An agent is a Tinderbox item that searches for other notes that meet its criteria. If a note satisfies the agent’s criteria, an alias of the note is created inside the agent, and an optional action may be performed on the note.
This agent looks for notes that are either (a) marked as “urgent” or (b) overdue. If a note satisfies the query, its color becomes red.
One might say, “Yes, those notes are urgent. But what about notes that are Tasks assigned by the CEO? Those are pretty urgent, even if I forgot to mark them. And maybe we should exclude overdue tasks that are marked “if possible”. But we can ignore those cases for the moment. That’s what I mean by “rough cut”. Take hundreds of notes, find 20 that might need your attention: great! You can look at a list of 20; working through hundreds of notes will make your eyes water.
So an agent acts upon Tbx notes? If I import a file of 100k words, making it a Tbx note, can an agent copy delineated blocks from that large note and do something with them?
I think it is worth pondering whether that is really necessary or advisable. Everyone has different needs and goals, of course, but my experience makes me doubt the utility of “organising” if by that one means putting everything relating to a topic in one place.
I have notes and research material going back to the 1990s, and over the years I have organised and re-organised these many times in various ways, often as a result of reading somebody’s article about the “best” way of dealing with the problem of mountains of material. It took me a long time to realise that – for me at least – this was mostly wasted time and effort. I would still find myself hunting for stuff for various reasons. Sometimes I could not remember where I had put it, but mostly (perhaps) because the lines of demarcation between one topic and another (in my world) are not absolute, and sometimes material could legitimately belong in several different places. (Categorisation is easier in some fields than others, I believe.)
The result of all these failed experiments is that nowadays I just lob everything into a DEVONthink database without worrying too much about where it lands, because I know that I should be able to find it again using search queries. I then work with what I have found, either by copying some or all of it into another program, like Tinderbox, which has tools that are not available in DEVONthink, or I may work on it further inside DEVONthink – for example by linking material together. (On a side note, I have come to feel that linking items is a much better approach to “organising” than trying to collect items together in the same folder or file.)
These are just my own thoughts and experiences, and they are not necessarily going to be of help to anyone else. I think each of us has to find what works for us by trial and error because our needs and preferences are not necessarily the same as those of others.
PS – when anyone speaks of automating a process like this, I purse my lips. It is all too easy to end up with a more confusing mess than you had at the beginning.
My journey to organizational heaven ended when I installed FoxTrot Pro and was able to do deep content searches of everything everywhere (including inside DEVONthink databases). That pricey solution isn’t the only one – Houdah Spot is another, and also DEVONsphere Express. Even Spotlight searches. The idea is to search the machine, not organize the machine. This is why I defined “organizing” in my post above as “put … into an easily accessible state” – accessible to search tools.
It is the case that if you copied the contents of a single text file in Obsidian and paste it into Tinderbox you would create a single note in the current Tinderbox document (data file). But just because you might start by making a note per ex-Obsidian file doesn’t mean that terminological relationship is fixed. It is the case that a Tinderbox note is the atomic organisational element in the way a file Is in Obsidian (I think—I’ve limited expertise with the latter). However, note that:
you’ve said you have (Obsidian) files that cover multiple topics and you wish to tease those apart.
Tinderbox works best with small notes. A Tinderbox note can hold a small essay, but choosing [sic] to do that makes it harder to use Tinderbox’s analytical tools at their best.
So, even if you started by making a Tinderbox note for every Obsidian note. It is likely you’ll end up with more Tinderbox notes—especially if you use Explode. Tinderbox doesn’t formally limit the number of notes in a (TBX) document or the number of discrete documents. Practicalities like the power of the host Mac, RAM, etc., offer variable but practical limits to the maximum number of notes per TBX or the overall number of TBXs open at once.
