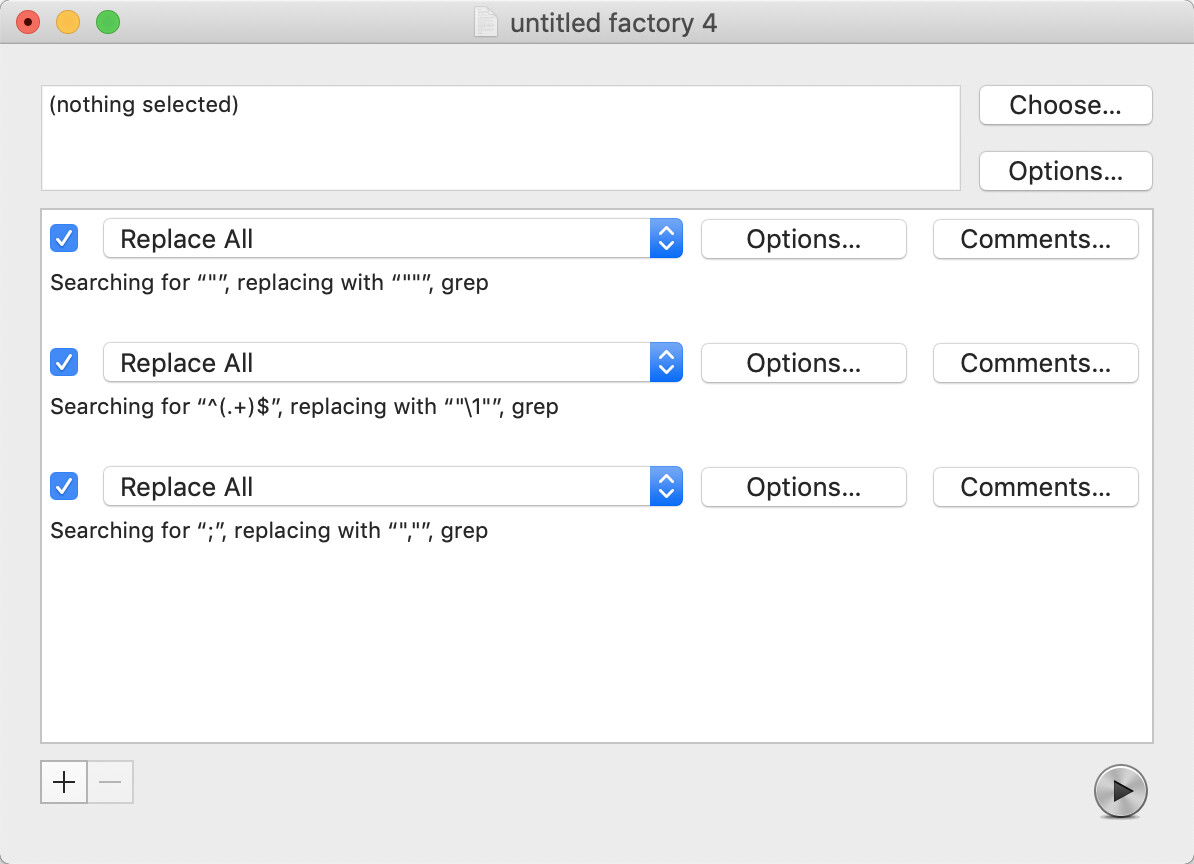
Our starting point is a UTF-8, plain text file, with a header row and a data row:
Name;Quantity;Price;Sum;Note
Floggle-toggle;4,0;2,23;10,52;Used in "Freebies" Campaign
Widget wedge;6,5;3,40;22,10;Out of stock, more due.
The content is chosen to test two issues with which arise when cleaning the format for import:
- Some table fields contain a comma, both in numerical and textual fields.
- Some fields contain straight-double-quotes.
