- I have a LOT of notes files from 30+ years of personal journaling. It’s not diary type stuff, it’s serious thoughts on many aspects of life. Some files are 100k words, done over a year of daily writing (many topics). But for the past several years I’ve been doing daily files (using Obsidian for last few years), almost always several topics touched. It’s a large hodge-podge mess.
- I would like to wave a magic wand over it and neatly organize all notes by topic and sub-topic so I can easily find and peruse everything I’ve ever written about ‘love’, or ‘God’, or ‘responsibility’, or ‘heart’, or ‘soul’, or ‘government’, or ‘grass roots’, or ‘spirit being’, and on… Hope this gives a general idea.
- I need to be able to automate this somehow, as I simply don’t have the time/energy/motivation to go through each file, lifting blocks and transferring them to cumulative files on the many topics. I have thought of using BBEdit and Apple Scripts, with neither of which I am well acquainted. I think there are probably tools there to do it but not sure I have time to become fluent with Apple Scripts.
- So my question is, can Tinderbox undertake a big text-wrangling project such as this? With agents or whatever may be the right tools?
- This project will deal with several million words of notes spread through thousands of files. At this point all I can do is shake my head at the size of the task.
- I hope some veteran Tinderboxers may be able to say whether this is something Tinderbox can accomplish (and if so, some guidance as to how). I thought it best for me to obtain the clearest advice I can rather than just jump in and see what I can figure out, as I could easily invest a chunk of money and a lot of time only to ultimately fail to find a way.
Color me hopeful,
Andy
yes - Tinderbox could help solving your task. It still will require some work to set up the system. But you could start small and improve your solution step by step.
First task is to import the notes in a way you could work with them in TBX. This is easy for some parts but If you speak of files > 100k you will have to split them into several smaller packages (and still maintain the relation between the notes) otherwise it will be harder to extract the main subject and all the sub-topics from this large text object. A nice option is the use of AI within TBX - this can (!) help to add meta information to your notes - that’s what I do with ChatGPT here.
1 Like
It’s an admirable and valuable accomplishment to have such a large library of notes over three or more decades. You didn’t mention the medium for your library, but I assume they are a combination of text and other files.
As @webline mentioned, Tinderbox can definitely help. I suggest, that for such a large set of documents, Tinderbox might not be he primary tool for organizing. For, your project might have several aspects:
- organizing, or putting the document library into an easily-accessible state;
- researching your notes to see what your thoughts and relationships between various topics have been over time; and,
- refactoring your notes on a given topic to spark new ideas and write whatever new compositions strike your fancy based on your past notes.
(Other members here will have their own terminology for this kind of effort.)
While Tinderbox can help, personally I would not use Tinderbox for the raw organization of all those documents. You will probably want to keep all the individual documents intact. And you also want to search them by topic. So, if this were my library, I would put it into DEVONthink. Either import the documents, or index some of them. You can, for example, have a DEVONthink database that includes imported documents, newly created documents, and an indexed Obsidian vault. DEVONthink has fantastic search features, and also quickly suggests relationships between documents. I suggest taking this organizing part of your project, as well using smart searches for the research phase, to the DEVONthink forum where you will find lots of deep experience on how to do that.
DEVONthink plays well with Tinderbox, and so without importing the massive library into Tinderbox files you can use Tinderbox to focus on adding your research findings to Tinderbox files and then using Tinderbox to aid the thinking or refactoring phases.
This kind of project can (and should be) a lifetime occupation. Jumping back and forth between the three phases of organizing, research, and refactoring. It’s what many great writers, such as Coleridge, did with their own large library of notes as they discovered in their past raw notes the material for their finished, polished works.
It’s helpful to designate topics (‘government’, ‘heart’, etc.), but do not attempt to cull the entire library and assign everything to a topic. You will find that nearly impossible to do satisfactorily, and also find that it turns out to be a very limiting approach to managing notes. This is the sort of project that one should allow oneself years to undertake – if you push yourself to find and organize all your life’s insights as fast as possible, you’ll give up in frustration very soon.