Splatters? Not quite. Do try Explode on a small note. The result is a child container (always called ‘exploded notes’) and inside that—so grandchildren of the exploded note. Explode is best carried out in Outline view. Bear in mind all views in Tinderbox draw from the same underlying data. You can also have different view open/configured for different tabs in the document allowing for easy switching of different visualisations of the same data.
For instance, in Map view, you are looking at the contents of one container (folder) of the documents underlying stored Outline. By comparison, Outline view shows that outline and can expand contact the nesting if notes. If I explode on a note in a Map view, all I see it the exploded note’s icon style becomes that of a container: the exploded notes are two (outline levels below). To see them in this map, I’d have to drill down into the container to the child map that holds the ‘exploded notes’. As you might already see, in Outline I can see all 3 maps’s contents in the same view, albeit laid out a different way.
The new Explode-generated notes aren’t ‘splattered’ but will be laid out in a row or grid when seen in Map view.
Once exploded, you can then work on the these new notes:
You might simply take those split notes and likely move them to other parts of the outline, i.e. to different map(s), based on you reviewing their contents.
You can set up some ‘coding’ (automation) such that some extra metadata is applied to the new notes
Either using the latter or plans you have set already, the explode process can be automated to move the new notes directly to a new home.
The desire is inevitably to go straight to the last above. But, computers can’t guess. So to set up the automation you will need to expend a modicum of effort thinking about the criteria to set and test for moving notes. The Help, support resources and the forum can help with thinks like code syntax and what input goes where. But only you can really know your own content and idea to feed into that process.
You could go the ‘AI’ route (essentially lots of ML (Machine Learning) code). The upside is you get an answer for seemingly less effort. the downside is … you get and answer. But you don’t know, because AI can’t explain it’s processes, if the answer is correct or even complete. Thus, going that route you’ll need to review some/al of the answers to know if the aI output is believable. Compared to roles like summarisation and process description, IMO is less use in your sort of task as you don’t yet know the answers so it’s hard to assess tif the AI is right or simply making near-random choices.
That certainly sounds possible. BBEdit is good for testing regex, but essentially you’d be writing/running all the work in AppleScript. Tinderbox does have a AppleScript dictionary (my sparse notes on that dictionary). In the AppleScript much of the code would be the scaffolding of opening/saving files but nonetheless it would save a fair amount of time.
If you drag/drop an existing plain text TXT file (e.g. an Obsidian ‘note’ file) from Finder into Tinderbox you will create a new note in the current Tinderbox document (TBX file). The name of the note will be the full file name (e.g. my key ideas.txt) and the text—the content of the note, with be the plain text of the file. Whereas Obsidian is toed to using only Markdown (or explicit HTML) for styling, Tinderbox uses RTF. Tinderbox does have the ability to display note text using Markdown styling, although text cannot be edited directly in Markdown preview mode (so a requiring a shift in editing norms for an Obsidian user).
Once data is in Tinderbox, you’ve a lot of textual analysis and manipulations tools available. For instance it is trivial to, say, snip the file extension off the imported name and to pre-pend the note’s name to the beginning of the note text. Tinderbox’s action code is not closely based on any other [insert code language] but it is documented pretty exhaustively in my aTbref, and the forum is here to help with arcana of code syntax if stuck. Tip: don’t try and build the whole process in one go, break it into small tasks and connect those.
If you do go the Tinderbox route. You might find it useful to stage notes through several files doing different things. So, for example and ingest/triage file from which you’d copy/move notes to a more mature file that doesn’t need to run all the automation used for ingest. Instead the latter can focus on further analysis of the notes, e.g. collecting sets of notes as reference for a writing project.
Clearly, there is no single-button configuration for this, not least because that would only work for one user—you—and would would have to be (expensively reworked for another personals data. The key is to not invest time and emotion in the need for a ‘simple’ solution. That is better invested in actually doing the task.
