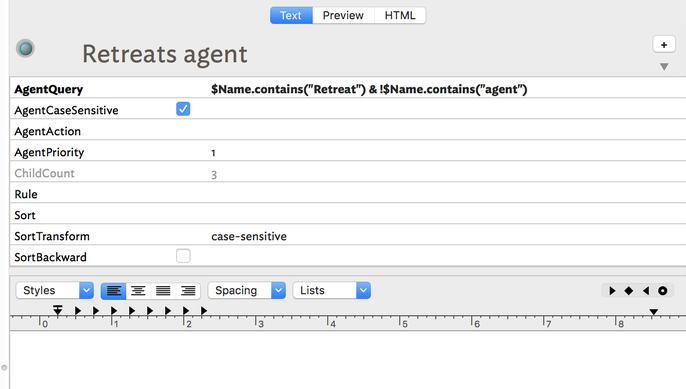
FWIW, bear in mind that in agent queries (noting that find() differs slightly):
- If an original note matches the query it it is added as an alias, trumping any aliases (manual or agent) elsewhere in the doc.
- If an alias of a note, but not its original, matches the query (e.g. due to a query term like
descendedFrom()) the first matching alias, _by outline order ($OutlineOrder) is added to the agent. If more than one such alias is a match only the first is added.
- In summary, each note is only every matched/listed once in an agent even if both the original and one-or-more aliases match the query. Thus, an original match always trumps a match to any/all aliases regardless of outline order. If alias(es) but not original matches the first alias by outline order is matched. This conforms to agents only matching each note a maximum of one time.
For historical reasons, inside() matches aliases as well as original. This allows a n agent to matching within another agent, though otherwise may result in unitised matches. In any query, add the term $IsAlias==false to ensure an alias can never be a match.
Conversely a find() returns the path of every matching instance of a note, i.e the original and every alias, where such items match the find query.
My experience is that, in structured docs (i.e. large outlines, not a single-map doc), it can be useful to:
- Place your agents that the end of the outline, unless they need to be elsewhere for structural reasons, e.g. for export purposes.
- Be aware of agents and find() queries matching aliases when you intended to match only originals.
- If using non-unique note titles ($Name), e.g. for the same structural container in different outline branches, give due consideration to starting queries with a scope-narrowing term like
descendedFrom() to ensure the rest of the query is only evaluated within that branch of the outline.
Also, I commend @doublem’s suggestions above. Work with the app rather than, as all too often occurs, simply try to force it behave like some other app with which one is more familiar. Think of Tinderbox as a toolbox rather than a single purpose app—be it GTD, QDA, zettelkasten, reference manager, timeliner, contact manager, process analysis, etc., etc. Tinderbox isn’t optimised for a single such purpose for the simple pragmatic reason that what suits one narrow purpose may not suit—and indeed, make harder—some other types of equally legitimate task.
If reading this and spinning your wheels to get started, good advice is to step back from measuring how close your experiments are to your (imagined/desired) outcome and break the process down into a series of tasks; i.e. looking in the toolbox for the appropriate tools. If that is too abstract an approach (we’re all different!), describe your task here as a new thread in the forum as your fellow users here reflect a lot of expertise both in use of the app and in different uses of it. As importantly, sometimes just describing one’s problem unambiguously to another person helps give new insight on the problem as it tends to lay bare hidden, untested, assumptions—often incorrect—as to how Tinderbox works.
 .
.