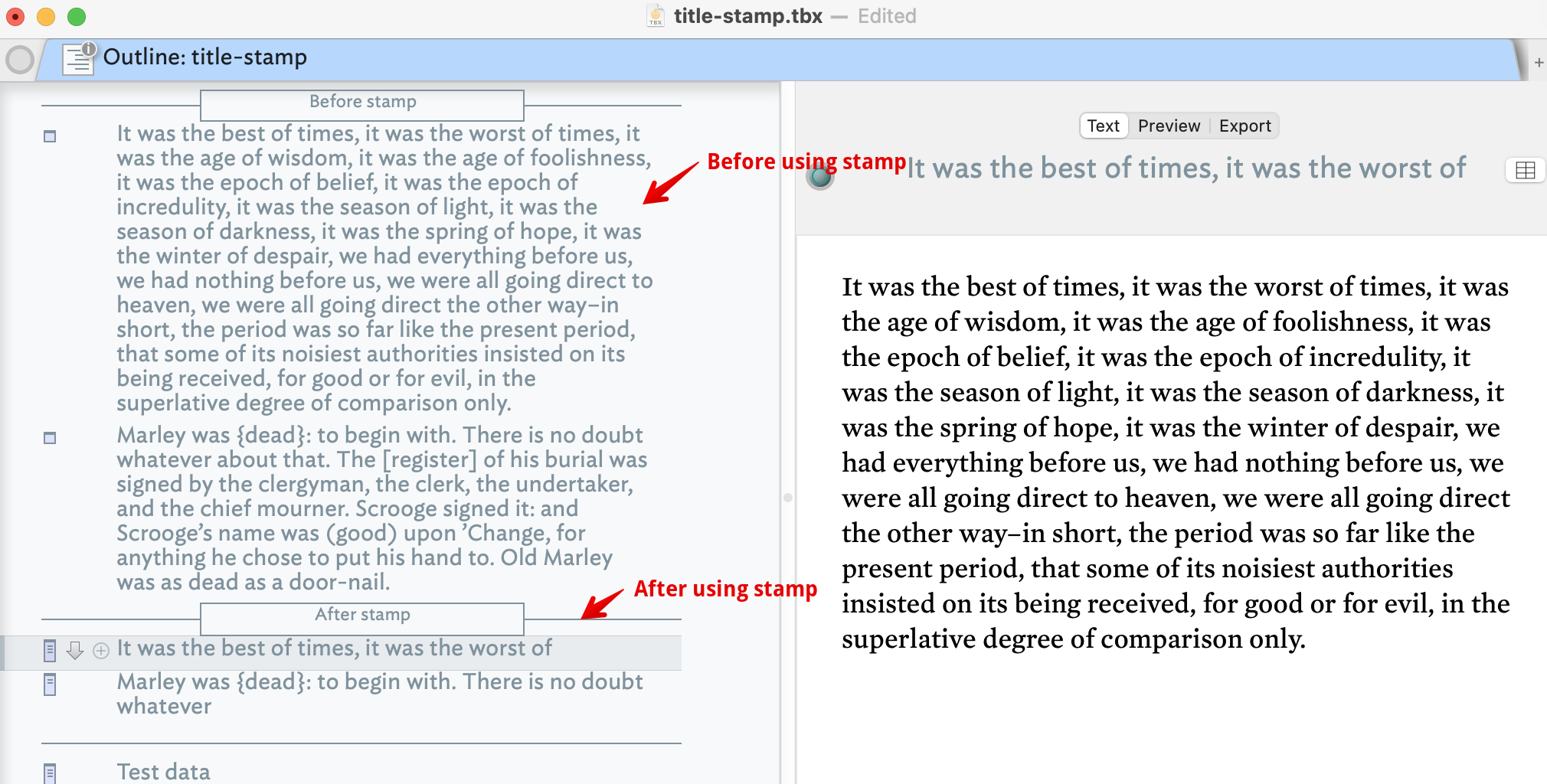
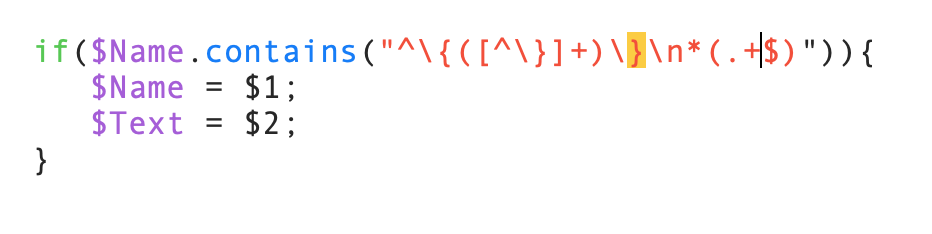Last year, fellow Tinderbox users generously provided me with a stamp code to extract a few words from the top of a note’s text (in the body) to create note titles, and then move the notes’ text (which appears as the titles) into the notes’ text body.