Probably not. It is better to think of Tinderbox as being ‘AppleScriptable’, i.e. you can use AppleScript to directly interact with the document structure. To do things internally, Tinderbox’s own Action code is a better first choice. There is no AppleScript UI within Tinderbox in case that is part of the question. Using Action code you can trigger calls to AppleScript. But unless those do things Action code can’t, then action code is a better start.
Action code does allow for use of regex and indeed using individuals back-references (matched sub-patterns in the target). Tinderbox also has some fledgling AI, e.g. to detect Name or Organisations, building upon macOS features.
If you have DEVONthink, whether or not you move files direct to Tinderbox, i’d also ingest them to DEVONthink and use its analytical tools so. The two apps can interconnect and both as AppleScriptable - DEVONthink far more so that Tinderbox. Given that at this early stage your work is necessarily exploratory, I’d leverage all the tools at my disposal. Mechanical (pattern match) recovery gets you only so far. ‘AI’ doesn’t yet understand the finer semantics of human language use. Being able to simulate a person’s writing is easier than parsing out the (hidden) meaning of it beyond word (co-)occurrence. Quantitative tools and approaches (counting things) tens to fail in case of words with multiple meanings or concepts that are often written about implicitly—i.e. there in no word (pattern) you can look for.
Put another way: think computer-in-the-loop (as helper) not human-in-the-loop (as wondering if the computer answers are correct).
For my part - I wholly concur with the advice proffered by @PaulWalters and @MartinBoycott-Brown. My take is that it will greatly benefit to study your issue from several angles prior to even getting started.
Here’s a thought-experiment - consider you could create one large text file comprising ALL the Notes in your corpus:
How long would it take to read through this single file?
How do you imagine you might annotate, separate, and re-divide/categorize the content, - after this read-through - and what would the final result look like?
I’m inclined toward the idea of first envisioning a set of broad-strokes Attributes, then categorizing/splitting while drifting toward the intended organizational system.
Would having read through the content allow you an idea of what your completed corpus might look like structurally? What key categories or topics do you believe your re-reading analysis might yield?
How might you set up your newly-organized Note library to accept fresh input over coming days-years?
Dealing with exceptions - If a Note could be categorized under multiple headings at once, how would you deal with it? Duplicate and file it multiple times/places? Populate a set-type Attribute mentioning your multiple categories, and enter into them the various potential headings?
How many hours would it take to read through your bunch of Notes? What is the final takeaway format/layout of your data you’d like to see, as in what will your finished extracted content look like?
There are more thoughts in this question. But these seem like a good start. Automating a challenging process like this, to me, starts with a well-conceived plan which you can execute with a mind to meeting or closely matching your allotted time-frame.
At the risk of derailing the thread, I’d be interested to hear more about its advantages over HoudahSpot. I’ve used the latter for a long time. But I’ve come to realise that finding the material is just part of the job, and that the way a program displays the information it finds can make a huge difference to how useful the program is.
The simplest comparison of FoxTrot Pro to HoudahSpot is that FoxTrot builds its own full-text indices, and HoudahSpot is a front-end to the Spotlight index. Because FoxTrot controls the index in-app, it provides several options for what is indexed, how the index is built, and how results are presented. I believe HoudahSpot limits search parameters to Spotlight’s parameters (which are very robust), but I find it much easier to build quick on-the-fly boolean searches with the FoxTrot Query Syntax. I believe HoudahSpot doesn’t search Mail on Sonoma (?). However it does it, FoxTrot searches Mail on Sonoma.
I also like the industrial feel of FoxTrot vs. the slicky Apple UX toolbox that HoudahSpot uses – which is a strange preferences I suppose. Maybe that’s why I like TBX and DT?
@MartinBoycott-Brown I was wondering, reading you: how do you combine with Tinderbox this usage of DEVONthink that you describe? I mean: do you transfer your Tbx notes into DEVONthink or do you take daily notes directly in Tinderbox?
Bonsoir Dominique! I must take this opportunity to thank you for the many interesting videos about Tinderbox that you have shared with us. Always fascinating.