You have a wonderful library to draw from – many readers here would be jealous to not have kept all the notes you’ve kept. Take your time. Browse, and spend time discovering things without worrying about all the software stuff. The tools like DEVONthink and Tinderbox and Obsidian and whatever are not the point. Wandering through the notes is the point – and as you do that you will discover the insights you are looking for.
4 Likes
I’d agree with Paul Walters that DEVONthink is a good place to start. Search is more sophisticated than many other programs (obviously finding material is a major challenge with a large collection). I’ve attached a screenshot of a search in which I have looked for documents in which the words “Freud” and “Jung” appear within ten words of each other (you can vary the proximity, and also use other search terms – this is merely an example). As you can see, the database contains over 22 million words in nearly 9,000 documents, and the search has found 26 matches in 0.017 seconds. The horizontal bars to the left of the file names indicate how good the match is.
Tinderbox might be better suited to analysing what you find and displaying it in a different way.
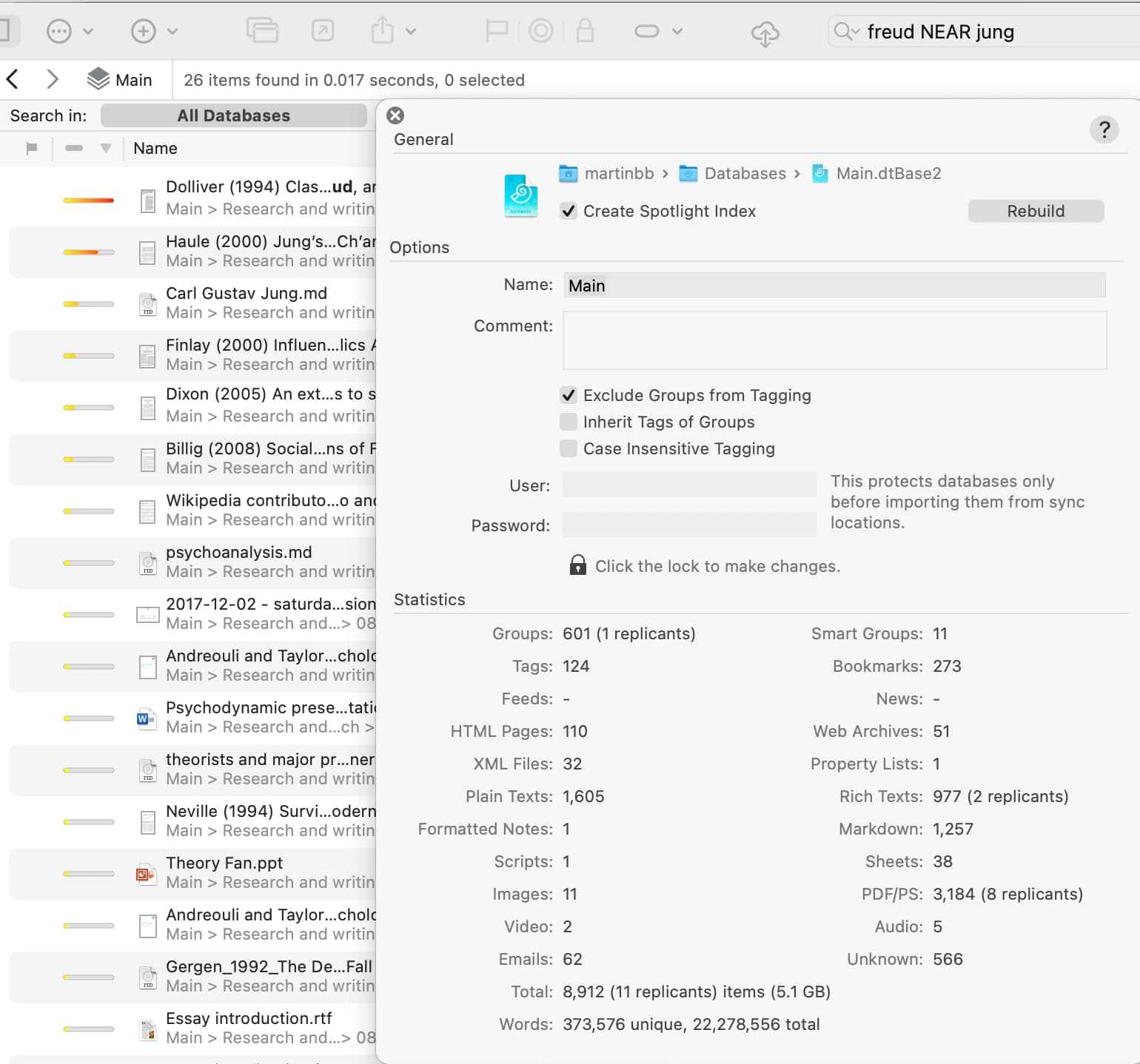
2 Likes
I agree with the other comments that you have a “good problem”; congratulations on persisting with your collection of notes!
