With 9.1 TBX got a new XML parser. Currently I struggle with a very basic task: I would like to AutoFetch an URL returning some XML data. This is no problem - but TBX parses the XML and returns the text without the structuring elements. Like this:
306150dcxml Dies ist ein großer VD17-Testtitel EST beigefügter oder kommentierter Werke Angabe von Paralleltiteln (nicht auf Haupttitelseite) Angabe von Nebentiteln test4200 Unterfeld Dollar b Zusätzliche Indexeinträge Abweichender Titel Originaltitel <engl.> Diedrich, Andrea , 1974- (BuchkünstlerIn) Keutmann, Markus Hachmann, Karen (IllustratorIn) (MitwirkendeR) Wiegandt, Birgit (WidmungsempfängerIn) Wiegandt, Lisa (Widmungsempfänger) Lange, Matthias (Hrsg.) Berger, Renate (GefeierteR) Langer, Sylvia Jaehde, Maik
instead of:
<?xml version="1.0" encoding="UTF-8"?>
<zs:searchRetrieveResponse xmlns:zs="http://docs.oasis-open.org/ns/search-ws/sruResponse"><zs:numberOfRecords>306147</zs:numberOfRecords><zs:records><zs:record><zs:recordSchema>dc</zs:recordSchema><zs:recordXMLEscaping>xml</zs:recordXMLEscaping><zs:recordData><oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd">
<dc:title xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:srw_dc="info:srw/schema/1/dc-schema">Notae & Animadversiones in Dn. Guil. Ignatii Schützii, ICti, Manuale Pacificum: Quibus Ea, quae cum Principiis revelatis, nobiscum natis, Iuris item publici atque privati, in Imperio Romano-Germanico recepti, conveniunt, latius confirmantur, ea vero, quae his adversa, in praeiudicium & odium Religionis Evangelicae, ab ipso asserta sunt, succincte examinantur & refutantur</dc:title>
