Glad you’ve got a solution. Aside, it is easiest with this sort of problem—because written language can be ambiguous—to give deliberate before and after examples, i.e. the source string and the part(s) to be saved as discrete values. So in my test case above:
Source: https://example.com?=123
Result: 123
URLs can be quite variable so knowing the exact target can help fellow users here not only solve the test case but to do so in a manner that spots and avoids edge cases (URL variants) when in actual use.
For instance, returning to the thread above for an example, you note you actually wanted to “grab the latest segment after the latest slash (a.k.a, the page name)” so my test was insufficient as the URL—after the protocol part—had no slashed. So perhaps we need a test source URL like:
https://example.com/foobar/index.html?page=123&ref=34
but even then, do we want to capture /index.html?=page=123&ref=34, index.html, or something like list[index.html;123;34]. So for the example just above:
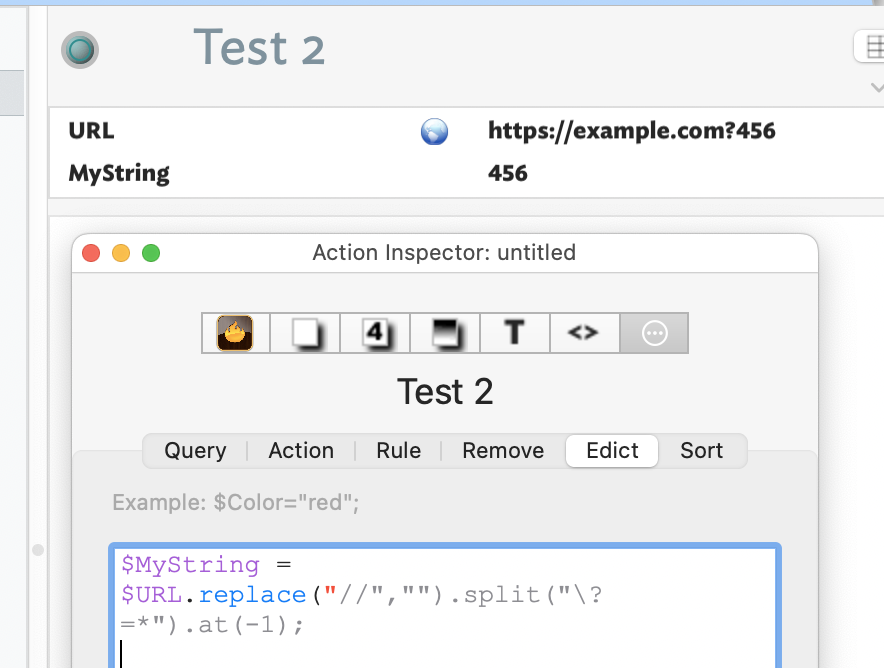
var:string vString =;
var:list vList1 = [];
var:list vList2; = [];
// get a URL without double slash
vString = $URL.replace("//","");
// get list item #0, URL; item #1 (or #-1)query args
vList1 = vString.split("\?=*");
// get last part of URL
$MyString = vList1[0].split("/").at(-1);
$MyString now has a value of ‘index.html’.
Or at the end, if we split the variable vString on slashes:
// get last part of URL including args
$MyString = vString.split("/").at(-1);
$MyString now has a value of ‘index.html?page=123&ref=34’.
Computers are in that sense dumb: you have to ask the right question and in a form that does not allow for a different interpretation of your intent. Within action code, parts using regular expressions (‘regex’ pattern matching) these are similarly frustratingly narrow in their understanding. It’s a constant reminder of the human mind’s ability to resolve—by context—ambiguities which completely confuse a computer.
The previous example file with some new tests:
url-split1.tbx (109.6 KB)
HTH