Because TextExpander v 4 no longer works under macOS 26 Tahoe, I need to rescue lots of abbreviations which are deep in my muscle memory and transfer them to Alfred snippets.
Fortunately, the XML file that holds the backup of these data looks easy to parse, but on trying (every cloud has a silver lining and so I regard this as a “teachable moment” ![]() ) I found that parsing such a file in Tinderbox can certainly be done, but finding out exactly what is needed to succeed demands more knowledge than I have at the moment.
) I found that parsing such a file in Tinderbox can certainly be done, but finding out exactly what is needed to succeed demands more knowledge than I have at the moment.
So I ask for some kind help from Forum members.
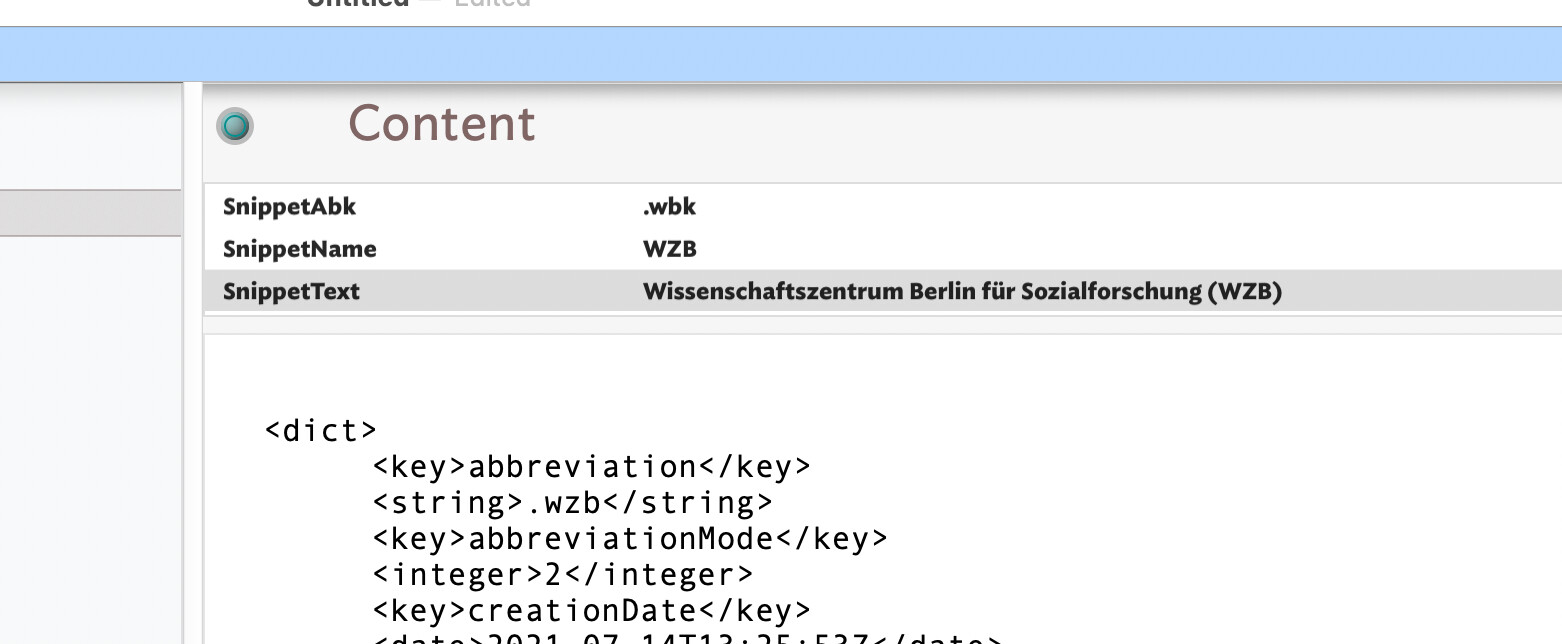
What I have managed to do so far is to split the very large XML file into the <dict>-entries which hold the individual snippets. Here is an example:
<dict>
<key>abbreviation</key>
<string>.wzb</string>
<key>abbreviationMode</key>
<integer>2</integer>
<key>creationDate</key>
<date>2021-07-14T13:25:53Z</date>
<key>flags</key>
<integer>0</integer>
<key>label</key>
<string>WZB</string>
<key>lastUsed</key>
<date>2023-01-13T14:35:58Z</date>
<key>modificationDate</key>
<date>2021-07-14T13:26:17Z</date>
<key>plainText</key>
<string>Wissenschaftszentrum Berlin für Sozialforschung (WZB)</string>
<key>snippetType</key>
<integer>0</integer>
<key>useCount</key>
<integer>2</integer>
<key>uuidString</key>
<string>FC2E3FAB-753E-46EC-BD9D-21FF0FBE72AD</string>
</dict>
What I am interested in are the first three <string>s - which hold respectively the abbreviation, the label and the content of the snippet (in this case: .wzb; WZB; Wissenschaftszentrum Berlin für Sozialforschung (WZB)).
So I created a prototype pSnippet which has three attributes ($SnippetAbk, $SnippetName and $SnippetText) into which I want to save the abbreviation, the label and the content of my TextExpander snippets.
But how do I best parse the content? Here I am stuck. I tried a stamp with the content
$Text.skipTo(“<string>”).captureTo(“</string>”, “SnippetAbk”);
$Text.skipTo(“<string>”).captureTo(“</string>”, “SnippetName”);
$Text.skipTo(“<string>”).captureTo(“</string>”, “SnippetText”);
but that doesn’t work - it captures the first string if not completely ($SnippetAbk correctly contains “.wzb”, but rather than moving on to the next occurrence of <string> (as I expected) fills the other two displayed attributes with the same content.
Another attempt I tried was the following code
$Text.captureXML().xml(“//key[text()=‘abbreviation’]/following-sibling::string[1]/text()”).show();
but that doesn’t work either.
Any ideas where I go wrong? I am sure others have successfully extracted data from XML files - any help or suggestions are much appreciated!
And by the way, perhaps we could have a “How-To” section in the Forum - as valuable a resource as ATbRef is, it contains no example solutions for common problems, and that would be a great asset in the Forum!
Thanks for any help!