Tinderbox Meetup Video- Saturday, July 22, 2023: A Review of Bookends–Citation and Reference Management–with Jonathan Ashwell
| Level | Intermediate |
| Published Date | 7/16/23 |
| Type | Meetup |
| Tags | 5Cs, 5Cs Learning and Knowledge Management, BibTex, Citation Management, Mendeley, Papers, Reference Management, Research, Tinderbox, Zotero |
| Video Length | 01:38:49 |
| Video URL | https://youtu.be/tKDs22mY2ZU |
| TBX Version | 9.5 |
| Instructor | Michael Becker |
In this Tinderbox Meetup, we welcomed Jonathan Ashwell, the founder and developer of Bookends at @Sonny Software.
Jonathan and the Sonny Software team have been developing Bookends and leading the field of reference and citation management since 1983 (yes, over forty years!). As a result, Bookends is one of the world’s leading citation and reference management software solutions. It is designed for casual and the most advanced scholars and professionals striving to gain mastery over the provenance and lineage of knowledge that contributes to their ideation and output. Bookends is a lot like Tinderbox, is has an incredible amount of depth.
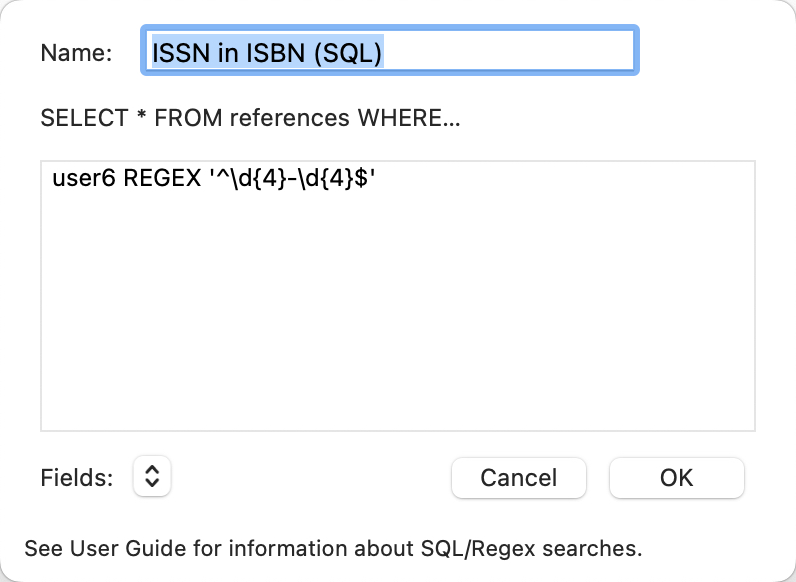
In today’s session, Johnathan kicks off his discussion with the history of citation and reference management software, which also includes solutions like BibDesk (BibTex) (2002, Senate (2004-2016), Zotero (2006~), Papers (2007~2016), and Mendely (2007~). Once he completed his history, and what brought him to the field of citation and reference management software, Jonathan dove deep into the power of Bookends. He shows us how to use field flags to granularly control the formatting and output of references in Bookends. We discuss methods and strategies for integrating Bookends in authoring workflows, including using citation keys and processing references in word processing software like Melell. In addition, some unique Bookends features that Jonathan calls out are its ability to create citation keys, integration with library databases to support search, the Bookends floating citations menu bar that allows for access to Bookends alongside any application to insert citations, the Bookends browser, and more. Jonathan also gave us a glimpse into some soon-to-be-released features, including the ability to highly and annotate PDFs and other source material. Jonathan also makes some helpful distinctions between privately developed software like Bookends vs. open-source solutions like Zotero. Specifically, he makes some helpful comparisons on breath vs. depth, quality vs. quantity, and capabilities. We also discussed how to use the best that Zotero offers with the power of Bookends through the use of Bookends watch folders.
References
The following include references introduced by the participants during the discussion and in the meeting chat.
- Summerfest 2023
- Bookends Citation Software
- Discussion Board for Bookend
- Bookends for iOS User Guide
- Pizza for Ukraine
- Artisanal Software
- Citation Style Language
- NeoVictorian 1: Civilization and its Discontents
- NeoVictorian 2: Off The Floor
- Bookends 1.0
- Mellel World Processor, great for academics an tightly integrated with Bookends, Mellel know references from bookends are not text, but rather objects.
- Using Hookmark with Bookends Reference Manager by Sonny Software
- Local LLM Model or macOS
- EagleFiler
- Book: Georges Perec, LIFE; A USER MANUAL
- John Forbes Nash and Game Theory
Please comment
Please help with the development of future sessions by answering the three questions below.
- What were your top 2~3 key takeaways from this lesson?
- What do you want to learn next? Learn more about?
- What exercises would help reinforce your learning?