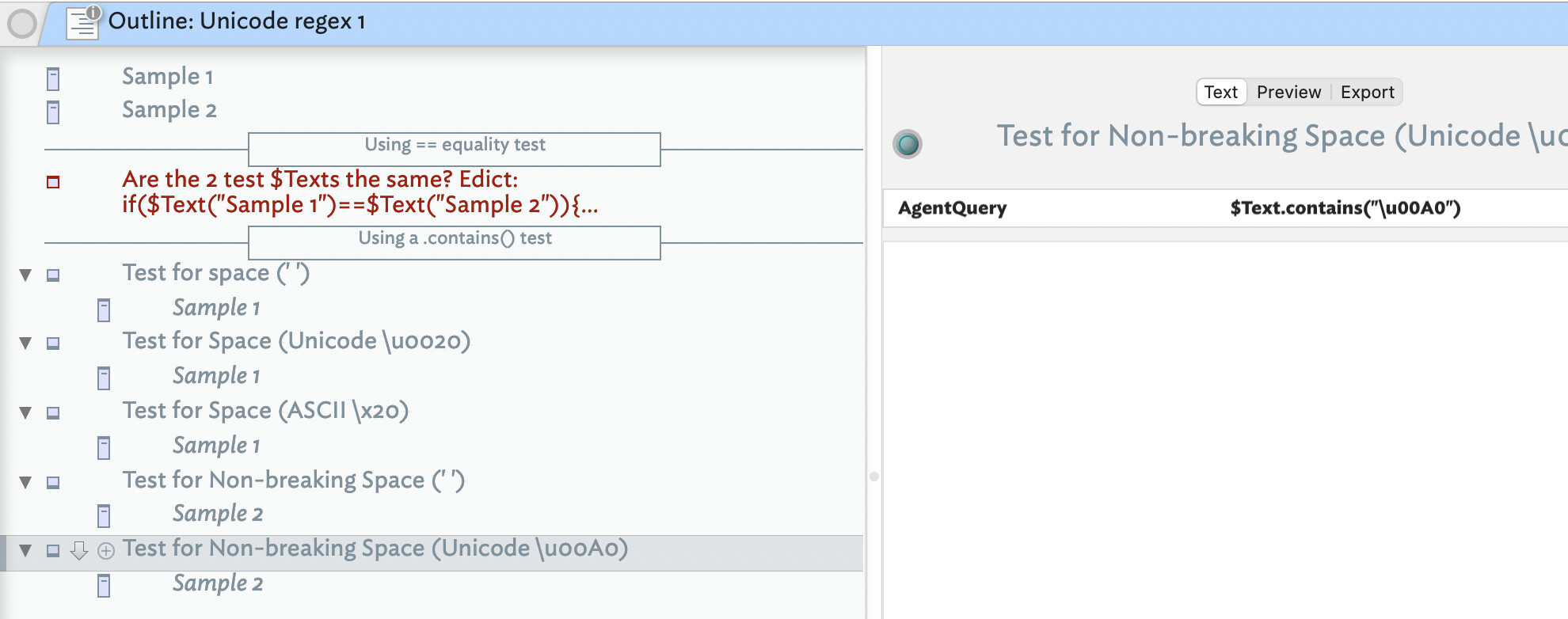
Are the spaces the same? In fact only one matches the query $Text.contains(" "); typed using a normal spacebar space. The first test uses a normal space, the second a non-breaking space (which can be typed as opt+spacebar).
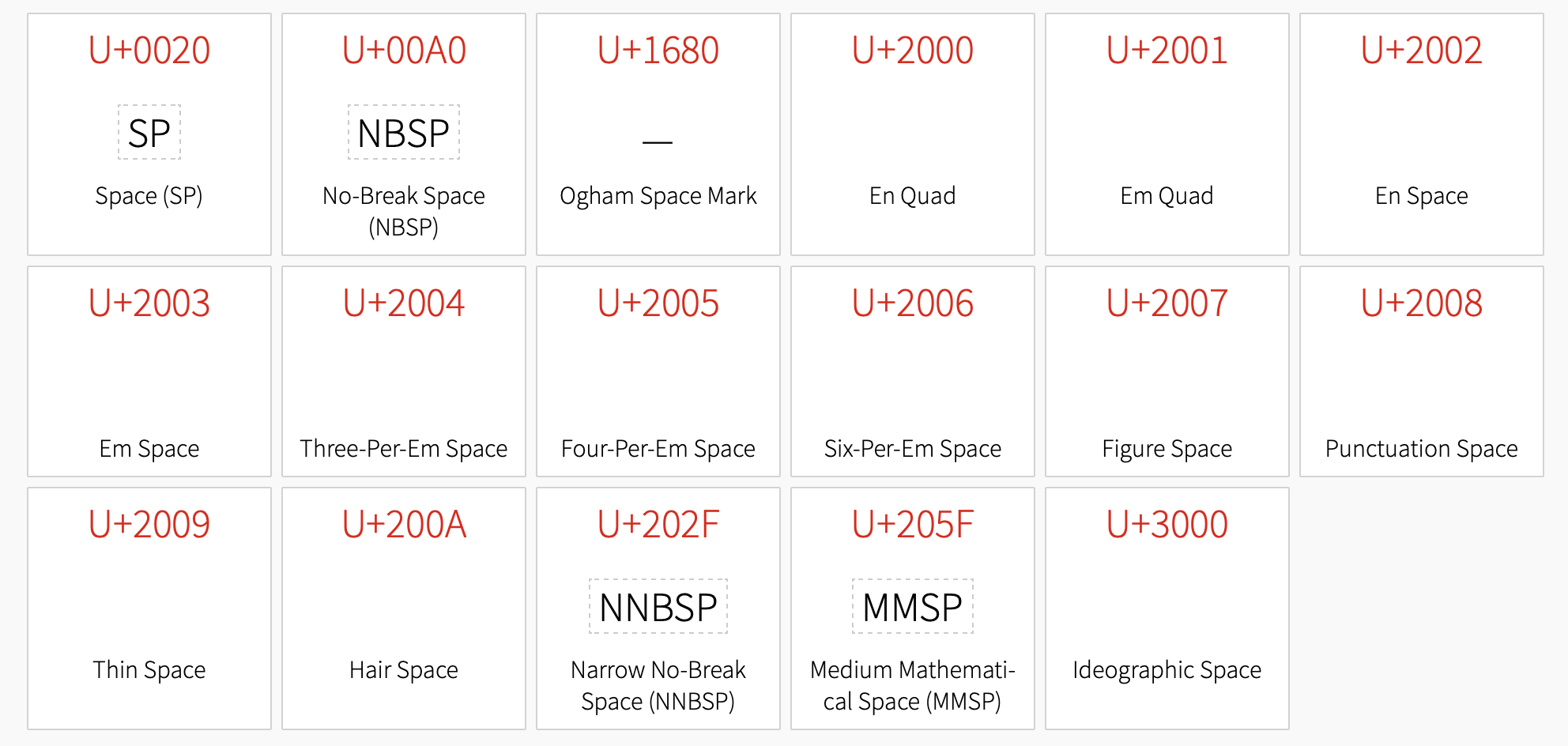
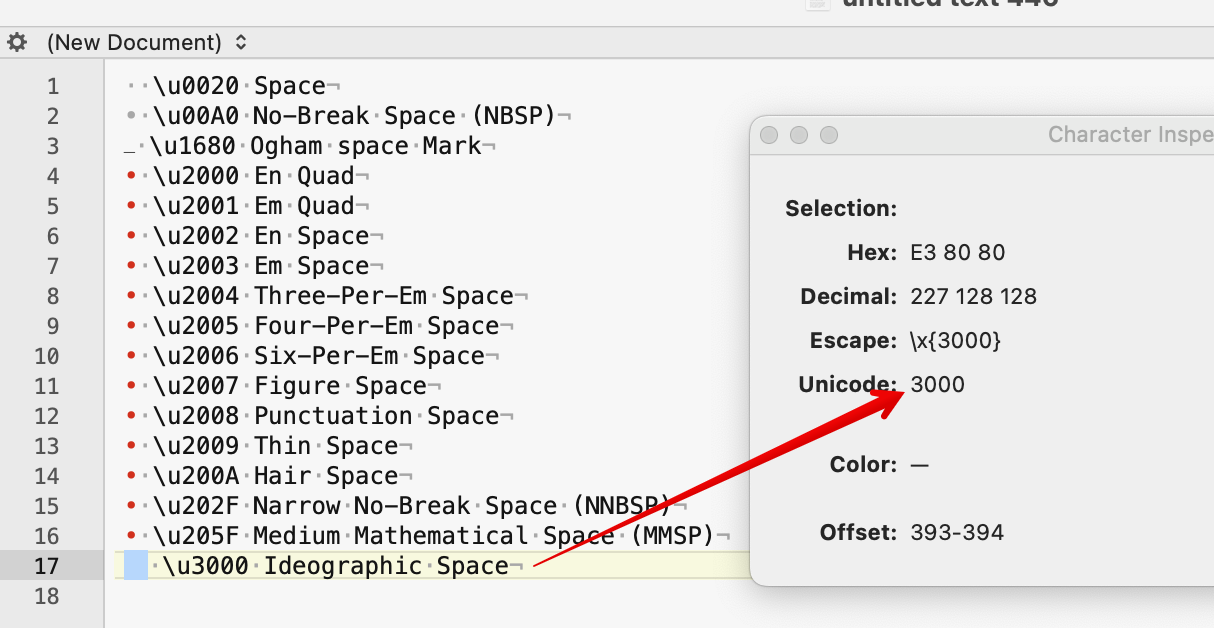
Is there a way to test for a character you can’t see and for which you don’t know of a shortcut? Yes. Assuming you can look up the Unicode ‘code point’ (a four-digit number NNNN) for the character, you can use it as a regular expression code in operators that support regex patterns like .contains(), e.g. u\NNNN (the u is case sensitive).
A non-breaking space is Unicode codepoint 00A0. So, to test for it in $Text use query:
$Text.contains("\u00A0")
Whereas a normal space is Unicode code point 00A0. So, to test for it in $Text use query:
$Text.contains("\u0020")
For characters in the low ASCII range, a shorter decimal number can be used,. thus a normal space can be referred to as Unicode code point 0020 but also as ASCII decimal number 20. In regex use a \x prefix, e.g. \x20. So these test for the same character:
// these are the same test, encoded differently
$Text.contains("\u0020")
$Text.contains("\x20") //
But a non-breaking space is not defined withi the ASCII range so the Unicode encoding method must be used. You can as above use Opt+Spacebar to type such a space but you won’t be able to see which sort of space it is.
Here is a simple TBX I made to explore this:
Unicode regex 1.tbx (213.5 KB) Corrected: Unicode regex 2.tbx (221.8 KB)
Not sure how to look up Unicode values? Just ask Google.
Edit: I’ve just updated aTbRef’s page on Regular Expression usage to reflect the above.