I have a tricky question. I have been trying to convert text links using relative paths into links using absolute paths upon export. I thought this would be relatively easy, but I am stumped. No amount of hacking and chopping allowed me to do it yet. Has anyone tried this before and managed it?
Part of the jigsaw is likely $HTMLExportPath. this is especially useful if you are using dynamically-generated path/filenames. One side note: IIRC, this doesn’t detect issues like sibling notes that generate the same export path, so something to test (as I may well be wrong).
I’m not sure how Markdown plays part here but we’d need more detail of the process.
Thanks, Mark. I know about $HTMLExportPath. The question is how do I get Tbx to use it instead of relative links? The only thing that comes to mind is getting the path directly from the $Name using ^value($HTMLExportPath($Name))^ and the replace the relative link, but that seems somewhat tricky due to names having to be unique. (Ideally, it seems, this could be part of the export options. A bool attribute to turn off relative linking.)
Edit: Actually, that wouldn’t work. We would have to take URLs from the text, extract the last part of the URL, remove whitespace replacements, then find the path/full url using this approximation of the linked notes $Name Then replace the relative Path/URL with the full Path/URL. It seems hacky and convoluted.
As you mention $Text, this is the hardest part as the user has no effective control over link mark-up generated on export using ^text^ which is, as per original design intended to generate HTML (and Markdown is only a form of pre-mark-up for HTML even if other tools such as pandoc further extend format changes).
^path^ may be of some use though essentially $HTMLExportPath already provided access to that outside the export environment (i.e. not in ^code^).
To avoid ambiguity on exporting names you can explicitly set $HTMLExportFileName for any/all notes or just those to be exported/linked. Likewise use of isDuplicateName() during creation of the content can alert you to possible name duplication and allow you to set a different $Name (or $HTMLExportFileName).
Also, having the full (export) path generates a further problem, as you now need a full URL (i.e. including protocol, domain names, etc.) to make the resulting HTML link usable. The benefit of relative links is the exported files can be used and links traversed even locally as the relative link traverses in situ rather than fetching from a server. So, I’m not sure a proposed fix is as simple as an option to export the relative path as the absolute exported path name and not in ../../.. form as then the domain is needed for a valid HTML link src value; otherwise the partial absolute path will be evaluated as relative to the current page, which is not your intent.
Emerging from back down this rabbit-hole, what is the problem we are solving by having absolute paths? I’m not implying good or bad but simply seeking more context that might offer us a different approach to solving the causal problem.
That’s a good point. To give context, I am using the exported Markdown files with a Python-based static site generator for documentation. To cut a long story short, it doesn’t like the Tbx’s relative paths and, in some cases, I need the full path (relative to the primary folder) to get a redirect plugin working (some links need to be redirected to allow linking to anchors inside other pages).
Hey there, my workaround for this was to use $HTMLExportFileName=$ID, that way the file names 1. have no spaces and 2. are guaranteed to be unique. It’s been ages since we’ve talked. Ping me and let’s hop on a zoom. I can show you.
The problem isn’t the filename but the path to it. The python-based app @Bernard-0 is used with the Tinderbox-data seems only able to work with a subset of URLs, i.e. absolute URLs. IOW, it can handle a UTL like this:
src="https://example.com/path/to/file.html"
but not like this:
src="../to/file.html"
though both are valid, albeit the latter requires the ‘browser’ (interpreter) to map the latter to the former.
for better or worse, Tinderbox is designed to produce static HTML pages. The exported pages reflect the source files outline structure (regardless of the exported file/folder names of the source content). Using relative links is thus sensible as it means that, whether you export 2 linked pages or thousands, the links work within those pages whether uploaded to a specific webserver. Using absolute links, the inter-page links would not work until the pages were mounted on the specific webserver/domain for which they were exported.
I don’t know what the Python app is or if it has any documentation as given the complete context it might be quicker/easier/cheaper to fix the Python app than Tinderbox until we have more info. I’ve only done a little Python (and an not expert with it) but surely one could write an extra Python library to handle the path issue? How/where/why is the Python app breaking?
@satikusala, it has indeed. I will write you so we can catch up.
The idea of using the IDs occurred to me as well, but since this is for a documentation-styled site, I would still need to use the path to create human-readable slugs, after all, site.io/bibliography/bibtex seems more readable than site.io/1653940245/1653940255 (not that I would mind too much having the second, but I think the first option is the norm).
@mwra, I am using a form of redirection to allow sub-notes to be linked. A note exported as part of another note (a child note) will also be exported independently (but empty and un-listed) to allow link-to-section. The links to the empty notes get edited so that they will link to collect_if(ancestors(this), $Prototype=="Post", $HTMLExportPath) + # + the note name (that is also the section id in the full post). I think It would be tricky to achieve this using relative links.
Moreover, the mkdocs documentation states that all links need be relative to the root folder /docs/. Tbx links need to be edited if I am not to change the root folder of the site (Tbx adds a forward slash in links so this would create site/docs//note 1.md).
I think that if Tinderbox could support a system/local attribute to allow all links to be exported relatively to a single base path, it would be helpful and this would go a long way toward turning Tinderbox into a useful tool for writing documentation using static-page generators. Could this be considered, @eastgate?
