I’ve set up a Tinderbox file for annotations, and I’m trying to figure out an approach for color coding notes depending on the type of source material. I use three main types of source material, namely: articles (academic or news); documents (government reports or studies); and interviews.
A little background… When I annotate a file, I import into Tinderbox as a folder (that has the same naming convention of the original file) and contains notes for each annotation. IOW, if I annotate a news article titled “Dog Bites Man,” I would import a folder with the following naming convention: REN_2022_05_04-Dog Bites Man (“REN” refers to rendered - and the original, unannotated file would be ART_2022_05_04-Dog Bites Man.) The REN_2022_05_04-Dog Bites Man folder would contain discrete notes for each annotation based on that article.
Anyway, I’m trying to figure out the best approach for identifying and labeling these my annotated files as articles, document or interviews. My first thought was to change my naming conventions (e.g., REN_ART_[date] for article; REN_DOC_[date] for document; REN_INT_[date] for interview), create an attribute for file type with a list data type (i.e., for article, document or interview), and create code that would read the folder prefixes, and set values according to their folder prefixes, and then color-code the notes, accordingly.
I’m curious what the community thinks of this, and if there might be another, suggested approach worth considering.
I expect I’m missing some elements or making some errors, but this is what I was imagining for a kind of code that might work for what I’m seeking – based on what I’ve described in my post (above)…
An obvious question to ask is what you are intending to do with this material after you’ve imported it into Tinderbox. That might influence the strategy you adopt.
If I were doing this, I would just have a prototype for each category.
You might find it useful to look at Dominique Renauld’s posts about this sort of thing. He made a few videos about his process. I can’t find them right now.
Thank you, @MartinBoycott-Brown. I’ve already got a stamp for my imported notes, a prototype for those notes – which creates relationships between my predefined list of attributes and values – and set of agents set up for select attributes.
I’m just seeking a color coding solution that’ll help me differentiate notes according to whether their file’s source material was an article, document, or interview.
Thanks, @eastgate. To back up a moment, I’ve created a prototype for my annotated notes. When I apply a stamp to my annotated notes – which includes the code: $Prototype="pNotes"; – it creates relationships between my predefined list of attributes and values.
I suppose I could duplicate the same prototype, and tailor them for Article, Document, and Interview – and assign each prototype a color.
I’m still trying to understand how OnAdd works. But I’m not sure it would work with my set-up. Based on the process I described, do you think I could still use OnAdd or is there another solution for applying prototypes that can inherit color-coding the annotated notes?
A prototype can itself have a prototype – I find it can be quite useful to have cascading prototypes in certain cases.
And it is always worth adopting strategies that don’t paint one into a corner. If one’s understanding of the material alters over time, it is good to have a setup that can be changed to accommodate that. I think this is where attributes and metadata generally allow more flexibility and extensibility than using containers. Attributes are incremental, whereas putting items in a container is a kind of all-or-nothing approach. Though it also has its uses.
I actually had no idea this was possible! Now I have to search for these examples to understand how I might be able to apply this to my own set up.
I certainly agree, and appreciate that point. Right now I’m still trying to understand how to make Tinderbox coding work. For instance, I don’t know if the code I drafted above will work – or if I’m missing some key aspect of assembly.