Taking from and extending @PaulWalters’ advice not to disturb your origin corpus, I would also leave that intact. As a first pass I might run through the corpus (after importing into Tbx) and try out some of the NL tools to seek for key words and gather them as Tags.
Although the assemblage may look like a mess of jumbled ideas from a distance, I suspect there are powerful connective threads running throughout your notes, and perhaps not so many core categories. After all, most of us tend to notate those thoughts that matter to us, and many of the thoughts that matter tend to remain consistent over time. Some other threads may spontaneously die out as our interest in them wanes. You might try to use Agents and Stamps to add categorizing Attribute values that will help you build a retroactive breadcrumb trail through these notes. Personally I would appreciate an opportunity to visit some of my thoughts chronologically to understand their evolution, and set up my corpus for fresh inputs in requisite realms for the coming years.
Good luck!!
Simple to implement, word clouds can help in deciding which terms are more frequent and thus perhaps candidates to use for organizing.
For example, just this in the text of a separate note…
^documentCloud^
…produces something like this when you view it in the Preview pane:

One of several aTbRef entries:
Adding to the stop list will suppress the display of terms you don’t want to consider:
Hi Martin, good stuff, but just a personal comment: My Dad was a professor of psychology, specializing in Jung. He did a sabbatical at the Jung Institute. He gave me Memories, Dreams, Reflections when I was about 14. I’m not a psychologist but liked that book and I have several of Jung’s works (inherited from Dad). I also like Victor Frankl’s Man’s Search for Meaning, though I don’t have any of his other works.
Andy
Hi Gerard,
whatever helps to solve your problem is the perfect choice!
Just a small comment about those tag-clouds - they are fancy, but they are only the 2nd best solution for your task: just sort the words by frequency and you get a list with the most important items on top - much easier to read then a cloud - but by far not as good looking ![]()
2 Likes
-
The word clouds in Get Info are better than the HTML-exported clouds.
-
The word frequencies Detlef refers to are in Get Info: repetition. This is not a conspicuous Tinderbox tool, but it can be very handy!
3 Likes
Hummm…thanks for mentioning … I had never seen/used the Repitition feature before to find uncommon words.
I learn something everyday by reading the forum.
Thanks everyone.
Where to find Get Info’s repetition info: see repetition tab.
For Get Info’s word cloud: see words tab.
1 Like
Gratitudes to all, I’m glad to learn (though I haven’t practiced yet) these methods for organizing and researching. The remaining factor is refactoring. What I would very much like to accomplish is significant automation of that too. Without some automation it’s going to be a very long process.
- In this case the first step of refactoring is to gather all text blocks on a given topic together into one file. As Art Currim said, it can be stimulating to chronologically walk through one’s developing thought path on a subject.
- I agree of course on leaving the original material intact, probably in plain text or markdown. But since the notes files contain multiple text blocks on multiple topics, I’d like to somehow automate the process of copying blocks of text, by topic, from multiple source files into new, topic-concentrated files, and store them in plain text or markdown for posterity and for further work on specific topics.
- This mess is due to my journaling habits and the way my crazy mind operates. I sit down, I start writing. A thought on another topic bubbles up, I line feed and write again. Each day I may write on four to a dozen topics, in one file, dancing back and forth between topics as moved. If I were to take the time to open a new file for a new thought, the distraction of doing the mechanics might lose the thought.
