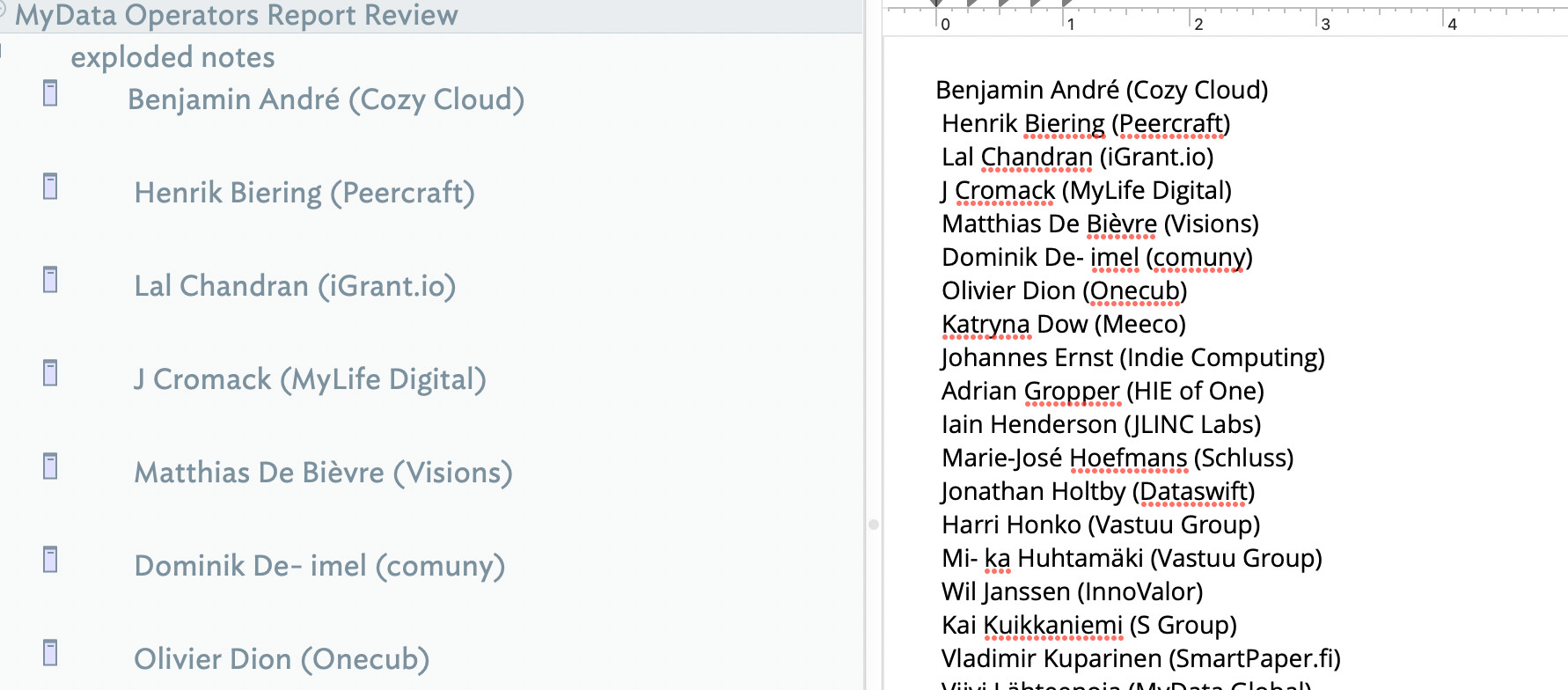
Any idea why my names are getting the extra link break? What would you suggest as the action to make this stop?
Also, I’m having trouble figuring out the RegEx for the following action. When I explode the text I want the Name to be the title, the info between the ( ) to go into $Organization and the ( ) and the space after the name to be deleted. Ideas?
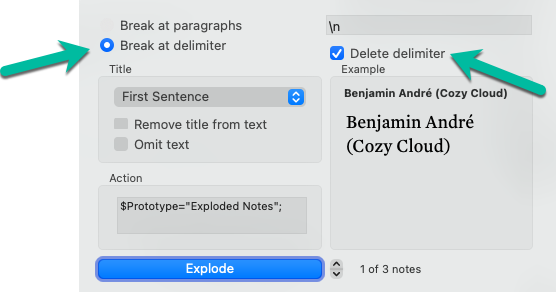
I’ve figure out how to remove the extra line break. I just have to delete the deliminator. Pretty obvious now that I think about it. I’m still struggling with parsing the data, though.
