Hello,
I’ve been consolidating a large library of notes. It so happens that some of these notes have references in the $Text that I would like to bring up into the Attribute of CiteKey. I am able to make an agent to find all of the instances of (@word) with a few false positives (email addresses). However, I’m at a loss as to how to then use these results to grab the required information into the Attribute. There are 700 of these, and it isn’t something I relish doing by hand.
Thanks,
Maurice
Try this stamp on the notes:
$CiteKey = $Text.replace("^.+(@[^ ]*)[^@]*",$1);
The presumption is all target strings start with an @ symbol and contains no spaces. Furthermore, if there are multiple references, this returns only the last match.
Thanks so much for the swift reply.
Strangely, I’m getting the text of the entire note this way.
I realize that in my initial posting it may be ambiguous. My @Jones1994 cite keys are
not wrapped in brackets ala pandoc. But simply in the text. I’ll investigate the regex further…
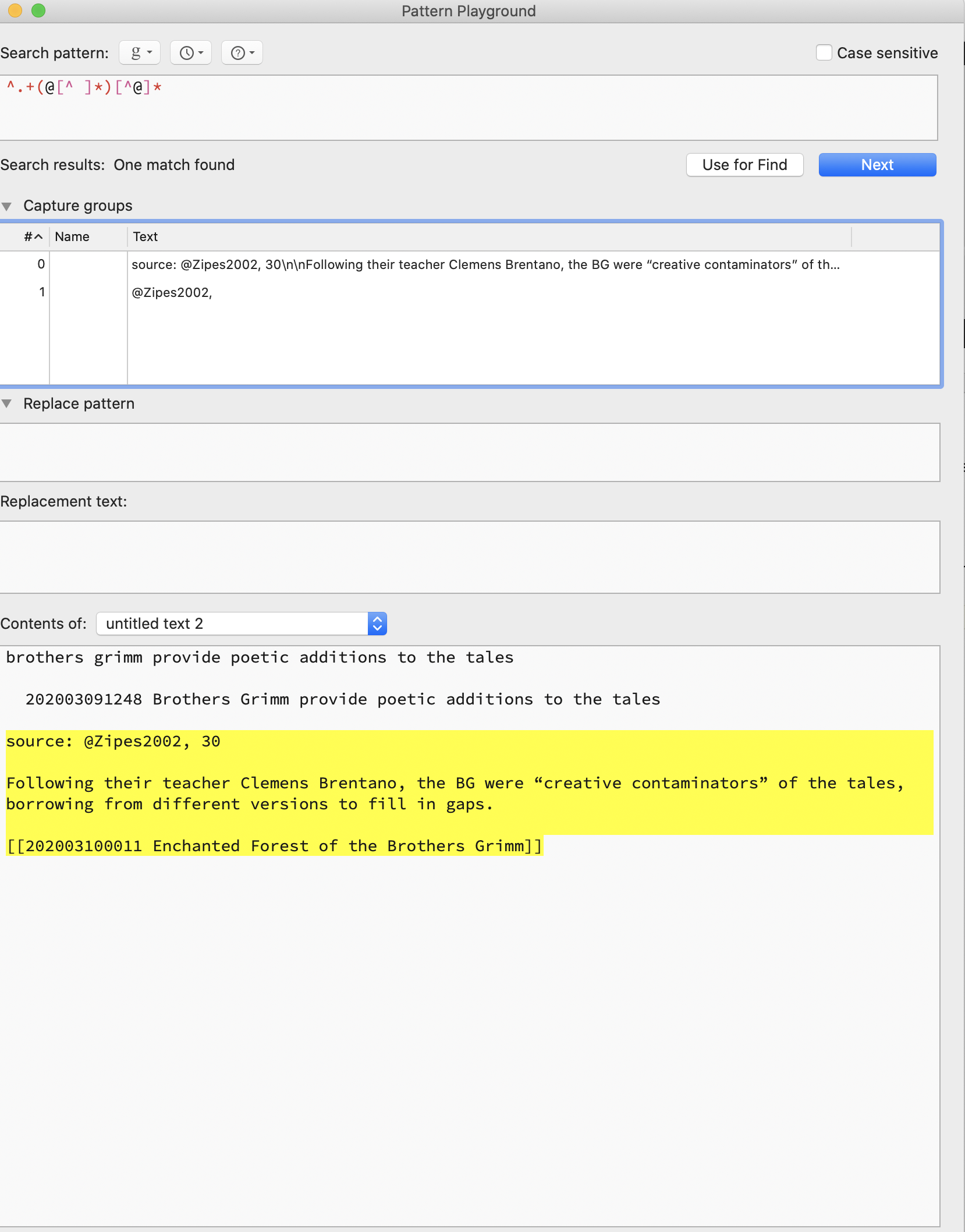
As you can see above, it’s correctly parsing the @Zipes2002, into group $1 in BBEdit. Hmmm
Pandoc, BBEdit, etc. are not exactly irrelevant here. You next to consider how regex work in aTbRef.
could you post 3-4 examples of the full $Text of notes you are testing (re-typing from a screen grab could introduce transcription errors). Or, upload a small TBX with notes with example text.
This does a bit better:
$CiteKey = $Text.replace("^[^@]+(@[^ ]*)[^@]*$",$1);
But the page reference is missed off. Anyway, your example above shows there is enough ambiguity in your source (e.g. @Jones1994 vs. @Zipes2002, 30 (plus other variations?) that you need to test on a number of examples before trying to run against all 700 notes. You also need to know if there is more than one citation per note. Also, should the @ be included in the recovered text.
This taks loos as though it should be resolvable, but not without a better clarification of the variations in the target $Text.
It may be you need to to a multi-pass extractions, e.g. find each sentence or paragraph holding a reference, passing that to a string attribute and then extracting from that. Without a clearer description though, it’s hard to say. Regex are very precise which works against we the user if we don’t have a clear an unambiguous definition of the target string (and possible confounding factors).
Thanks, actually the second regex does work a bit better. And your point about multipass extractions makes a great deal of sense. The notes are irregular in pattern, volume and page numbers and the like add to the messiness.
Actually, this clarified something important for me. I’ve been uncertain whether or not to keep the $CiteKey and $Pages in a separate attribute. And this makes me think I was wise to separate them.
I’d also like to lop off the “@” from the recovered text.
If nothing else, I’ve seen that a stamp is very valuable way to semi-automate something. Thanks very much!
As a stamp runs once per application, and only on the selected item(s), it is a very good test method and avoids carnage if you make typo or such. Once you know the code works, you can move it to something like an agent action, rule or edict. Plus the operator can make sure the target attribute is not altered (by this code) once set.