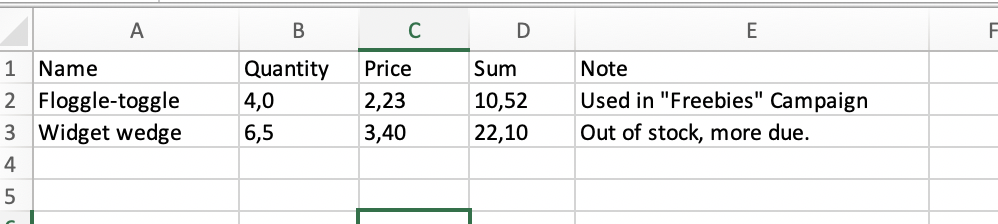
This data might look like this in a spreadsheet†:
The process needs to use straight-double-quotes to enclose data (cell) values. I could just enclose cells with a comma in them but for consistency it makes sense to apply the same treatment to all cells. However, this creates a problem for cells that already create straight-double-quotes. The technique there is to double each one which acts as a form of escape mark-up.
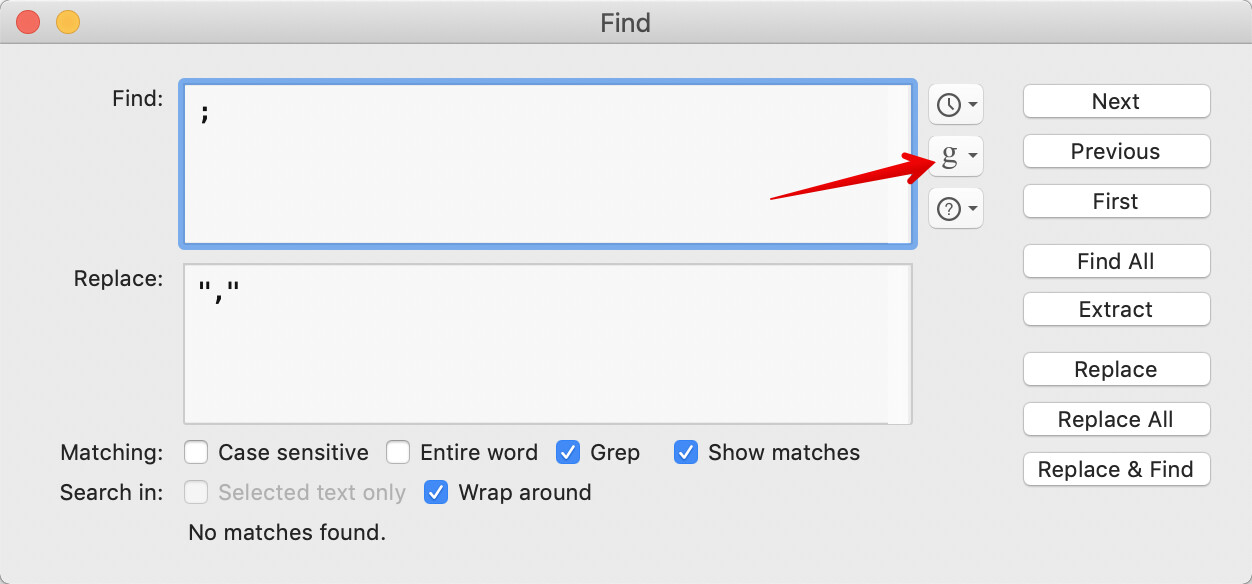
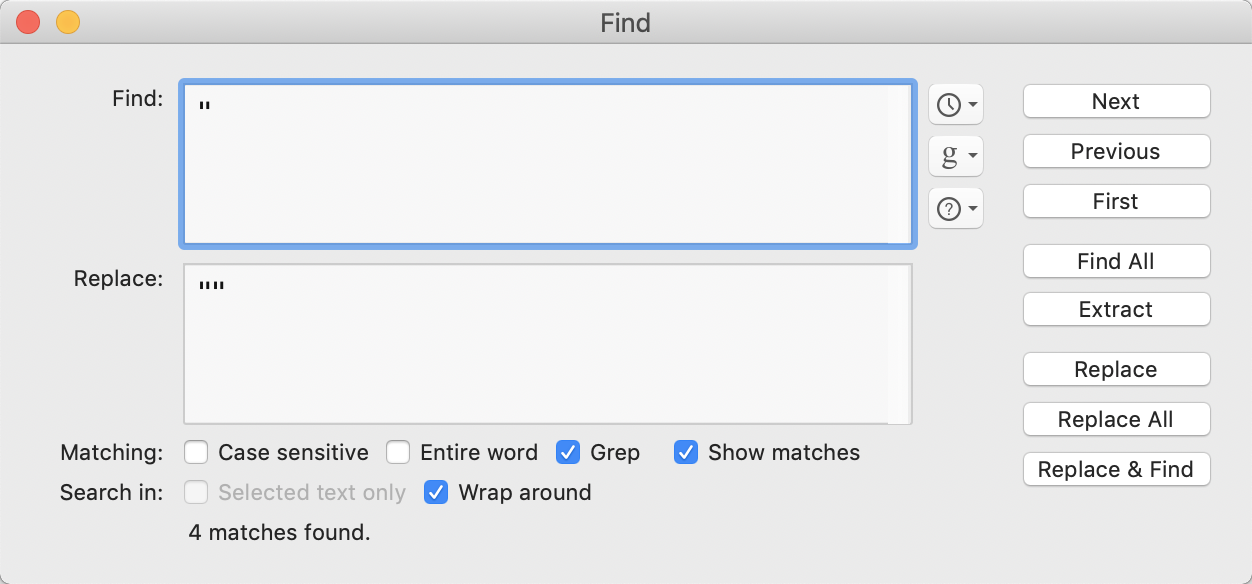
Task 1 - double up existing straight-double-quotes
So
Used in "Freebies" Campaign
needs to become
Used in ""Freebies"" Campaign
and in a bigger test to similar to all such occurrences of ".
The result, seen in BBEdit:

Using these settings:
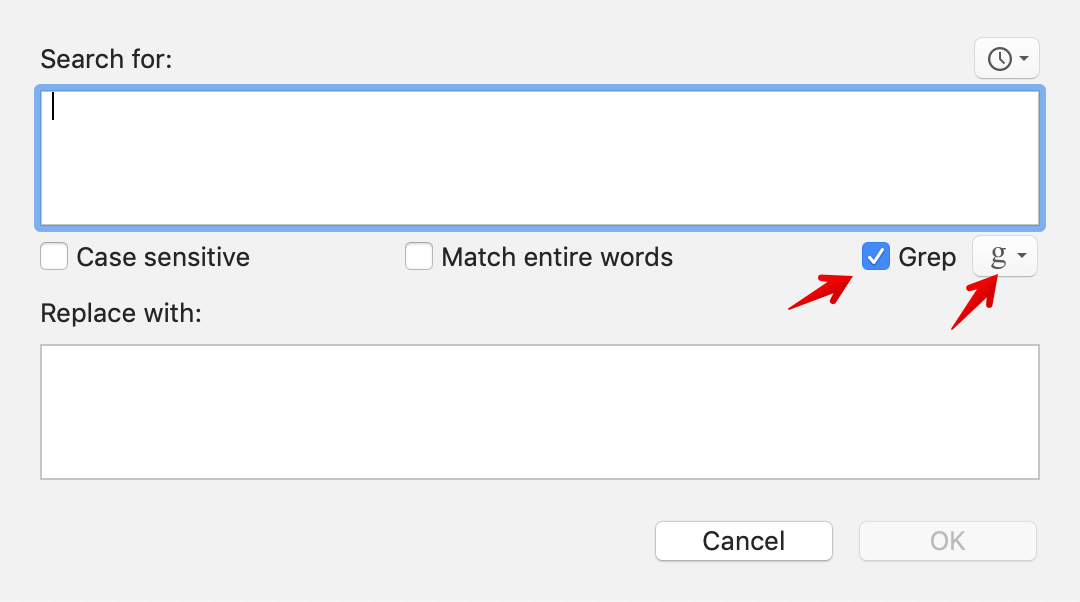
Task 2 - add a straight-double-quote at the start and end of the source data line
Thus,

Using:
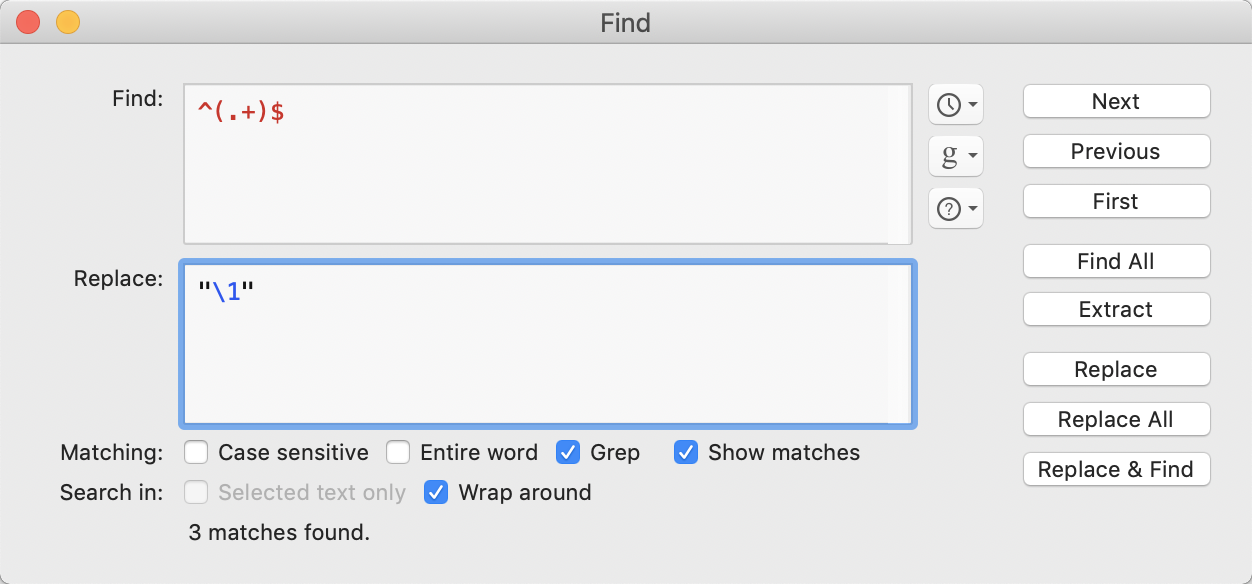
The \1 is a BBEdit back-reference inserting everything in parentheses in the query. So, being line-based, the query matches and references each line replacing it with the existing contents with straight-double-quotes before and after.
Task 3 - replace existing delimiters with commas between straight-double-quotes
The first and last cells per-line have an open or closing set of quotes. We just need to quote all the other cell boundaries whilst also setting the correct CSV delimiter.

using
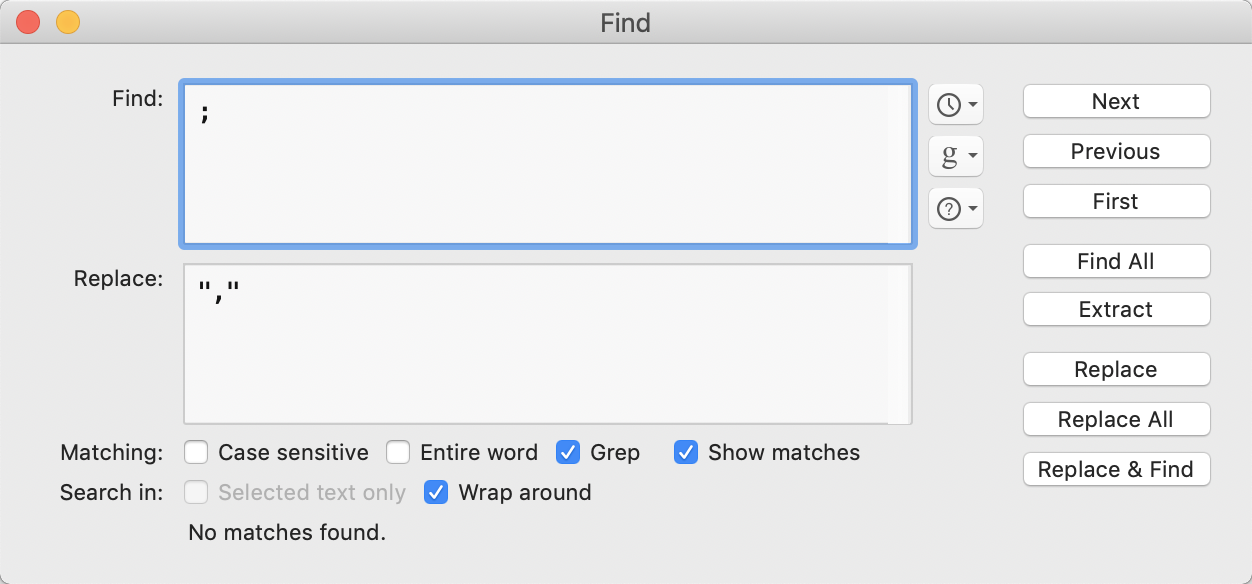
We are done!
I then made a new TBX adding String-type user attributes ‘Quantity’, ‘Price’ and ‘Sum’ and ‘Note’. I used String type so my UK locale system didn’t (as in my first test ![]() ) coerce the German-style decimal-comma into a UK-style decimal-point. I then added a prototype setting those attributes as Displayed Attributes.
) coerce the German-style decimal-comma into a UK-style decimal-point. I then added a prototype setting those attributes as Displayed Attributes.
Next, I dragged in the semi-colon delimited data:

Notice how the lack of normal comma or tab delimiters mean the data is put directly into $Text. Now the ‘fixed’ file is added to the TBX:

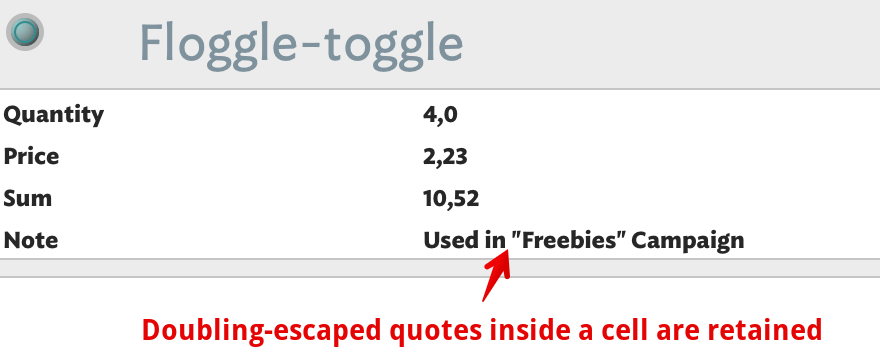
The result is the header row is used to correctly make two new per-source row notes. Note: I set the prototype manually just to help illustrate the process. Notice how the comma in the note is not detected as a delimiter? This is because the contents of the cell was protected by the enclosing quotes. Likewise the in-cell double quotes are retained as they were escaped:
This zip contains the starting data, the ‘fixed’ version (both UTF-8 plain text) and the TBX illustrated above: Delim-demo.zip (29.5 KB)
†. I actually made this by importing my ‘fixed’ file back into Excel (as my settings are for UK), though it took some doing. Drag/drop or paste failed. I had to use data import and even then use non-default settings. As so often with MS Office, they have a different view of norms to everyone else.