I want to bring in to tinderbox highlights from ibooks and automatically extract text into some attributes. So here is some original text from the ibooks output:
May 20, 2018
Chapter One: A COMPUTER WANTED, p. 12
punched cards, which separated pattern from process for the first time in history, would eventually find their way into the earliest computers. Patterns encoded on paper, which computer scientists later called “programs,” could meaningfully entangle numbers as easily as thread. The Jacquard loom
May 20, 2018
Chapter One: A COMPUTER WANTED, p. 10
Indeed, computing was the grunt labor of organized science; before they were made obsolete, human computers prepared ballistics trajectories for the United States Army, cracked Nazi codes at Bletchley Park, crunched astronomical data at Harvard, and assisted numerical studies of nuclear fission on the Manhattan Project. Despite the diversity of their work, human computers had one thing in common. They were women.
So the text in the note should just be the highlighted text. $Chapter should be the chapter text up to but not including the page, and $page should be the page number.
I am generally comfy with regex but not seeing any examples of use in an action in tinderbox.
I found this little piece of code by @pat here in the forum and I thought that it would work for every occasion, but now I see that I fails in many cases to find all the occurrences.
This looks sensible. You’d be better off using $Keywords directly and not foundTags, since $Keywords is a set (I presume) and does list assembly itself.
Note that you don’t allow any space between the # and the tags/
Yes, that’s better regex (I think) and it’s great to see an example of how to change locale. I’m going to see if I can figure how to do it for Chinese language tags… Doesn’t seem possible on my US system, though.
I’ve also gone on various sites on the internet that can help me build Regex. However, I’m still totally stuck. I’m requesting some assistance. I’ve narrowed the problem down to my ignorance of Regex. I’m hoping someone could help me with this. What I’d like to do is extrac the blocks from $Text and insert them under the relevant attributes. Please if I could get the Query and the Action, I’d be much obliged. Thanks.
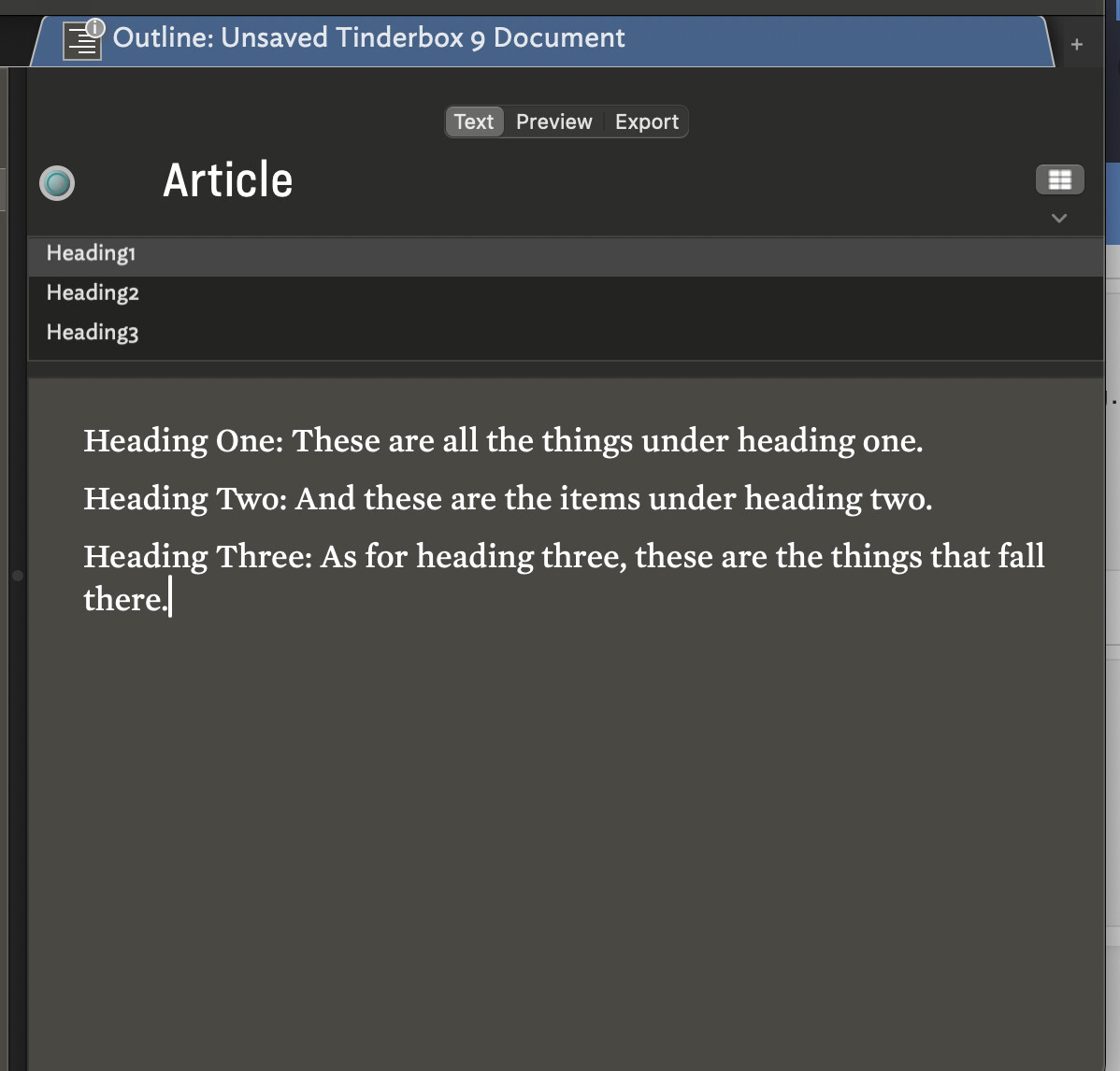
will put “And these are the items under heading two.” in $Heading2.
BBEdit’s Pattern Playground is a terrific way to test out regular expressions. Highly recommended!
If you want an agent to find all the notes that contain the phrase Heading Two:, your query might be $Text.contains("Heading Two:")
You also want to capture the rest of the line after this phrase. So ``$Text.contains(“Heading Two:(.+)”)`. Here the period means “any character”, and the “+” means “1 or more occurrences.” So, (.+) means “remember what comes next, assuming that it’s at least one character”
The action would be $Heading2=$1. $1 means “the first thing you remembered”, which in this case is the only thing we remembered.
It might be worth noting that BBEdit’s Pattern Playgrounds are only available in the paid licence version, not the free tier, in case some might we wondering how to access the feature.