Does Tinderbox support something opposite of .replace? For example, I figure out the regex to copy the text I want e.g. (?<=().?(?=)). This copies the text between the ( ). But, I don’t want to delete it, rather I want to use it and put it in an attribute. As for getting the first name, I have the regex get that too, ^[^(]. I can run a grep command to get that, runCommand(“grep -o ‘^[^(]*’”,$Text);, but I can’t figure out how to delete the trailing space. Ah…so close and yet so far away. :-).
Now what I want to be able to do is automatically remove the trailing space on the name and delete the ( ) in organizations. Can’t figure this out at all.
You’re right - you caught me as I was turning in. After more testing this works for me as the $OnAdd for the ‘exploded notes’ prototype. IOW, Explode as above but with no action. The $OnAdd is:
Sure, great question. When you go to explode a note, go to the Note Menu and select Explode, in the corresponding popup you can have Tinderbox delete the delimiter after it explores the note. I’ll do a video on this once I ask Mark a couple questions. I need some help for the advanced Part 2.
It would be better to either (a) paste the text to be exploded here, or (b) put the note you want to explode into a Tinderbox document, and share the file here.
The less time people have to spend to reproduce your problem, the more time they can spend solving it.
(In the interim, there new .trim() operator might be helpful.)
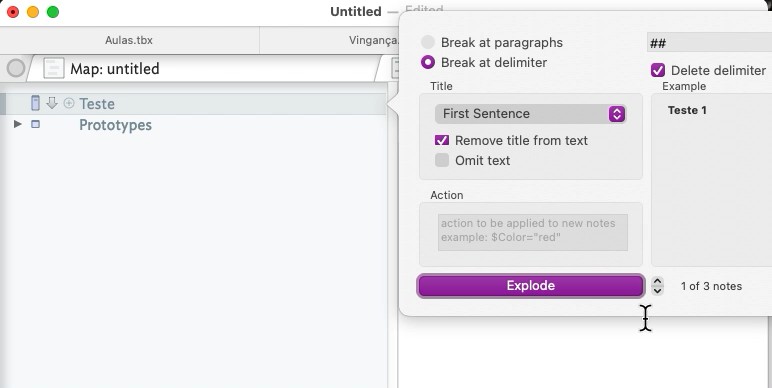
The fact the titles wrap for ‘Teste 1’ and ‘Teste 2’ would suggest you delimiter is not working as imagined. Sadly in your first screengrab of the test file, the o=pop-up coders the source text, so we can’t se what actual $Text you are exploding.
Can you upload your test document? The result suggests there is other content (non-visible characters?) that are throwing off the result
Noodling around, I do observe that in text link this, the title is being chosen to include the closing carriage return. That’s probably undesirable.
It’s easy to use .trim() to get rid of the undesired return, but I wonder whether Explode should implicitly trim whitespace before and after the title.
OK, you’re using ‘first sentence’ except your titles (to be) have no sentence as such - i.e. no terminating punctuation. Use ‘first paragraph’ and all this goes away. If I look at your original screen grab your markers they are single unpunctuated titles, i.e a single ‘paragraph’ of text.
The Explode set-up didn’t survive in the test do but I’d note your custom explode delimiter is two hashes and a space ‘## ’. If you omit the space, your titles retain the space for the original text at the start of the exploded title. currently, that isn’t auto-trimmed. Regex are very precise in that manner
@eastgate, some old issues seem to have crept back in that titles aren’t being extracted correctly. I recall this was an issue but then got fixed (until now!). I amended the test note $Text to;
## Teste 1. More stuff.
## Teste 2. This stuff.
## Teste 3. That stuff.
Exploding on a removed delimiter of ‘## ’ and selecting ‘First sentence’ as the title, and removing titles from text, I get correct titles , e.g. ‘Teste 1.’, ‘Teste 2’, etc. but the $Text in each case is missing the first character. So the $Text of exploded note ‘Teste 1.’ is:
ore stuff.
but it should be:
More stuff.
Odd, but I guess it possibly connected with the ‘sentence’ detection algo.