PS Jump to Solution for no read-up
History
I am a huge fan of voice notes , they allow freeform stream of consciousness , epic brain dumping sessions really quickly. I have never been satisfied with solutions available , I have tried DragonNaturally Speaking but they’ve left OSX , SIRI which has been worst after iOS15 for Indian Accent but can be trained as it pick up words from your Address Book to spell correctly , Google Pixel horrible as you cannot teach it any word , Otter.AI good but teaching it custom words (more than 200 words) requires Business plan costing $30 a month .
I caught hold of MacWhisper & WhisperScript for OSX two months back, both 15 euros each , very accurate and it’s trained on tonnes of real life data , it picks up Indian accent very well. Teaching new words still not possible.
Whenever I say ‘tailor’ , Whisper.AI pickups up ‘Taylor’
MacWhisper in particular has a function called Search & Replace which allow you to enter words it gets wrong and replace it .
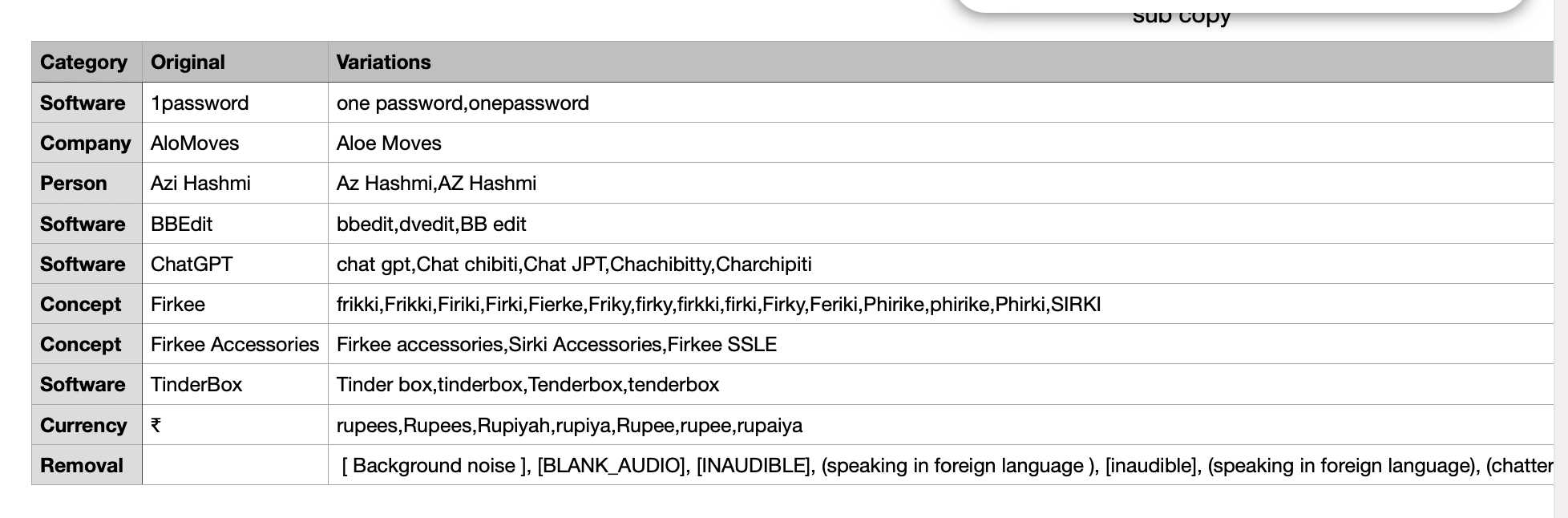
One of my company is Called Firkee and based on how I pronounce it Whisper.AI can transcribe it as
frikki,Frikki,Firiki,Firki,Fierke,Friky,firky,firkki,firki,Firky,Feriki,Phirike,phirike,Phirki
As you can imagine Search & Replace became very tedious quickly , and no CSV export / import facility .
Enter chatGPT
It suggested a python script can help with this , after few trial and error , we have a working solution . It iterates though a CSV file containing word and all it’s possible substitution
Format of CSV
Original Word | Substituion with Commas
Firkee frikki,Frikki,Firiki,Firki,Fierke,Friky,firky,firkki,firki,Firky,Feriki,Phirike,phirike,Phirki
Firkee Accessories Firkee accessories,Sirki Accessories,Firkee SSLE
Meeplecon meepilcon,Mepilcon,meeplekorn,meeplecorn,AppleCon,Meepil Con, Meepil Con,nipple corn,nipplecorn
aTbRef ATB-REF,atbref,ATBREF,ATB ref,ATB ref
WORKFLOW
- Record with Apple Voice Note
- End of Day transcribe file with MacWhisper (I like it better than WhisperScript,even though both are identical)
- Run the Python script with substitutions from CSV file
- Update CSV file for new words Whisper.AI got wrong
- Dump in Tinderbox to work further or even summarise with ChatGPT for getting structure to send to my assistant.
It sounds complex but it came up very organically , incremental formalisation as Mark Anderson puts it.
Limitations
- We have been using it for even recording meetings notes and it works for 2-3 people. There is no speaker diarization (or I don’t know yet)
- CSV is the key and it has to be personally cultivated to your lingo
- No automation I know of to automatically transcribe voice note on my Mac automagically after I do a voice note , I know there are ways to do it using Whisper.AI and it’s api but I don’t know how to(send voice note to Whisper.AI from iPhone).
Hope this helps someone.