Hi,
I am importing highlighted text from DEVONthink into a Tinderbox note. This imported text has a clear structure - let me give a few lines of example
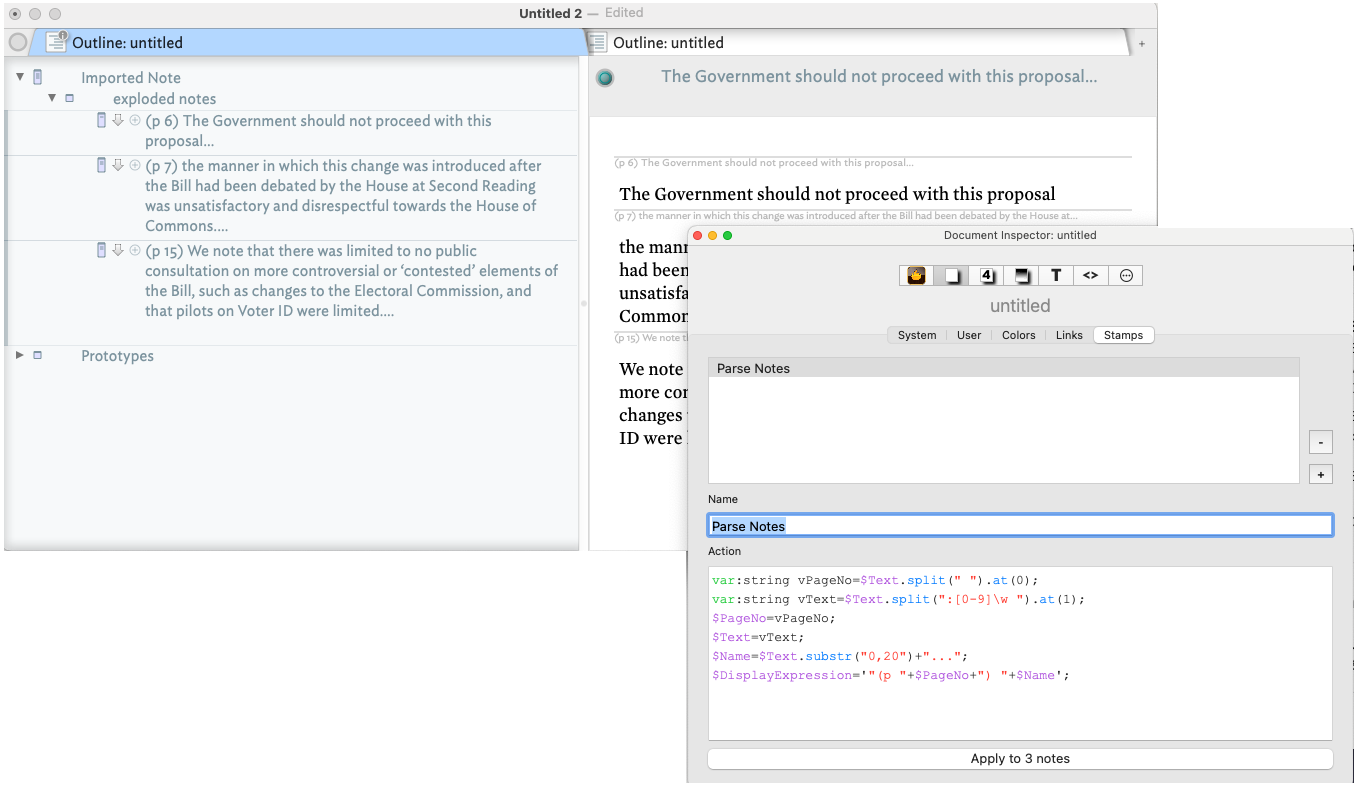
6 Highlight Andreas Busch 14.12.21, 13:18:35 The Government should not proceed with this proposal
7 Highlight Andreas Busch 14.12.21, 13:17:51 the manner in which this change was introduced after the Bill had been debated by the House at Second Reading was unsatisfactory and disrespectful towards the House of Commons.
15 Highlight Andreas Busch 14.12.21, 13:54:14 We note that there was limited to no public consultation on more controversial or ‘contested’ elements of the Bill, such as changes to the Electoral Commission, and that pilots on Voter ID were limited.