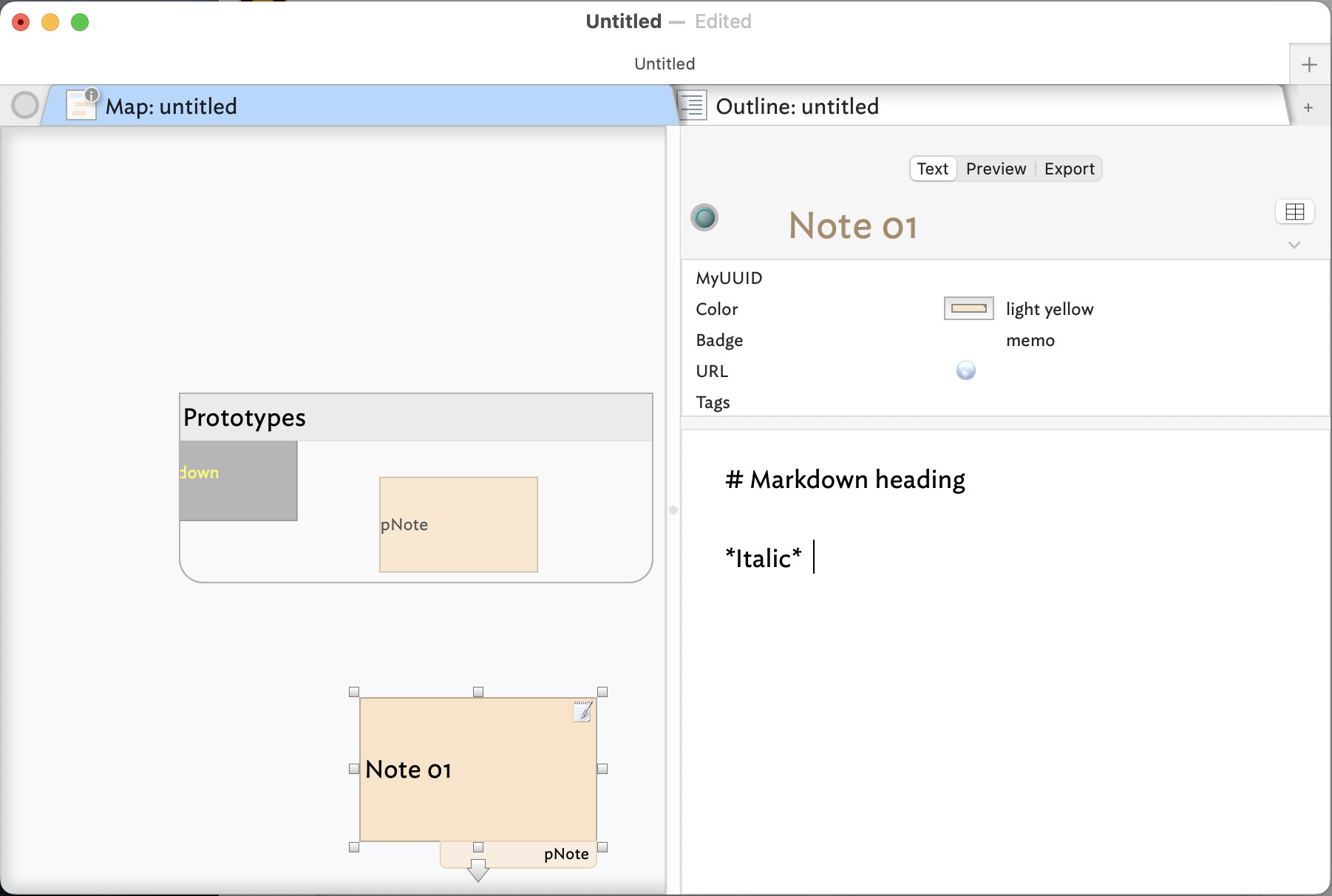
Because I write in Markdown quite a bit, a fair number of my prototypes have the Markdown prototype as their prototype (if you see what I mean – it gets confusing to write “prototype” all the time). And in the past I have sometimes used a cascade where I wanted a prototype to “benefit” from the attributes already in another.
Thanks! I’ve been trying to find posts that illustrate what you’re talking about. Are there particular examples that you can refer to? I’m just trying to see what this looks like and how it works. Thanks for your help!