(To be clear: I managed to get it working properly, so no real change is really necessary for this to work. But it seems like it would be a sensible addition.)
Thanks for all that useful detail. What confuses me is the need to use MkDocs to make a documentation site when you can do this doing Tinderbox. I offer aTbRef as an example of that. Admittedly, it doesn’t use Markdown but only because there is no need. So, is this issue driven by an eversion to working in/with HTML?
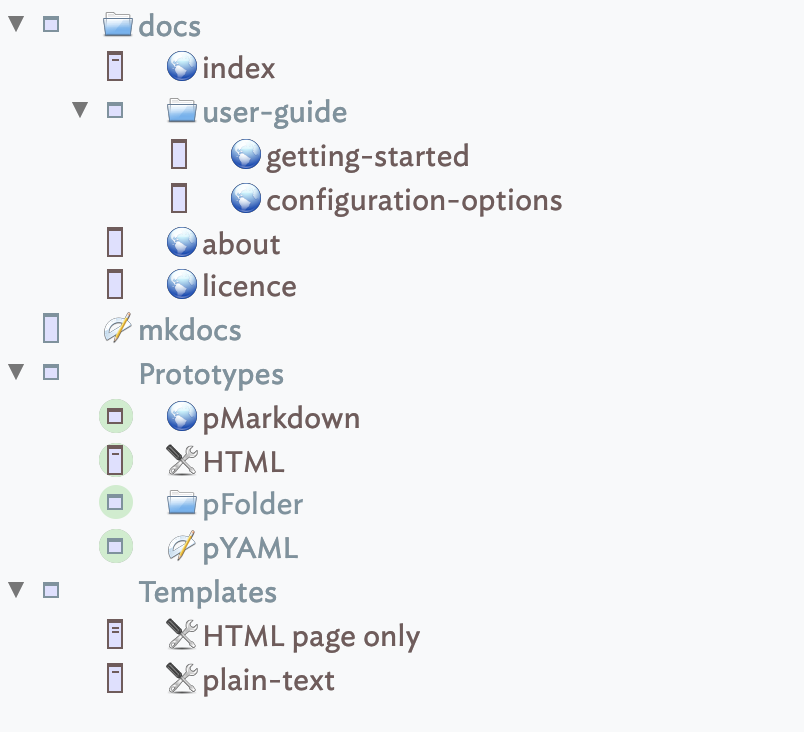
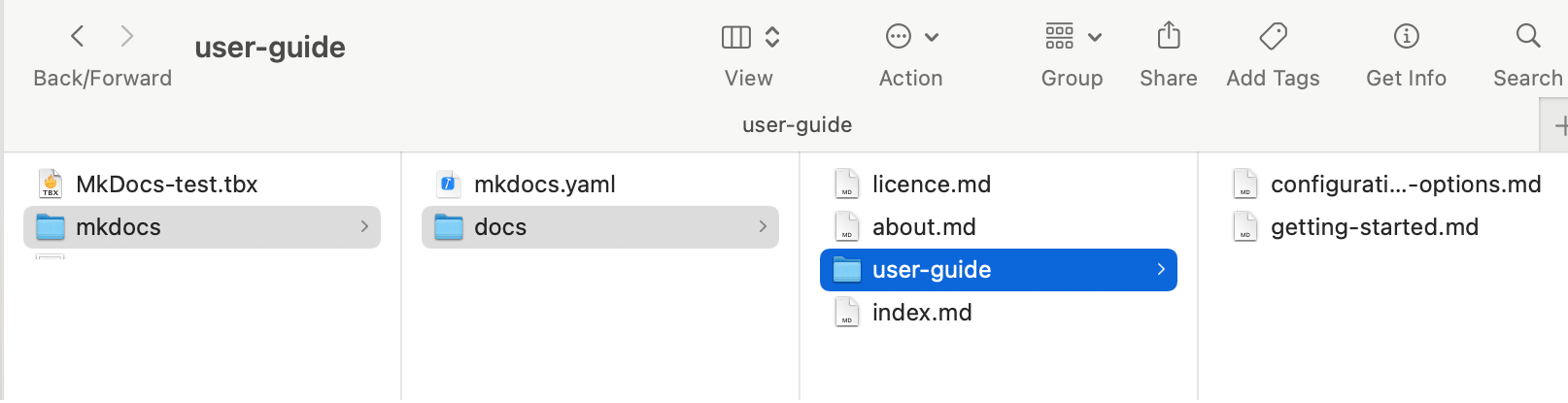
MkDocs seems hobbled by its need to have a root storage folder as a fixed part of its structure. More normally (I wrote my first web pages in 1995 web it was all static), the root of the site has at least an index page and then folders containing other content. MkDocs forces a folder to exist above this as part of the layout which is an unhelpful arbitrary inclusion causing the issue it does. But, have you tried making a TBX with only a single container note and a note exporting the yaml then all the site content inside that. MkDocs wants this:
… and here the specimen output (zip file): mkdocs.zip (2.5 KB)
Aside from any future Tinderbox changes (e.g. due to feature requests), it looks like you can do this now. As to Markdown content in the above I’ll leave that to Markdown as I don’t use Markdown in my own work so have limited knowledge of its edge cases.