This structure allows me to work on it with search and replace with Regular Expressions so I can get what I want - if I do it in BBEdit.
In BBEdit, I can simply set up a RegEx search and replace and apply it to the whole text. Again, an example of what I want:
(p. 6) The Government should not proceed with this proposal
(p. 7) the manner in which this change was introduced after the Bill had been debated by the House at Second Reading was unsatisfactory and disrespectful towards the House of Commons.
(p. 15) We note that there was limited to no public consultation on more controversial or ‘contested’ elements of the Bill, such as changes to the Electoral Commission, and that pilots on Voter ID were limited.
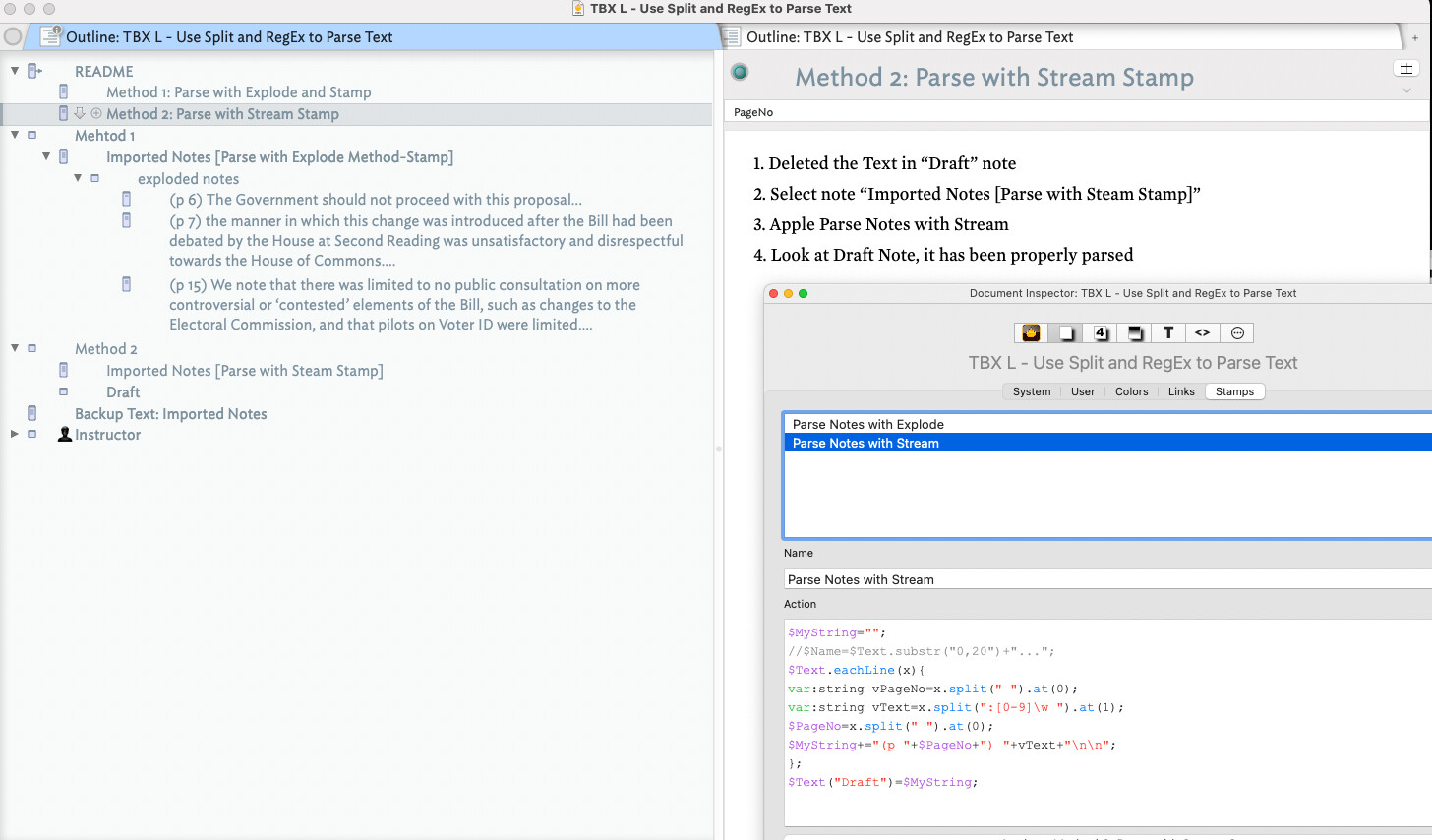