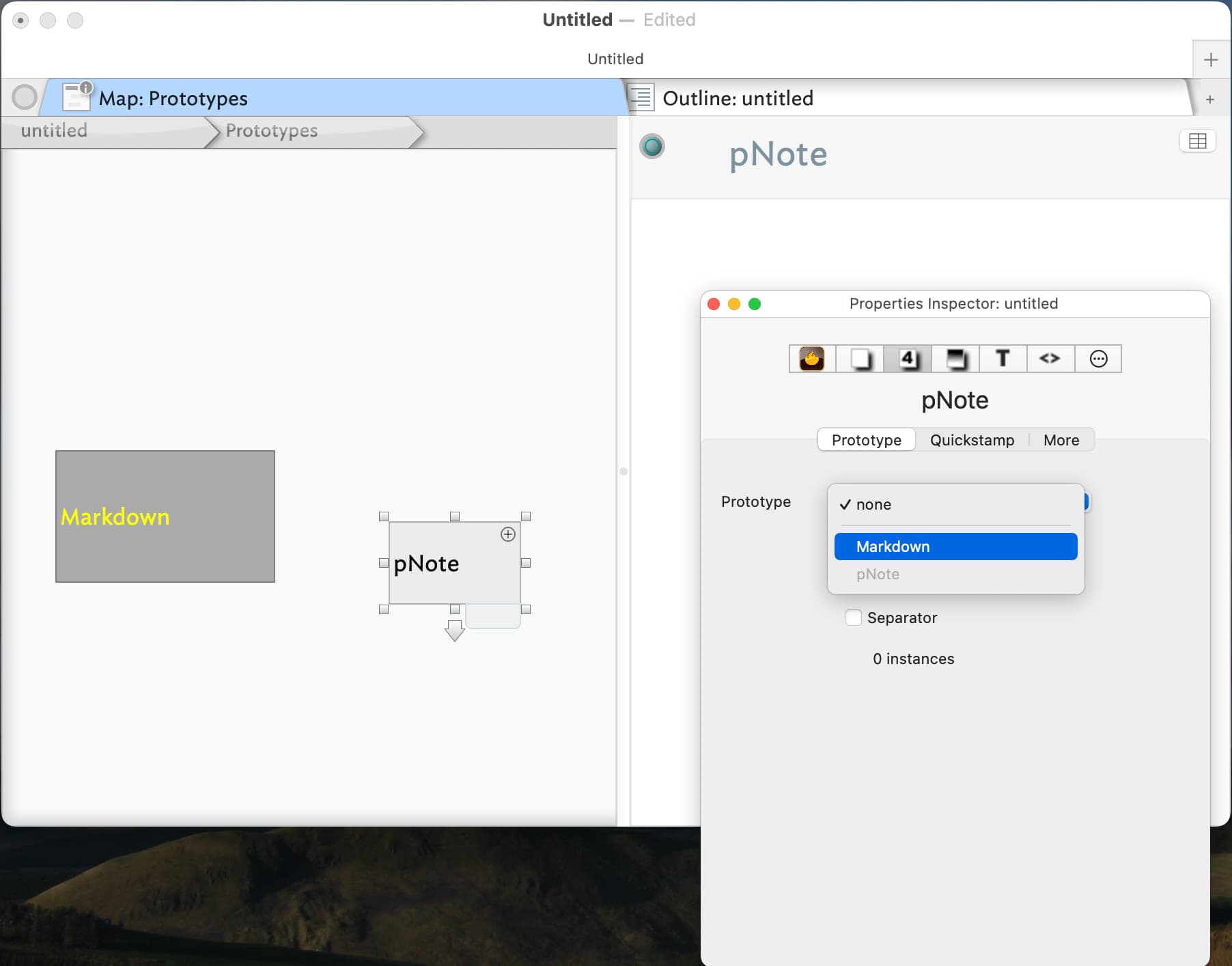
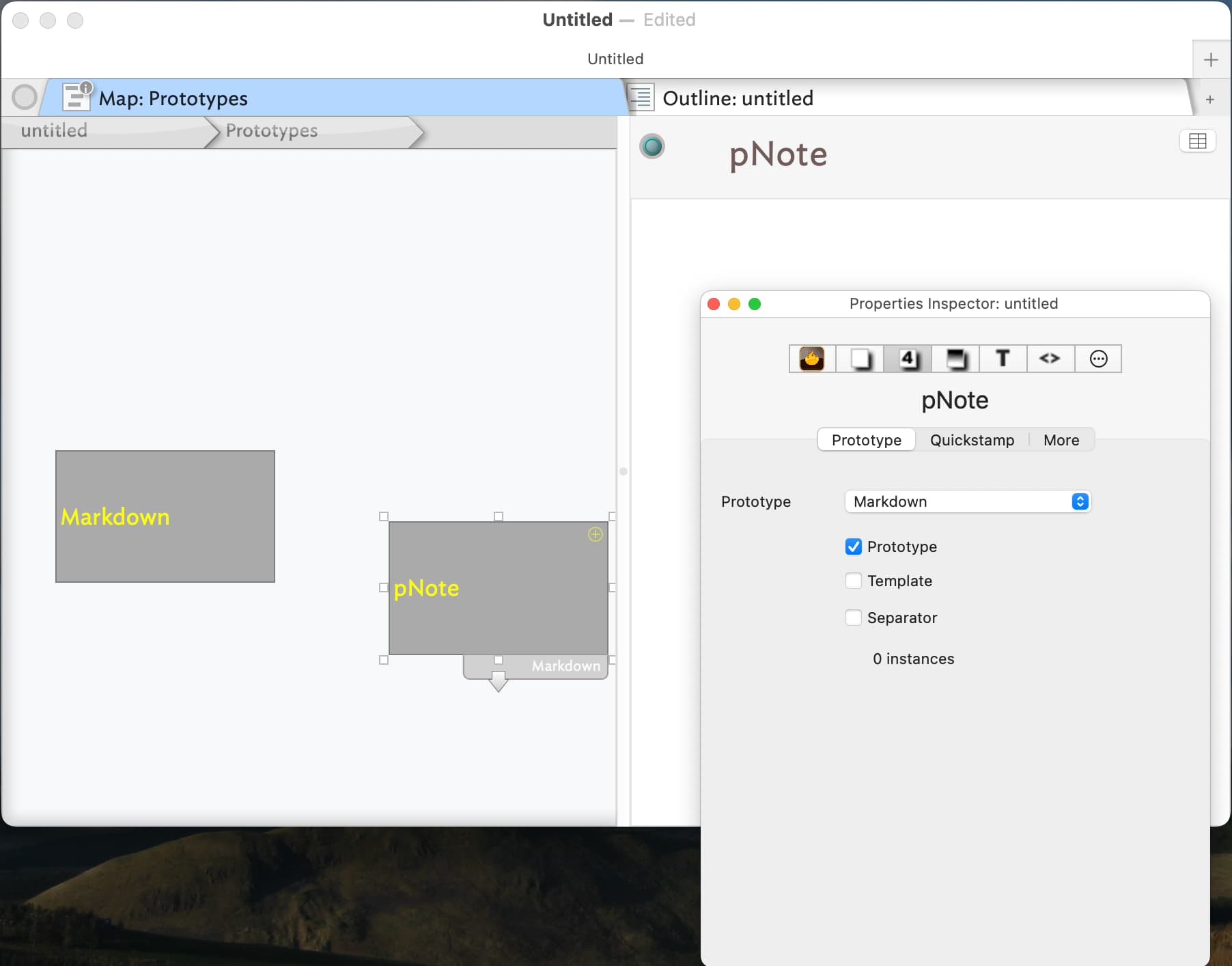
These two screenshots show a prototype I have made before and after applying the Markdown prototype to it. As you can see, in the second shot the pNote prototype has taken on the colour, etc, of the Markdown prototype. So any note I make that takes pNote as its prototype will inherit from attributes from Markdown, as well as having any attributes I give to pNote.
And just in case that is not clear, here are some more screenshots, showing attributes for pNote, and how a note that uses pNote as its prototype also inherits from the Markdown prototype, as can be seen from the preview, where the markdown from Text is rendered.
Thanks for sending all of this – really appreciate it. It seems to me that these are parallel prototypes, is that right? IOW, it seems like you’ve got a prototype folder (container), but each prototype is distinct – and doesn’t appear that a prototype is inheriting attributes from another prototype. Unless I’m missing something, which is certainly possible!
Hi @eastgate, As I said, I’m happy to create prototypes for Article, Document, and Interview, and set color values per each of them.
As I said in my previous post, I’ve been applying a stamp to the the notes within imported containers so that they inherit the appropriate prototype. I’ve just been applying one prototype for pNotes, but will – through your suggest approach – apply one of three stamps for prototypes for pArticle, pDocument, and pInterview.
Just to be clear (as I’m trying to sharpen my understanding of the app, and certain key functions), wouldn’t this approach obviate the use of an OnAdd? As far as I can tell, it seems like OnAdd only works when one includes notes into a container – instead of, say, applying a stamp to an imported (dragged and dropped) folder. Is that correct?
Ok, I feel like I’m getting there. Thanks for your input! Ok, so…if I were to opt for an OnAdd approach for imported folder (dragged & dropped into my Tinderbox file) containing notes, is a way to create OnAdd code that would do two things:
(1) select all the notes inside imported containers, and apply the following action code:
$Text=$Name;
$Name=$Text.words(11)
(2) apply a prototype based on the container’s file naming conventions – specifically it’s prefix (e.g., REN_ART_[date] for article; REN_DOC_[date] for document; REN_INT_[date] for interview). Again, I’m still trying my hand at figuring out Tinderbox’s coding, so this is what I thought would work…
I never use Action Code, so I won’t be much help to you, but if I have understood your naming conventions I would have thought you would want to test if $Name includes “REN_ART” and so forth. I have probably misunderstood.
Thanks. I’m not sure what the right answer is, either. And since no one else has answered I’m inclined to put this query in a separate post. Thanks very much for your help, though!