Your sample materials tell us Zotero can give us the annotation info in one of three different text/data encodings. Of these, the first is the hardest to use as the link data is ‘flattened’ into the text in a manner hard to retrieve without gnarly regex. The latter two are equally useful as the two zotero:// links have transferred into Tinderbox as web links and been adopted as Tinderbox web links form the RTF $Text. Both are equally good. If you want the source text style you can use the HTML.
As there is no significant use of text styling (bold, strike, underline, etc), I’m going to use the
MD version. At this stage, I think the code to populate $ZLink and $ZDocLink will work for either MD or HTML source versions.
Whilst we could remove the URLs from the text, it’s more effort (lack of any metadata markers) and the anchor text might still be useful.
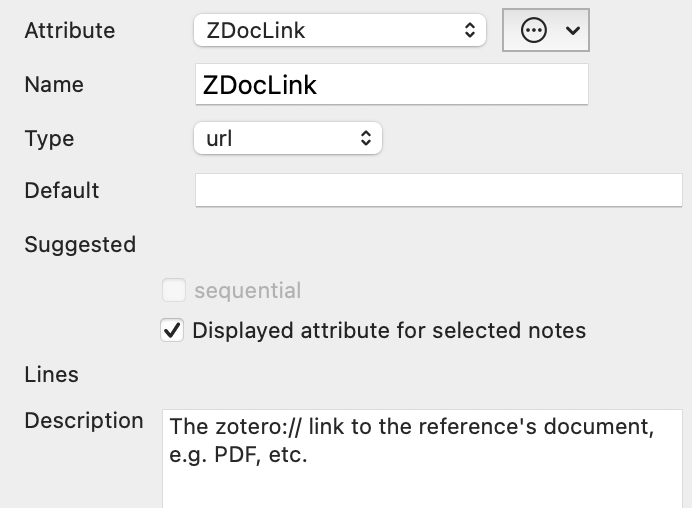
Once done, the links in $Text and the two Displayed Attributes $ZLink and $ZDocLink will point to the same target. so, the extraction may be moot. But it may be useful to others so let’s do it.
So, we have (correct) links in $Text that we wish to adopt to Tinderbox user attributes. How can action code get at that info? By using eachLink(loopVar[,scope]){actions}, we can check the note’s link(s) and look for Zotero pseudo-protocol links.
Assumption: each annotation will contain zero or one (only) links each of the two link types: the Zotero reference and the reference’s associated local source document.
I’ll wrap the logic up in a fuction, to allow for later re-use oin different contexts:
function fFindZoteroLinks(){
eachLink(aLink){
if(aLink["url"].beginsWith("zotero://select")){
$ZLink = aLink["url"];
};
if(aLink["url"].beginsWith("zotero://open-pdf")){
$ZDocLink = aLink["url"];
};
};
}; //END
And a stamp to call that:
fFindZoteroLinks();
Result:
I’ve got to head out for a meeting, but its a start. Once processed you can automate movement of the note to the ‘Zotero Annotation’ container and delete the source note. Ask if unsure on that (its been discussed in the firum so code should be there somewhere).
TBX, based on yours: Zotero annotation md vs HTML-ed1.tbx (1.3 MB)