That stamp code is:
$Text=$Name;
$Name=$Text.words(11)
It still works great! But I’m seeking advice for a process that would enable me to query and stamp notes whose title is bracketed with some kind of syntax, e.g., { } or ( ) or something else.
Here’s the background context…
I’ve created a process in which I annotate documents, render the annotation notes, export them into an OPLM format, and then import them into Tinderbox. When I import the notes into TBX, the notes’ text resides in the title – which is why I use that stamp to name the $Title and move the $Text.
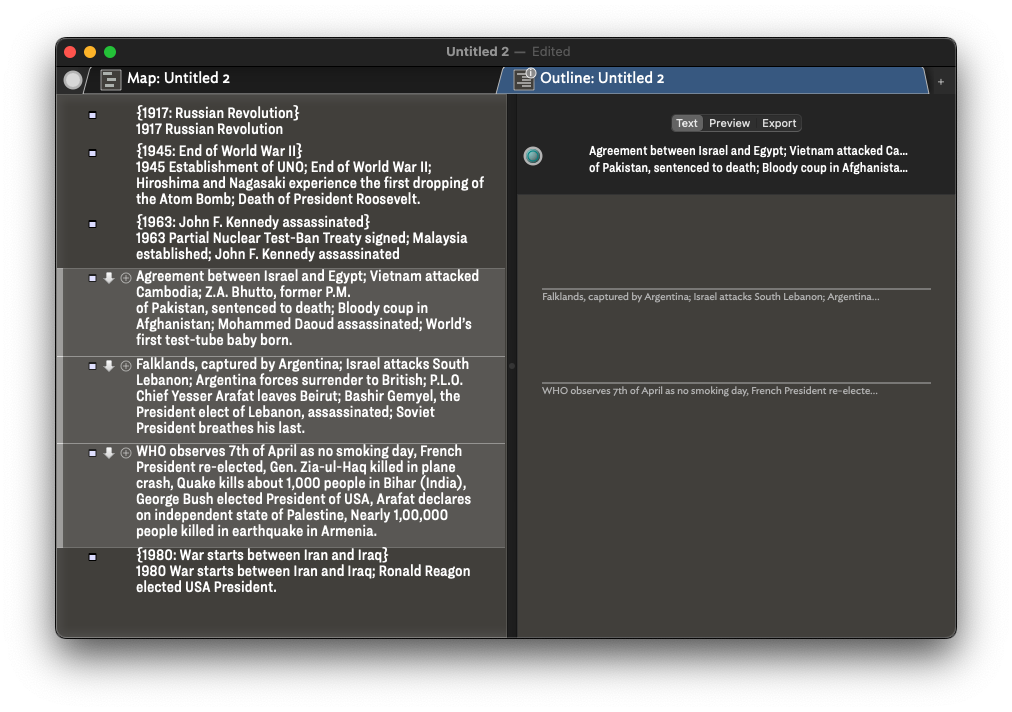
But in some cases, I’m able to create a title for notes (e.g., notes for timelines, “1492: Columbus sailed the ocean blue”), and so I’m thinking it might make sense to query those notes with an agent, and then apply a different name $Title and move the $Text to them. So, here are specific questions…
-
I know that regular brackets are used for Tinderbox’s Ziplinks. So, what kind of bracket syntax I should use instead, that would be better to apply for note titles – and would work best for the process I’m seeking?
-
I assume I’m seeking an agent using regex query code for this purpose. Is that correct? If so, could I get some suggestion on the construction of that code for locating notes whose titled is bracketed in some way, e.g., {1492: Columbus sailed the ocean blue} or (1492: Columbus sailed the ocean blue) ?
-
Finally, what new stamp code should I use for notes with bracketed titles, so that I can remove the brackets (leaving the title intact w/o the brackets), and moving the text underneath it from the title area to the text body?
Thanks so much!