At the moment I use DEVONthink for storage and Tinderbox for working on things. I see DEVONthink as being a bit like a library in which I keep things that I may want to refer to (I also use Bookends in that way, but I typically index my Bookends attachments folder in DEVONthink so that I can use the latter’s search functions – Bookends is there for citations and bibliographies, really). The items in my DEVONthink database are an eclectic mix of pdfs, images, videos, my own notes in Markdown or some other, spreadsheets, Powerpoint, and I know not what. I find that DEVONthink item links are very valuable because they are almost unbreakable, and I think that most things that will accept a URL will be able to link to an item in a DEVONthink database – even to a particular location in a pdf now, I believe.
So, if I need to try to understand something, or analyse it, or work out the relationships between concepts, I will fetch the “ingredients” from my DEVONthink “store cupboard” and put them into notes in Tinderbox, where I can place them on maps, colour them, link them, and give them different shapes till my addled brain begins to make sense of whatever it is.
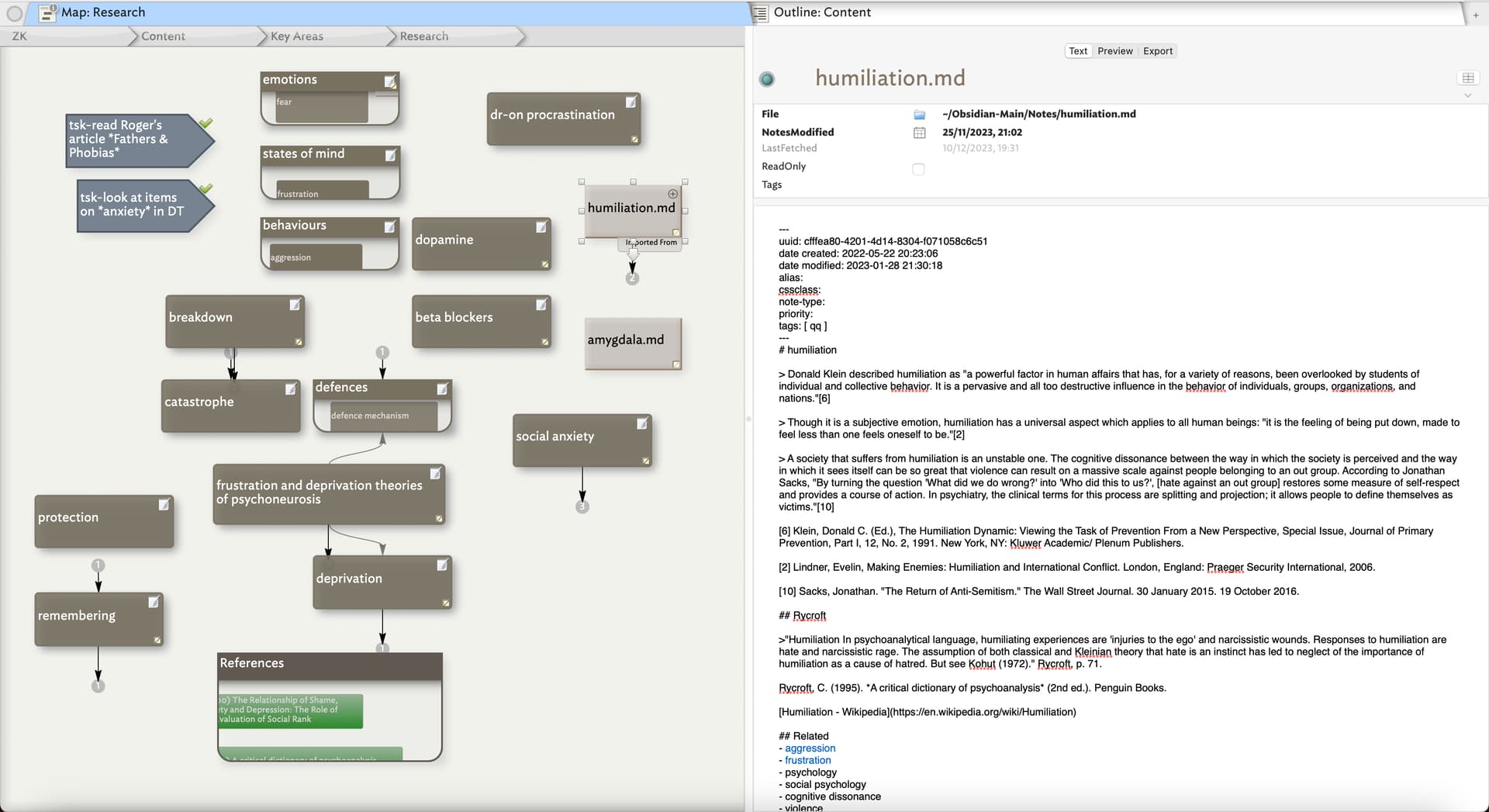
As an example of this, I have recently been trying to understand the complex interplay between certain emotional states, behaviours, and their causes (some of the material for which actually came from Obsidian, which I am using sporadically at the moment):
I don’t really take daily notes at the moment. I did that quite regularly when I was using Obsidian more, but I don’t seem to have the mental space for it right now.
I’ve just finished reading Mark‘s book called the tinderbox way. I think it gives a good sense of tinderbox, but more importantly, for me, it discusses many different ways of approaching organising. It does it in a way that is a little more abstract than Just tinderbox
So that might be a way to think about your issue, and also get a sense of how tinderbox specifically might help. I came away with much more of a sense of going beyond notetaking and actually actively working with my notes for multiple purposes.
Dear Paul Walters,
