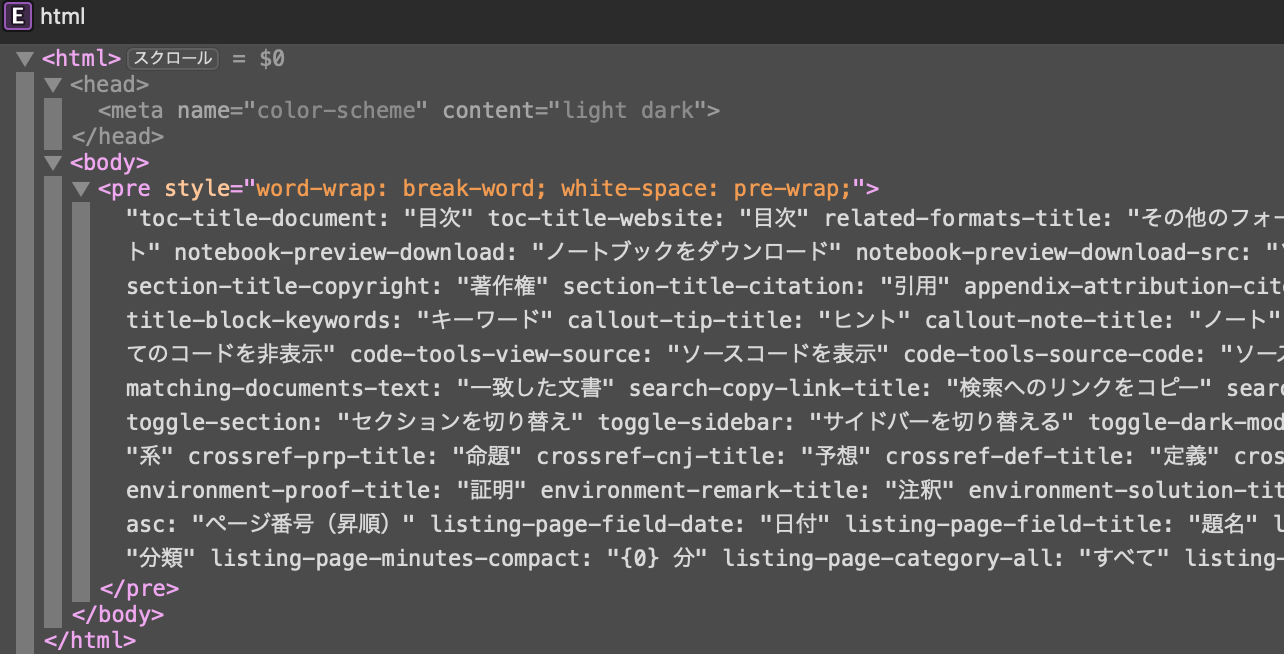
When I get a YML file containing Japanese characters from github using Autofetch, the characters are garbled. The YML file is in UTF-8 character code. Even if the file does not contain Japanese, characters with diacritical marks are garbled.
In addition to garbled characters, line breaks are also lost.
How is the character encoding handled when using Autofetch?
I can probably use runCommand to do the same thing as with Autofetch, so there is no practical problem. But it would be easier to use Autofetch if it is possible to get the file in UTF-8 format.
This is internal and not publicly documented. Thank you for offering up a test file—I can confirm I see the same effect.
I see two other oddities:
If $AutoFetch is true I believe $ReadOnly should automatically be set to true. It isn’t. I’m not sure if this is a change or glitch.
The fetched text is being inserted in a font not recognised by the OS Fonts palette. Doing a rich copy/paste to a default TextEdit document I get the font reported as ‘Times’ [sic] 12 pt. however, my system lists no such font and it appears to not be Times New Roman.
If I set $Text to use a monospace font, the AutoFetch still over-rides that.
Experimenting downloading other data formats e.g. .txt, .xml, .html I get differing results. HTML is imported using the the inline HTML & CSS styling (external CSS files are not honoured). An RSS XML feed results in the code shows in ‘code’ monospace front despite this not being the receiving note’s $TextFont.
It would appear that AutoFetch either doesn’t understand (or forgot how to) treat ‘.txt’—and unknown types such as YAML—and uses some default likely dredged from the underlying framework. Why valid UTF-8 non-roman characters are being mis-encoded, I’ve no idea.
I think this is one for @eastgate as it is ‘under the hood’ of the app where we fellow users here can’t see.
If I copy paste the autofetched $Text in Tinderbox, and paste to BBEdit, it also reports as UTF* text with LF line ends. I’m not sure where the HTML , that you show above, comes in.
If I recall, autofetch was originally added to do things like recover web pages or RSS feeds so perhaps no wonder Tinderbox understands them better.
I also downloaded it with curl and checked it with vscode and it was the same (UTF8 with LF line ends).
The screenshot is from the YML file link displayed in the Web Inspector.
(I’m sorry if I am not understanding what you wrote correctly.)
No, we’re on the same page . Clever modern web browsers have ‘HTML-ised’ the render of the YML content, given a false tell back implying HTML tags in the source content. As you note the ‘real’ content is plain UTF-8 text with no HTML tags. However, this does usefully show how sometimes, when investigating, it can be hard to have a clear sight of the real source format.
Anyway, Eastgate now know of the problem, so we don’t need to report further
The next backstage release corrects the handling of text encoding and whitespace when autofetching files that are note HTML documents. It will be available backstage shortly.
Question: the code for Autofetch has a special case for downloading files with the extension .xml . Does anyone recall the purpose for this special case?