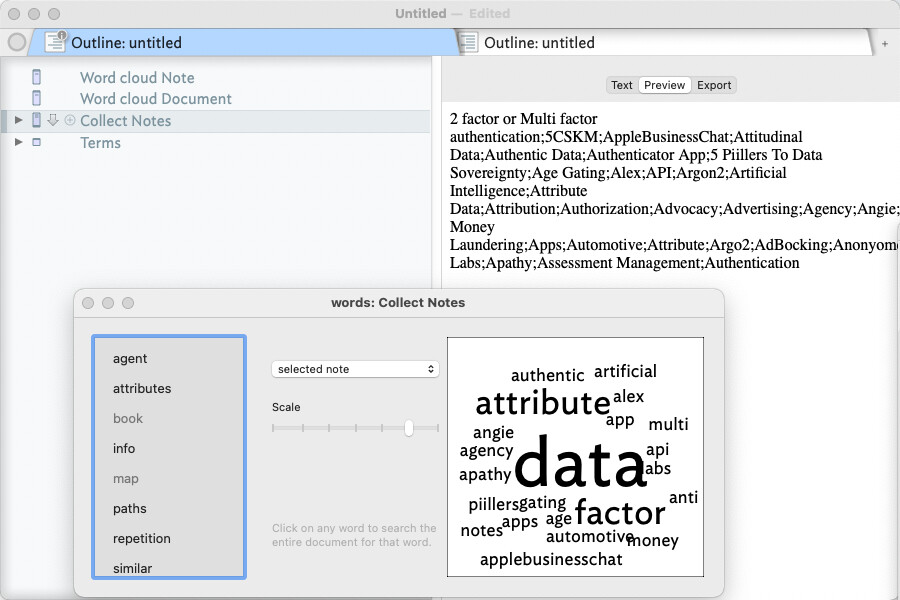
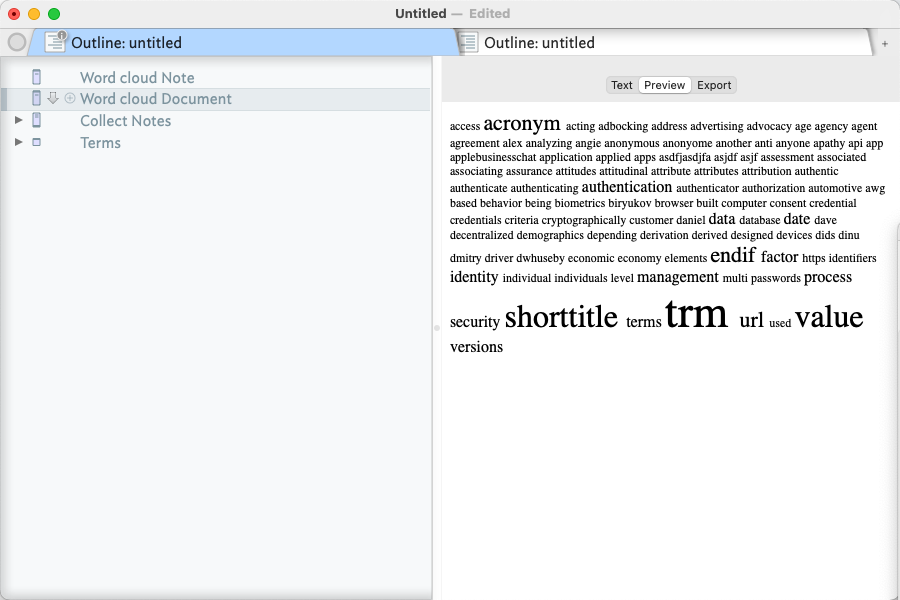
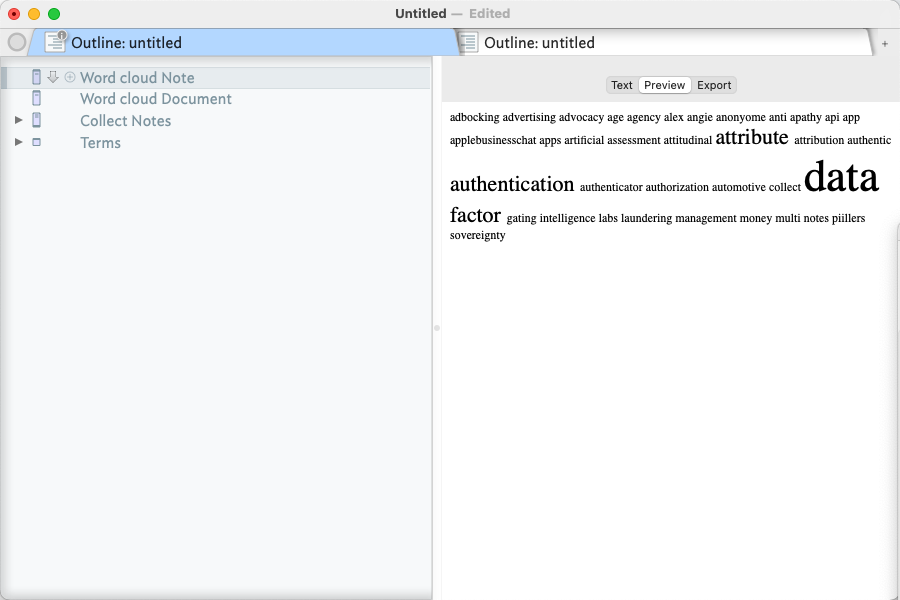
I am experimenting with word clouds. Works great at the document and container level to visualize word frequencies however NOT so much at the query level. Perhaps because queries use alias notes? Maybe I am using word clouds outside of their intended use as a edge case. Perhaps, but it makes sense to me to have a word frequency of a query to help identify subset key words / Topics.
