Hi all,
I’ve been using the Tinderbox MCP server (thank you for creating this!) and finding it very useful. I wanted to raise a discussion about a gap I’ve noticed that affects users who work primarily in map view with visual/spatial organisation.
The Problem
The current MCP tools work beautifully for outline-based workflows. The get_notes tool allows for searching/querying which works well when your organization is captured in the outline hierarchy. (or when you’re looking for a single note).
However, I use Tinderbox primarily as a visual thinking tool. My workflow typically looks like this:
-
Create a container (or use an adornment) for a topic
-
Add notes inside it
-
Arrange them spatially in map view—grouping related ideas, creating visual flow, using proximity to show relationships
-
Use color, badges, and note sizing to add semantic meaning
-
Refer to this visual layout while writing in another application
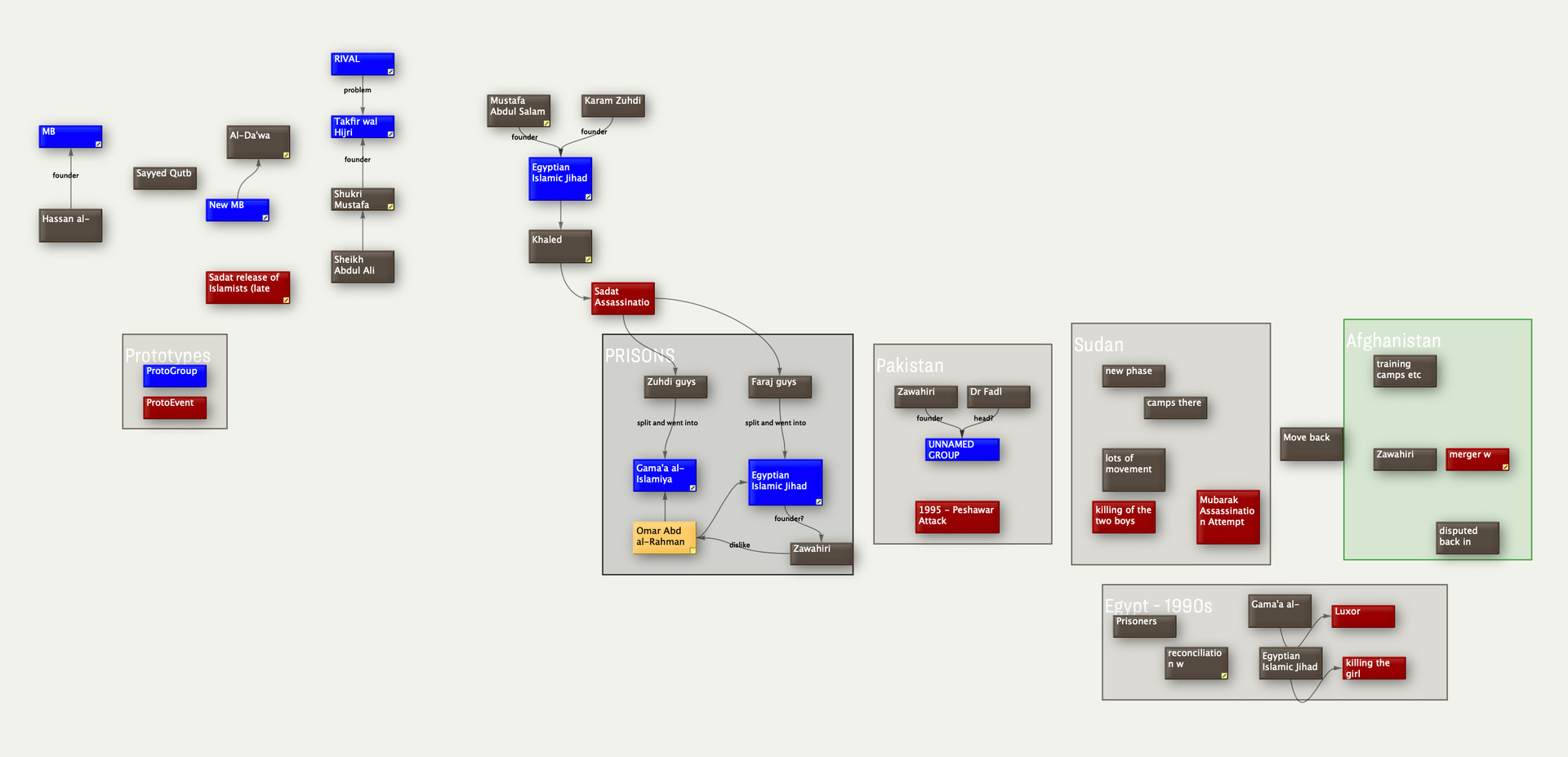
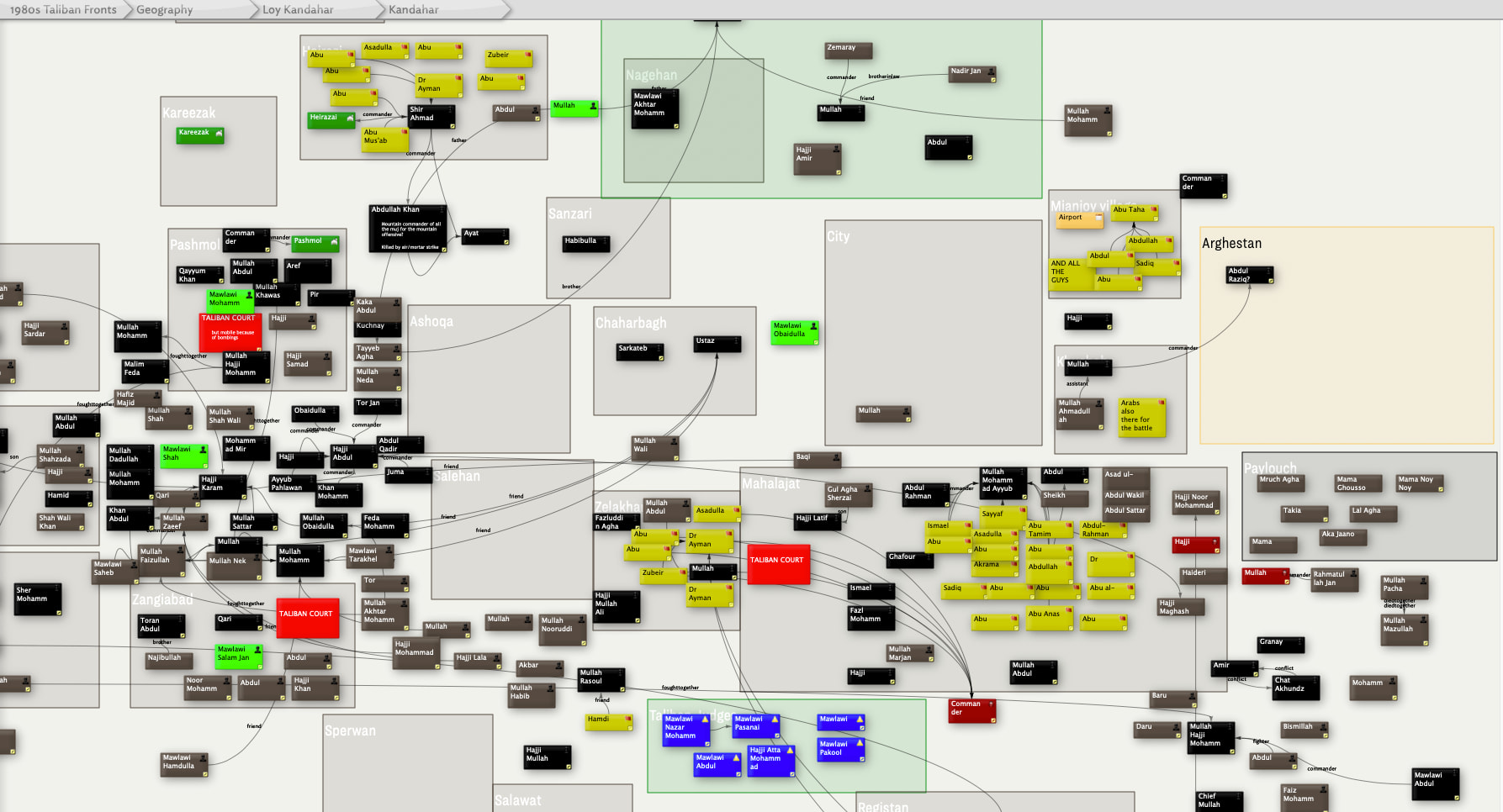
The crucial point: the meaningful structure exists in the spatial arrangement, not in the outline hierarchy. When I’m in a container with 50+ notes carefully arranged on a map, the outline view just shows me 50 flat siblings with no indication of the conceptual clusters, flows, or relationships I’ve created visually.