- Weird, I know, but that’s how I’ve always been. Obsidian helps because it can open on startup to a new Daily Notes file and I just start writing. Don’t have to manually open a file, name the file, etc. But the result of this is thousands of files of mess, and in effect everything I write is ‘lost’ in a couple of days because it’s not organized and accessible. In a way it is good, I think, to fresh-start multiple times on a topic without reference to what you’ve thunk before, given that it’s lurking somewhere in your unconscious anyway. But now I want to organize.
Andy
You can do this in Tinderbox too, of course, but there’s the same downside: all these daily notes!
My suggestion, not necessarily good: pick a topic that interests you right now. Write an agent that will do a rough cut — perhaps an incredibly rough cut — on that topic. See how it does. Refine it. When it’s sort-of OK, try another topic.
That line feed can be used as a delimiter between topics. You can Explode. Then reassemble and link the pieces in various ways.
1 Like
Hmm, Explode. Looks like after I prep a file (a ‘note’, I guess, in Tbx terms?) I explode it and it ‘breaks out’ the blocks I delineated. I gather it splatters these onto the screen and then I can move and group these and form new notes, reassembling as I wish, by topic?
That indeed is what I want to accomplish. What I’ve envisioned is prepping a file such that each block of text that I want is titled, dated and delineated. Then the script traverses the file, copies each delineated block (ignoring unmarked blocks) and appends them to new files, by topic. The first line of the block is the filename to append that block to). Ideally a script can do a batch of files (once they are all prepped).
Something like this is really the optimum solution, at least the best I can think of. All it requires of me is to prep each file, entering headings (filenames) and delineation. And writing a script, of course. I think this can be done in BBEdit using Apple Scripts and regex, but I’d have to master BBEdit, Apple Scripts and regex (I’m a newbie on all three). Can Tbx do something like this? Even if it requires mastering pretty much the same things to do it in Tbx it might be better there because of Tbx’s useful capabilities for such work that BBEdit does not have. Is Apple Scripts as integrated with Tbx as it is with BBEdit? Is Apple Scripts limited to activating capabilities the app has, or can it ‘intervene’ and do things with data that the app does not have in its toolbox? Is Apple Scripts even the right tool for such a task?
I much appreciate the expertise here brought to bear on this.
Is learning how to fiddle with a lot of different software, and begin learning unfamiliar tasks like coding, etc., really the best way to work with the notes? Or, is it a rabbit hole that might not satisfy – or at least delay for a long time – the objectives in your original post? Maybe just doing Spotlight searches for key terms, with a notebook in hand to record ideas about the search results, would be more satisfying?
1 Like
Thanks Paul, I will try to take these thoughts and those you gave in your earlier post to heart. What I will probably end up doing is some of two or three approaches until I see what looks like will give best results for the effort involved. I’ll probably pursue automation if it looks like I can accomplish it without too formidable a learning curve (I’ve done a bit of programming, though not enough to called a programmer). Meantime I’ll keep on journaling my thoughts every day. Ordering my past notes and seeing what to do with them is important but secondary to ongoing journaling. Been doing it most of my life and it has meant a lot to me.
Hopefully someone can say if there is a path with Tbx to accomplish the automation I’m describing.
Thanks much, I need to download Tbx to dig into this and other ideas. I don’t know what a ‘rough cut’ means in this context, and of course I know nothing of agents.
What I’ve envisioned is prepping a file such that each block of text that I want is titled, dated and delineated.
I wouldn’t do this in AppleScript, though others might.
For many cases, you can do this with Explode. Focus first on a delimiter that separates notes; Explode; and now you have lots of notes.
Second: you want to extract dates and names and other metadata.. Tinderbox actions are pretty good at that. You can always resort to AppleScript and BBEdit if you must!
I’d have to master BBEdit, AppleScript and regex
Don’t worry about AppleScript. Your task will tell you when you need AppleScript; until then, it’s not a priority.
Regex – slang for “regular expressions” – is an important concept and a useful notation. In my opinion, it’s something everyone should know. You don’t need to know everything about regular expressions, but it’s useful in Tinderbox and will be useful in lots of other places, including BBEdit.
1 Like
Thank you.
If I’m not mistaken you are the head hat here, and I appreciate you taking the time to jump in on my questions.
1 Like