An alternative question would then be, is there a way to get word frequencies from the results (children of) of a query? IOW…a way to quantify a term-frequency within a query? I am after a ranking or weighting of relevant word terms within the subset of my query.
At this point, looking at scoping choices available, I think an alias and/or it’s child aliases would be a feature request (and perfectly a sensible noe, too). I guess no one’s asked for this before. I can’t speak for how much work it will be for @estgate to implement if the idea is accepted.
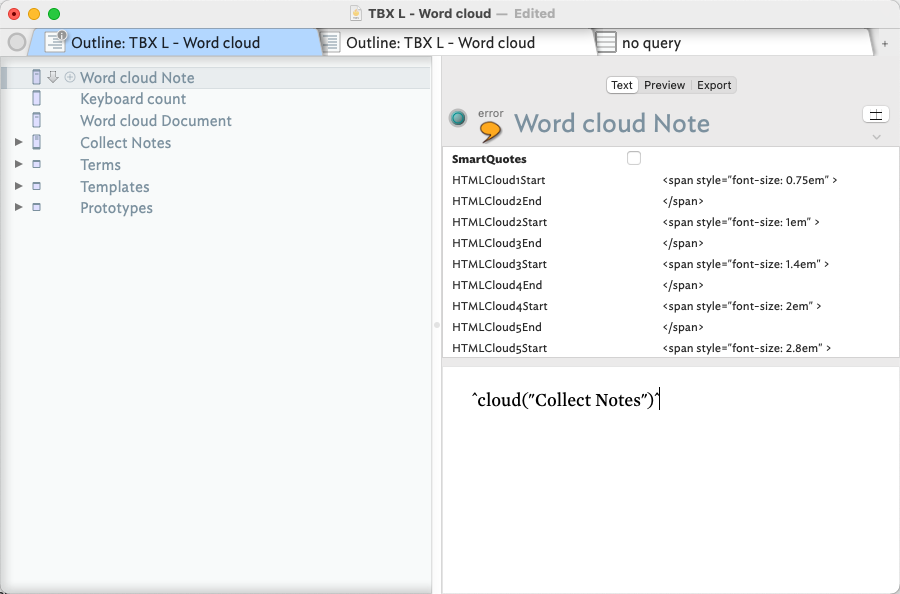
In the short term you can experiment in a template [sic] with ^cloud()^, and sibling ^sectionCloud^ and ^documentCloud^ but note that these don’t give numerical counts as I think you need to use.
I agree that it makes sense for the word cloud of an agent to consider aliases. Normally, we wouldn’t want to give extra weight to notes that happen to have aliases, but this change makes sense.
@TomD, there a ton of ways to do this. The simplest is just to collect the elements you wan to count form the children and populate the text of a note, e.g. the agent’s text.
In the the $Text “Word cloud Document” note you need to change ^documentcloud(100)^ to ^documentCloud(100)^ as the code is case-sensitive.
The problem I see with this approach is that whilst you see a word cloud in Preview mode you don’t see any Export (HTML) code and so other than relative size you’ve no real clear view of the actual occurrence counts of words.
Under the hood, for the export code to work I suspect it is building a count in order to render the font-size counts for the HTML view. I wonder if TBX could return the world cloud term counts somehow to an attribute dictionary, e.g. $DictWordCloud=Data:4;Perosnal:3;Cybercrime:2…". If this were possible we could have the best of both world’s both the visual and the analytics. One more ask might be to cache the preview as an image that could be shown on hover and fill, but that is asking for a lot, ;-), and not completely necessary as it could be done manually pretty easily with a few clicks of a button or automatically with keyboard maestro and one click.
IIRC, the output uses 5 levels of text size in the exported ‘map’ as set via $HTMLCloudStart1, etc. But I still don’t think the process shows how the 5 levels are apportioned.
To add to Mark’s point, I do not wish to move any of the original documents from their original location.
Using an agent, I want to explore the data, gather the alias notes then explore the term frequency or word cloud of this subset with the alias documents the agent found.
If you can wait a bit, I can make this doable with agents.
If you need it immediately, you can still do it. Outline:
Make an agent to gather the notes you want.
Iterate over the children of each agent.
Make a container /Cloud
For each child, make a new note in /Cloud with the same name
Set the text of that new note to the text of the alias note
Now you have copies of the pertinent notes in a container, and can get its word cloud. This used to be really, really hard; now I think it’s reasonably practical. But it’ll be trivial in a couple of weeks.
 Perhaps because queries use alias notes? Maybe I am using word clouds outside of their intended use as a edge case. Perhaps, but it makes sense to me to have a word frequency of a query to help identify subset key words / Topics.
Perhaps because queries use alias notes? Maybe I am using word clouds outside of their intended use as a edge case. Perhaps, but it makes sense to me to have a word frequency of a query to help identify subset key words / Topics.