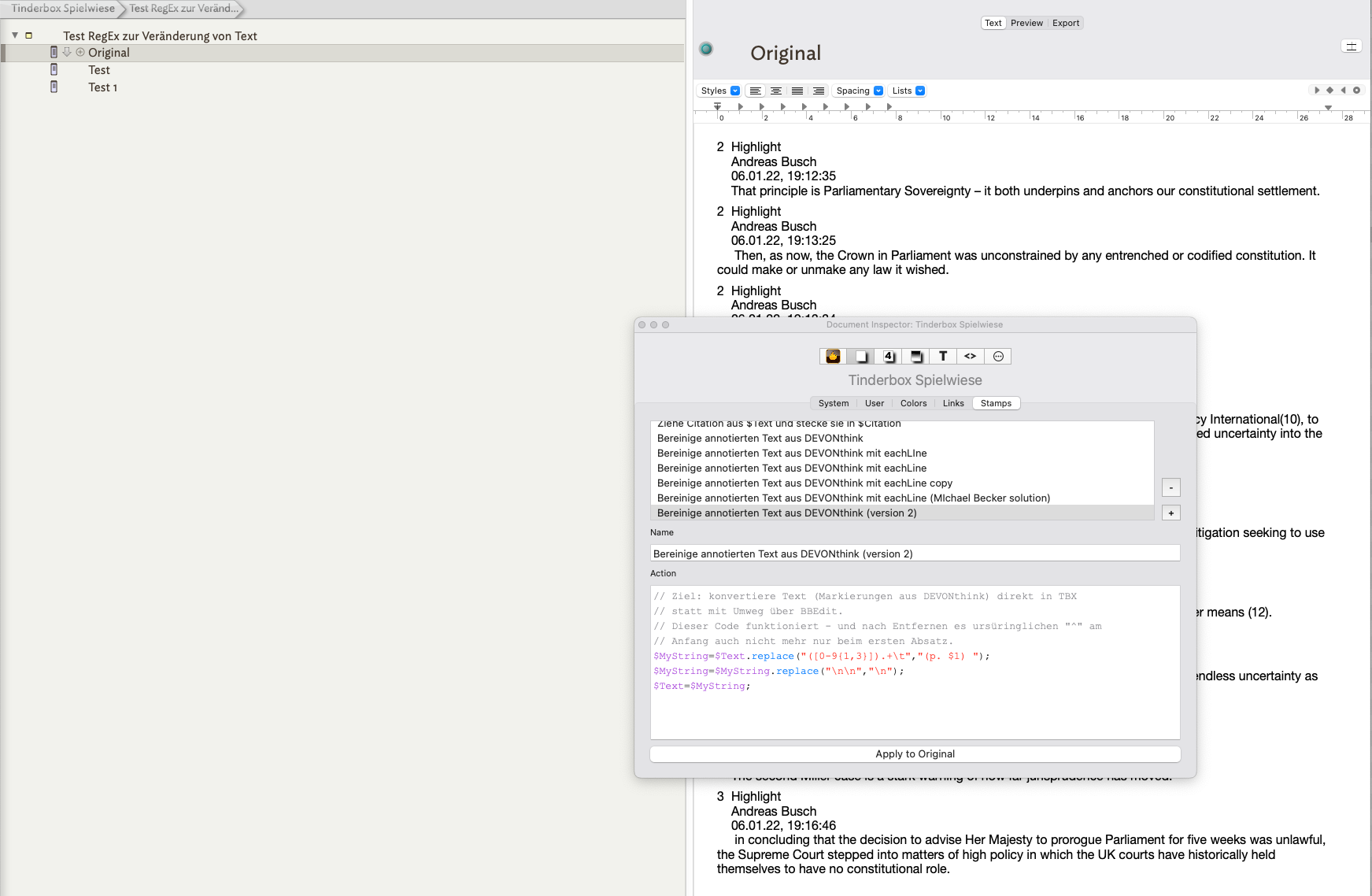
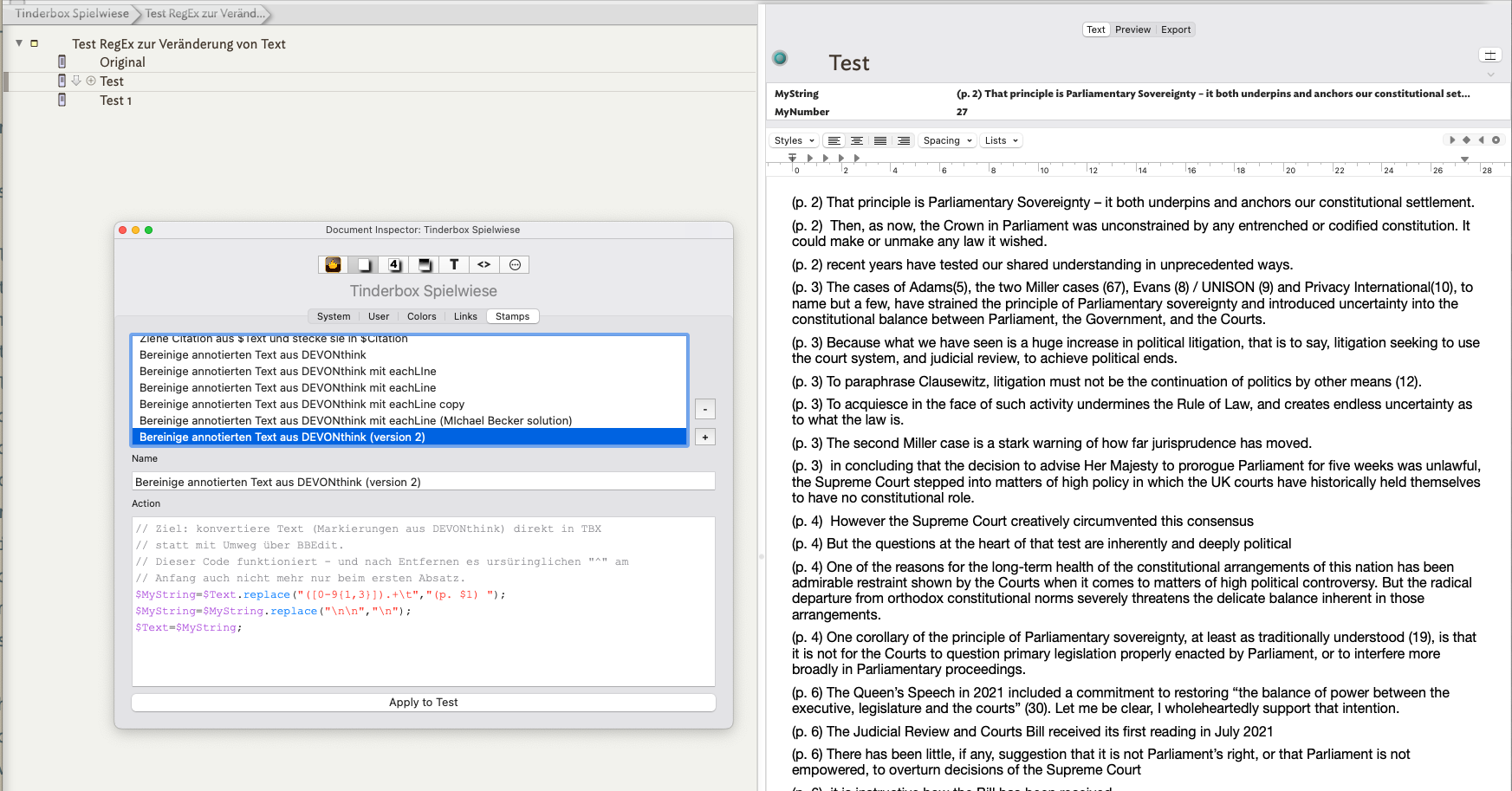
How can I do that in Tinderbox? I created a stamp with the appropriate RegEx code:
$MyString=$Text.replace(“^([0-9{1,3}]).+\t”,"(p. \1) ");
$Text=$MyString;
$MyString=;
But this only converts the first paragraph and then stops. How can I get it to work through the whole $Text? I’d be grateful for any suggestions