Some recent discussion re in-text number markers for footnotes (or numbered citations) raised the issue of having to set these as superscript numbers using ` HTML tags.
But Unicode has number glyphs for this, but trying to remember that a superscript 3 is Unicode symbol U+00B3 is a bit of a trial let alone remembering how to enter that via a keyboard.
function fSuper(iNumber:number){
var:list vSuperscripts = "1:¹;2:²;3:³;4:⁴;5:⁵;6:⁶;7:⁷;8:⁸;9:⁹;0:⁰";
return vSuperscripts.lookup(iNumber);
}; // END FUNCTION
function fSub(iNumber:number){
var:list vSubscripts = "1:₁;2:₂;3:₃;4:₄;5:₅;6:₆;7:₇;8:₈;9:₉;0:₀";
return vSubscripts.lookup(iNumber);
}; // END FUNCTION
This this stamp:
$MyNumber = 4;
$Text = "Super- and sub-script number "+$MyNumber+" for x: \n\t"+"x"+fSuper($MyNumber)+"\n\tx"+fSub($MyNumber);
The above works, but I made some unneeded/wrong assumptions:
calling the function for each source digit. So if you need ‘237’ in superscript, rather than call the function for each digit, why not pass the number to the function?
why pass the number as a number? The function is mapping unicode characters and a lookup (List-type based) essentially uses number input auto-coerced to strings. so why not pass a cstring? Plus in string form, it is easier to work out how many digits there are in the input ‘number’.
So the functions are are now:
function fSuper(iNumStr:string){
var:string vAnswer;
var:number vSize = iNumStr.size;
var:list vSuperscripts = "1:¹;2:²;3:³;4:⁴;5:⁵;6:⁶;7:⁷;8:⁸;9:⁹;0:⁰";
if(vSize == 1){
vAnswer = vSuperscripts.lookup(iNumStr);
}else{
vAnswer =;
var:number vCounter = 0;
while(vCounter<vSize){
// non-numerical items are ignored, e.g. the comma in 2,000
vAnswer += vSuperscripts.lookup(iNumStr.substr(vCounter,1));
vCounter += 1;
};
};
return vAnswer;
}; // END FUNCTION
function fSub(iNumStr:string){
var:string vAnswer;
var:number vSize = iNumStr.size;
var:list vSubscripts = "1:₁;2:₂;3:₃;4:₄;5:₅;6:₆;7:₇;8:₈;9:₉;0:₀";
if(vSize == 1){
vAnswer = vSubscripts.lookup(iNumStr);
}else{
vAnswer =;
var:number vCounter = 0;
while(vCounter<vSize){
// non-numerical items are ignored, e.g. the comma in 2,000
vAnswer += vSubscripts.lookup(iNumStr.substr(vCounter,1));
vCounter += 1;
};
};
return vAnswer;
}; // END FUNCTION
// for more on the characters used see
// https://en.wikipedia.org/wiki/Unicode_subscripts_and_superscripts
// or
// https://en.wikipedia.org/wiki/Superscripts_and_Subscripts_(Unicode_block)
You can pass in any whole number (integer)—4, 569, 2,000—and it will be parsed into numbers. The only caveat is not to pass in a decimal number 4.56will get parsed as456`.
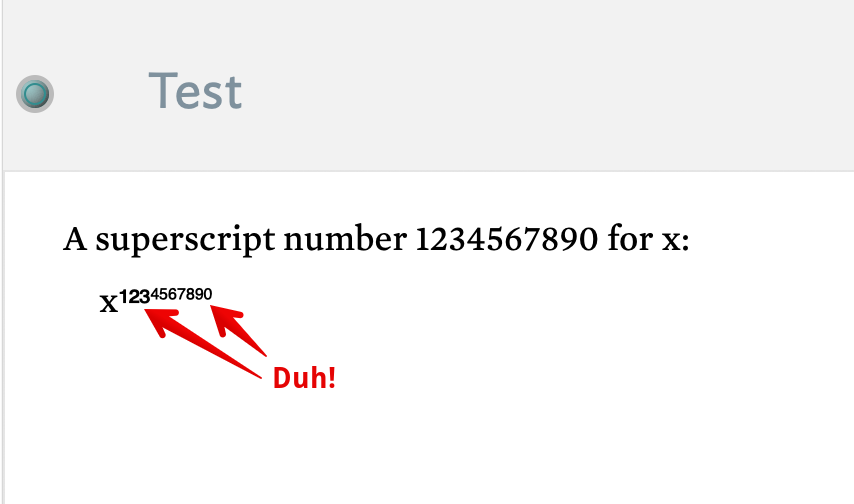
But, ant there inevitably is with tech, because the computer science (Unicode) and designer (font design) groups clearly don’t bother to talk, this stupidity occurs. Sadly, in many common Unicode fonts, upper-case numbers 1/2/3 are in a different size/weight. Clearly, Science and Art do not speak. We are all improverished by such inward focus.
In the next grab (taken in $Text preview mode) the first example uses superscript characters whilst the second used normal numbers inside HTML superscript tags:
Ugh, in the first example the different weight and baseline mean ‘15’ looks like ‘1 raised to the power of 5’.
The unicode designers doubtless though to be helpful by not assigning new code points for superscript 1, 2 and 3 as these pre-existed (duplicate characters are wasteful). Quite why makers of unicode-capable fonts though to use different glyph styling for only three of the superscript characters is a mystery. When the extended super-/sub- script glyphs were codified and added to fonts (which must define each character) it’s unclear why the designers didn’t bother do check the whole 0–9 superscript range together or they’d have seen the stupidity of the current designs. Boo.