Current Workaround
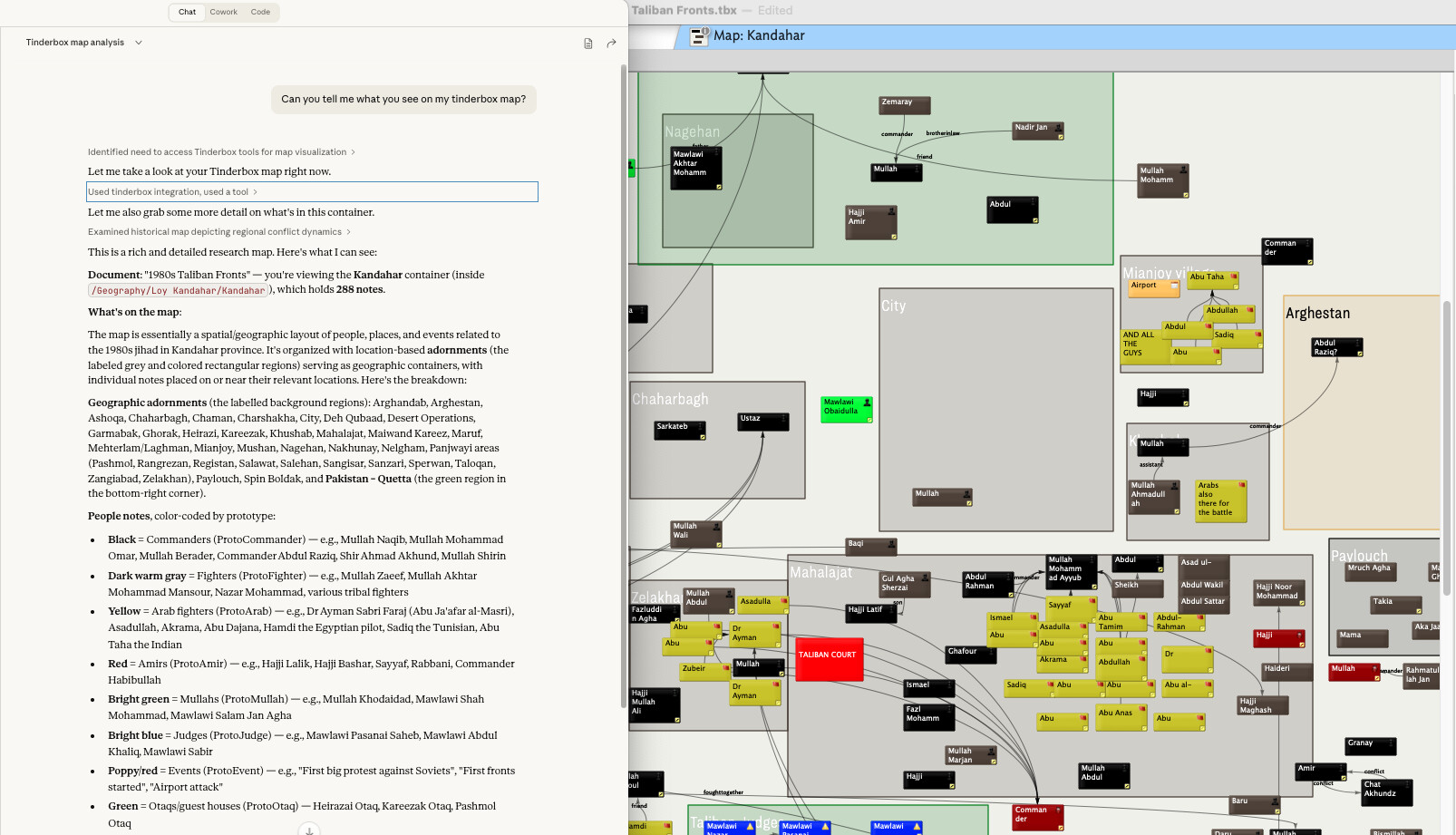
Right now, when I want Claude to understand my visual organization, I:
-
Take a screenshot of the map view manually
-
Paste it into Claude (Desktop or Claude Code)
-
Then use the MCP tools to query specific notes Claude can now identify from the visual context
This works, but it’s clunky and breaks the flow.
Proposed Solution
Would it be possible to add a screenshot tool to the MCP server? Something like:
get_map_screenshot(container_path, zoom_level?)
This would capture the current map view (or the map view of a specified container) and return it as an image that the LLM can process visually.
Technical Considerations
I realize there are some complications:
-
Resolution/zoom: If you zoom out too far, note titles become unreadable. Perhaps there could be a zoom parameter, or the tool could capture at a standard zoom level where titles are legible
-
Map size: Large maps might need multiple screenshots or some intelligent cropping
-
What to capture: Current view vs. “the map for container X” (they might differ if the user is looking at something else)
I’m not sure exactly how the MCP server is implemented, but since Tinderbox can generate images for export, perhaps there’s a way to leverage that?
Why This Matters
The visual/spatial arrangement in Tinderbox maps carries semantic meaning that’s invisible to text-based tools. Features like:
-
Proximity: Notes placed near each other are related
-
Clustering: Groups of notes on adornments or in spatial regions represent concepts
-
Flow: Left-to-right or top-to-bottom arrangements often show sequence or progression
-
Visual hierarchy: Larger notes, different colors, or prominent positions indicate importance
All of this is lost when the MCP can only see “here are 50 sibling notes in this container.”
Question
Are there any plans to add visual/screenshot capabilities? Or if this isn’t on the roadmap, would this be a welcome contribution? I’m happy to help test or provide feedback on what would be most useful.
Thanks for all the work on this! It’s already basically my gateway back into using Tinderbox heavily again. I stopped using it as much because it was incompatible with my team at work etc, and exporting back and forth between Notion or whatever the team uses was too disruptive, but with the MCP server I have no such problem any more. I can live in Tinderbox (as I prefer to do) just fine and then my MCP client can pull things out as I need.