<dc:title xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:srw_dc="info:srw/schema/1/dc-schema">Kupfert.: Manuale Pacificum. - Vorgebundenes Titelblatt u.d.T.: Manuale Pacificum Guil. Ignatii Schützii, Cum Notis Heydeni Borromei Riccrunti. Editio Novissima. Anno MDCCLII. - Weiteres Titelblatt u.d.T.: Manuale Pacificum, Seu Quaestiones Viginti, Ex Instrumento Pacis, Religionem eiusque Exercitium concernentes, compilatae & in lucem editae, a Guil. Ignat. Schütz, ICto, eiusdem Pacis, olim ad partes Rheni ac Sueviae Executore subdelegato. Francofurti Anno M.DC.LIV. Postea Ab ipso Autore revisae, iam recusae, Iuxta Exemplar Spirense Anni 1683. ab eodem recognitum & propria manu correctum. Anno M.DC.LXXXIX</dc:title>
<dc:title xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:srw_dc="info:srw/schema/1/dc-schema">1654</dc:title>
How can I prevent the processing of the XML? $RawData is empty.
After getting the XML I would like to process the data and put it into corresponding custom attributes. According to the XSD:
<complexType name="oai_dcType">
<choice minOccurs="0" maxOccurs="unbounded">
<element ref="dc:title"/>
<element ref="dc:creator"/>
<element ref="dc:subject"/>
<element ref="dc:description"/>
<element ref="dc:publisher"/>
<element ref="dc:contributor"/>
<element ref="dc:date"/>
<element ref="dc:type"/>
<element ref="dc:format"/>
<element ref="dc:identifier"/>
<element ref="dc:source"/>
<element ref="dc:language"/>
<element ref="dc:relation"/>
<element ref="dc:coverage"/>
<element ref="dc:rights"/>
</choice>
</complexType>
vd17.zip (34.1 KB)
Thanks!

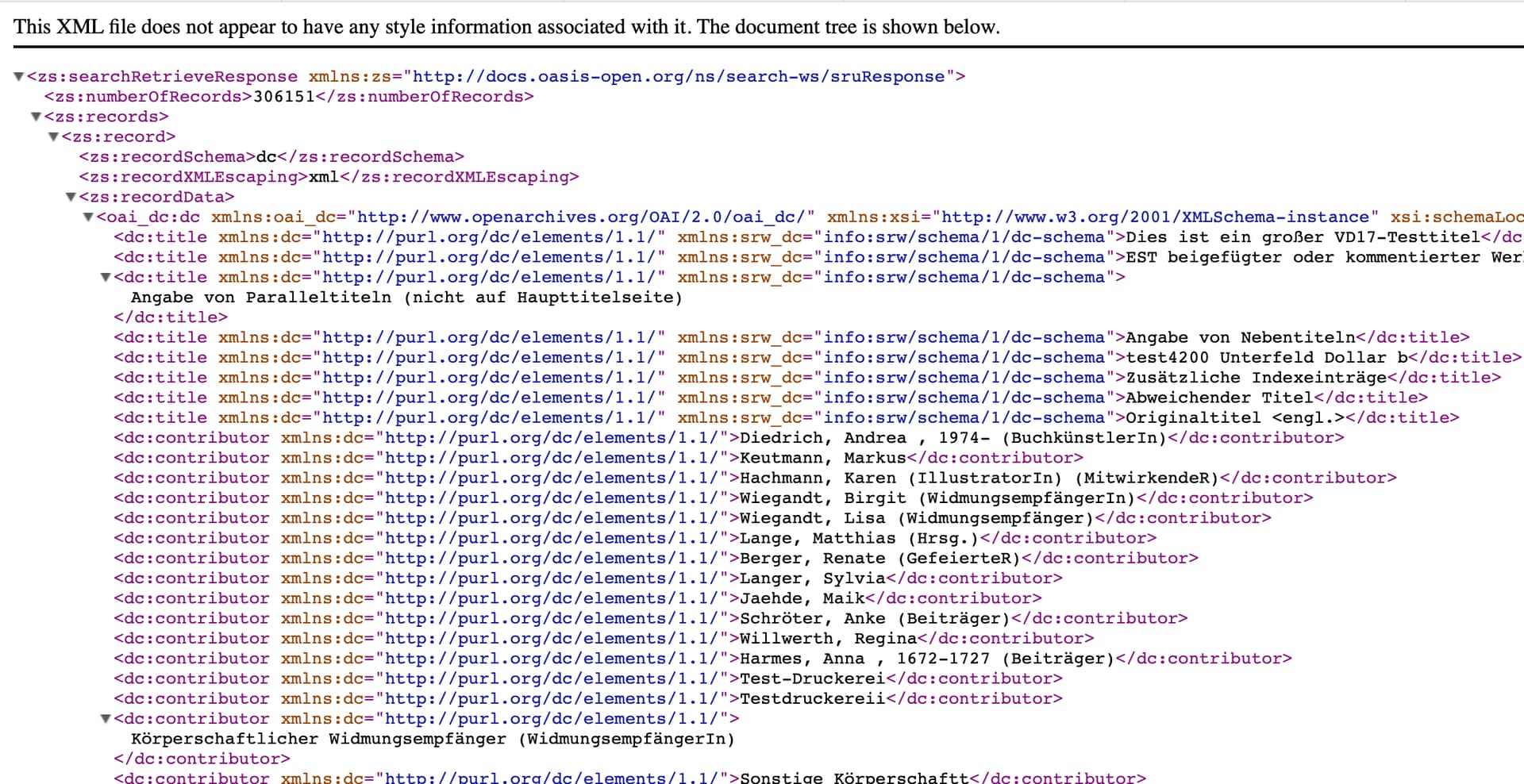
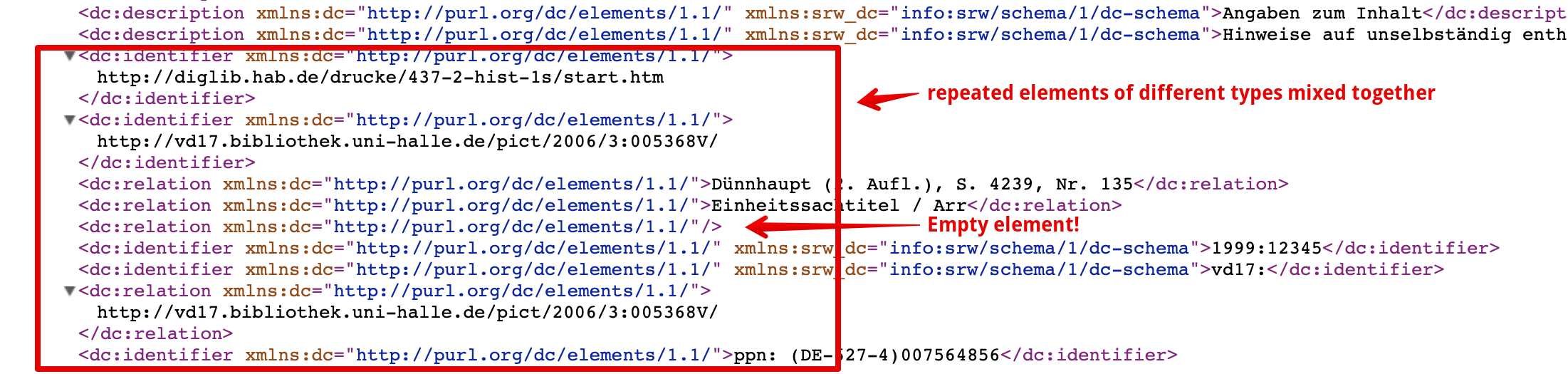
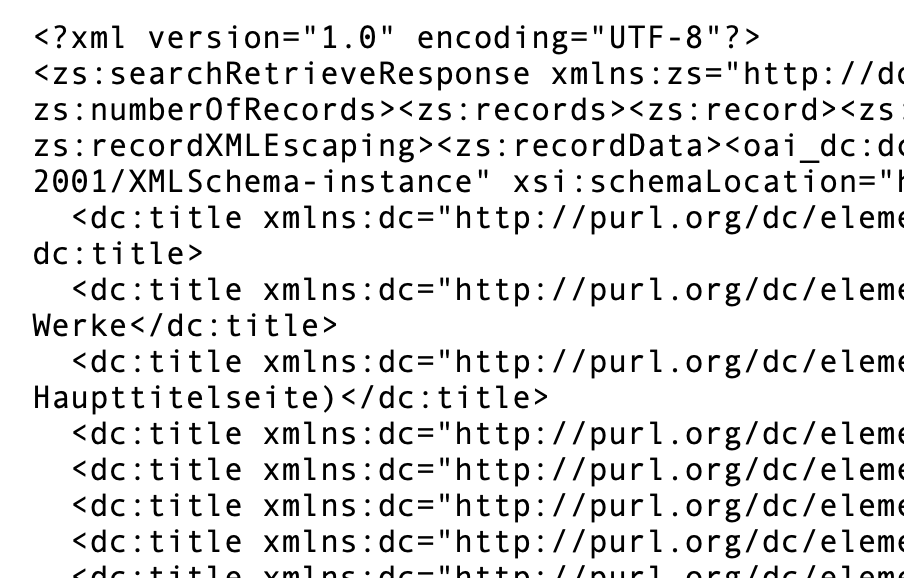
 as here:
as here:
