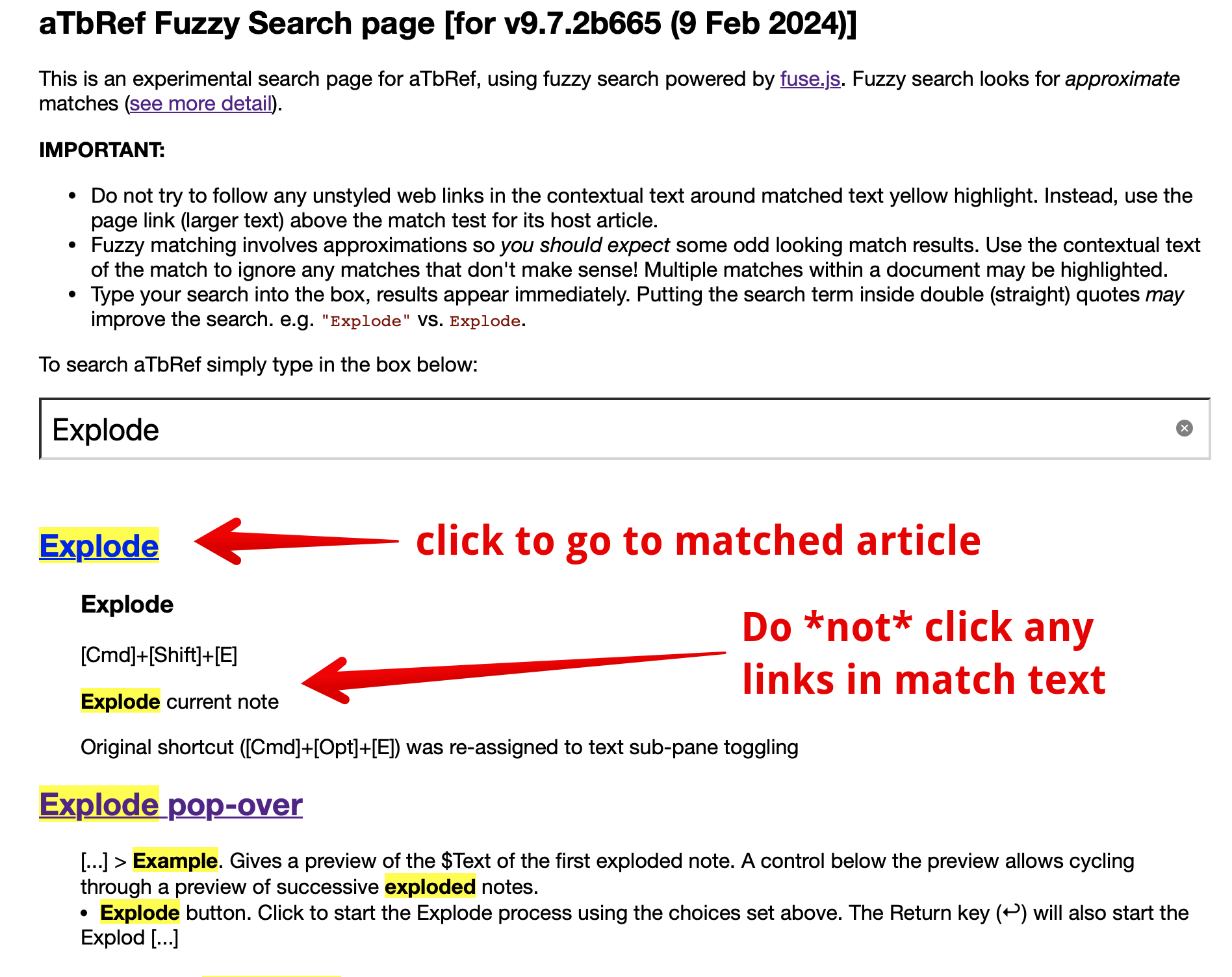
See the new aTbRef Fuzzy Search page (the main TBX zip is also updated). type your search term into the box and you will see a list of URLs for any matched pages each followed by highlight(s) of the matched string and some contextual text from before/after the match.
Unless problems emerge I plan to add a link to this page to the ‘quick links’ at the top and bottom of aTbref pages when the site is refreshes at the next public release (or new baseline).
Notes:
‘Fuzzy’ search uses approximate searching.
Upside, it it might find things a strict search might not.
Downside, you get some nonsense matches. Just ignore them!
Because there is some use of ^export^ code inline in the source notes’ $Text, I’ve indexed the ^text^ of the notes not the $Text. This has some effects:
The note creating the JSON search index takes c.30mins to export unlike the main HTML doc (website) export which takes a few minutes. As a result the uploaded TBX, the JSON note’ export is disabled. I find it better to export the JSON on it’s own after the main export, but the JSON is needed if you are going to use search
There there may be links in the contextual text but (…because reasons†) they don’t link correctly. Due to this I have CSS-styled any such links as normal text (no colour, default pointer, etc.). To see a matched article use the article-named link above the matched text example (see grab above).
Lastly a big thank-you to @jackbaty for the his blog post that give me the idea of trying this sort of search and for a goodly amount of help and advice to get it working.
Annoyingly, fuse.js is one of those libraries that follows the JSON standard rigorously and (silently) fails if any lists have a trailing comma. So if trying this technique and the browser shows the index has loaded but the UI reports the index is not found, check your index.json file for syntax errors.
I tripped on this fact in developing the above search as when doing a cascading (recursive) export of all the content, it turns out to be hard—in Tinderbox export—to tell from the context of a single note whether there is more export to come. The slightly-counter-intuitive fix is to test if one has started, as opposed to finished, exporting and place object/list commas before each newly added item as opposed to after it.
Although simple to use when done, I’d rate implementing this as complex for all but the most experienced user. In principle it sounds like the makings of a demo/tutorial, but part of the complexity relates to what content from the TBX the user wishes to search and it’s relationship in the exported website to the search feature (3 file, HTML, JS and JSON). Anyone needing a tutorial will likely need some 1-to-1 help to set up the customisation for their own use. If only it were simpler!
†. It’s all do do with relative URLs and fixing it for links that aren’t needed is more trouble than it is worth to try and fix. Each matched note has a functional link to that note. The links in the matched text aren’t wanted there but are a by-product of exporting the HTML render of the note.
A couple of extra wrinkles for anyone what to use this method.
It ie easiest to make the JSON index file with the name ‘index.json’ and place it in the same folder on the website as the search.html page that uses it. The minified JS script can live anywhere and called relatively (or simply used inline) by the search.html page. But if the JSON and HTML pages are not co-located you will need to edit the JS file and that isn’t a novice task.
The core of the JSON, for me, is per-note elements like this being made in the export template
If you aren’t worried about HTMl/export code in note $Text, for the content value you could try using ^value($Text.jsonEncode)^. In my version above I’m using exportedString() to get the ^text^ output of text—the entire code in template ‘body_text_only’ is just `^text^. The resulting JSON index file is c.4.3MB for aTbref. The search is surprisingly fast - results appear as you type your search.
The minified text can by ‘pretty-printed’ to at least give back line breaks an indenting to see code-flow. Online resources such as https://unminify.com can do this. But the minify process is lossy, you can’t have back all the meaningful variable and function names used in the original source.
In the minified JS you can see where some of the fuse.js options are set. Note that !0 is minified true (saving all of 2 characters per use!) and !1 is a short form of false, noting that JavaScript boolean value are case-sensitive.
I did experiment with the fuse.js options (as in #3 above) but they appeared to make no difference to the quality of search—apart from breaking it entirely in some cases.
It is a bit weird, some of the fuzzy matches look bizarre. But it is fuzzy search and it is easy to ignore them.
If using an absolute URL for the url data (see code above) you could in principle have search deployed on another server and pointing to matches on a different server.
I’ve now got a new variant of the existing fuzzy search and would like people to compare the two and give some feedback (see links below). The primary difference is this new version uses data for the JSON export drawn from a notes’ raw $Text and not the HTML-processed ^text^. It cuts the export for the JSON index note from c.30 mins to c.1 minute (it is exporting 99% of the whole TBX content), so it is a non-trivial improvement if the search experience is as good.
A reasonable test is to open both pages and use the same ‘Explode’ search string in each one.
I think the experience for the user is as good. The matches should be the same and the difference is in the matched text examples where there is less (CSS) formatting in the text sample. Also missing in the new version are faithful source paragraph breaks. Some styled code examples still show due to my use of literal HTML tags in the source $Text (these pre-date the now-built-in HTML export detection of ‘code’ font use†).
It is likely the new version will be the one adopted unless we find new gremlins. Feedback here is fine, noting that we expect some odd matches due to fuzzy search so do not report those.
[Site’s TBX zip is updated]
†. I’ve not used that yet in aTbRef, as adoption means >950 notes to review/edit (for consistent usage) for no visible gain!