I always refer to your useful articles and am learning about Tinderbox. I’m using HoudahSpot 6.5, and since the version update, I can now search within Mac Mail as well. I would like to supplement the content of this article about HoudahSpot. Sorry for the inconvenience.
Yours, WAKAMATSU (from Japan)
@WAKAMATSU, I assume you are not using macOS 14 Sonoma. HoudahSpot provided a Mail plugin for versions of macOS prior to macOS 14 (Sonoma), that enabled it to search the content of Mail’s mailboxes. With macOS 14, Apple removed support for Mail plugins, thus disabling HoudahSpot’s ability to search macOS 14 Mail content. (See the footnote on HoudahSpot’s website.) Developers theoretically could create a Mail extension to replace their plugins, but I understand developers are generally not interested in bothering with Apple’s MailKit toolbox due to its functional limitations.
(It’s possible HoudahSpot might be able to search mail under macOS 14 in other mail applications, such as Thunderbird, but I don’t know. It is also possible to archive mailboxes in DEVONthink, and then search in that app.)
I don’t know about HoudahSpot, but CC-Command (in https://www.artisanalSoftwareFestival.com/) has a new mail extension, and I know another developer that is completing theirs.
C-Command’s Eaglefiler is a great software app that I use for archiving emails. It works very well as a tool for organizing, searching, and accessing old emails, as well as other file types.
Another option for easy access to emails that can be used by HoudahSpot and other search programs is the email client MailMate. I switched to it specifically because Apple took away third-party access to Apple Mail. MailMate has a preference setting to store emails at any local folder location of choice, and with that, Houdahspot is back in business searching through emails.
C-Command created an extension so that SpamSieve would continue to work on Sonoma, which it does. Would be difficult, or impossible, to keep that product alive without the extension.
I have the SpamSieve extension in Mail under Sonoma, working beautifully, so I expect other related apps will follow.
Wholly off topic but while I am writing, a tip of the hat also to the Artisanal Software Festival for introducing me to Easy Data Transform which hands me a nigh-perfect tool box to simplify much of the ad-hoc scripting I have been doing for decades to marshal data for analyses.