Did you see my latest:
From an industry analysis perspective, this one is pretty cool!!!
Did you see my latest:
From an industry analysis perspective, this one is pretty cool!!!
Newbie to Tinderbox. May I seek advice if there’s a way to automate capturing Zotero annotatons links into Tinderbox URL attributes?
Context
2… I am manually copying the links to the article “ZLink” and “pdf” link attribute. Is there a pattern that can be used?
Thanks.
Could you post here a small example of, say, 5 exported annotations with links? That would save us some steps, and it’s a busy month!
About how many annotations do you want to copy to Tinderbox?
I know waht needs to be done, but I’m not a good enough coder to do it. You need to modify the Zotero RIS translate to include the annotations and annotations URL of the RIS output.
RIS isn’t complex but stopped being developed way before much modern usage. I assume Zotero has an internal map (app settings?) of RIS allowed field names and Zotero-named database fields.
Correct, RIS is NOT complex, but the Zotero JS translators are. They complex layered pieces of code that I have trouble figuring out.
Ah, I’d missed the JavaScript angle, never having used Zotero in depth. No shade there, it’s just I already use Bookends so another RM app isn’t a high priority. Yet, RM apps seem very idiosyncratic in their path to offering the user the same features. Not least, they all tend to have a different internal database engine, thus unintended hilarity ensues when trying to port methods between apps.
Thanks, Michael and Mark,
I found a work-a-round, exporting from Zotero and importing into Tinderbox a HTML annotation file with links instead. The link is now embedded in the text and I won’t need to manually key it in the attribute.
You can also use a stamp for this purpose. Here’s an example:
$Pages=$Text.extract("p\.\s*(\d+)");
$ZoteroLibraryURL=$Text.extract("zotero:\/\/select\/library\/items\/[A-Za-z0-9]+");
$ZoteroPdfAnnotationURL=$Text.extract("zotero:\/\/open-pdf\/library\/items\/[A-Za-z0-9]+\?page=\d+&annotation=[A-Za-z0-9]+");
if($Text){
$Text=$Text.extract("“([^”]+)”(?=\s*\(\[“)");
It extracts specific parts of text based on regular expressions and assigns them to attributes. Adjust the regular expressions and your User Attributes to match your use case.
Cool! Can you explain/share the work around?
Thanks. Can you explain how you are getting the Zotero details in the body of the text in the first place?
Hard to comment fully without source data but I think recent improvements in Action code, such as stream parsing, likely reduce the need to use .contains() with such complex regex (but I could be wrong).
Hi Michael,
I learnt something new while trying to demo my situation.
“Many mechanisms are involved in obesity- induced hypertension, including increased sympathetic nervous system and RAAS activity, altered production and secretion of adipokines (e.g. high leptin, reduced adiponectin), OSAS, and renal mechanisms (e.g. compression of the kidneys by visceral fat and increased renal sodium reabsorption with volume expansion)” ([“ESC 2024 supplementary_data”, p. 6] (zotero://select/library/items/B3D82XWG)) ([pdf] (zotero://open-pdf/library/items/XC6L265B?page=6&annotation=R32GBG5M))
“Many mechanisms are involved in obesity- induced hypertension, including increased sympathetic nervous system and RAAS activity, altered production and secretion of adipokines (e.g. high leptin, reduced adiponectin), OSAS, and renal mechanisms (e.g. compression of the kidneys by visceral fat and increased renal sodium reabsorption with volume expansion)” (“ESC 2024 supplementary_data”, p. 6) (pdf)
I shared the TB file with you to better demo the above. Will need to see if HTML will pose issues further down the line. I note that most users prefer md.
[/quote]
Questionable assertion, and worth noting as it leads to mis-assumptions. Fairer perhaps is that people who are used to (having to) dealing with Markdown often expect things to use Markdown as a native format.
Tinderbox can support rendering of MD in preview and for export to MD/HTML but doesn’t support it natively in the $Text area of the text pane. IOW, if you type an asterisk before/after a work the word doesn’t show in italics (and the asterisks hidden). This goes back to assumptions. Although Markdown was first launched by John Gruber in 2004, it didn’t really gain much visibility until the mid teens when it rapidly became the encoding de jour of a lot of noting type tools (especially if linked to programming communities). But even today, in the general population the majority of people haven’t heard of or deliberately use Markdown. This is important in understanding assumed default behaviours.
I’d agree the Zotero output isn’t helpful. The MD format assumes see above that all apps used for the text are MD native. As we’ve seem that assumption is flawed.
Note too, that the zotero:// links are using a a pseudo-protocol. HTML format allows such URIs but says nothing about whether they are meaningful to apps handling HTML data. Interestingly, the HTML above, pasted (Cmd+C) into a Tinderbox note text does retain the (Zotero pseudo-protocol) links but for some reason, they are not ‘adopted’ as true Tinderbox web links. I think that might be not the intended result.
So, if a starting assumption is we must use Zotero as source and Tinderbox as end point and we want to do this often enough that we don’t want manual re-editing of references in Tinderbox, I’d simply set up a better export in the Reference Manager. I use Bookends rather than Zotero, but I doubt it is much different.
For instance, if you want the first link in a user URL attribute $ZoteroURL and the second in a user URL attribute $ZoteroPDFURL, I’d edit my Zotero export template to give me:
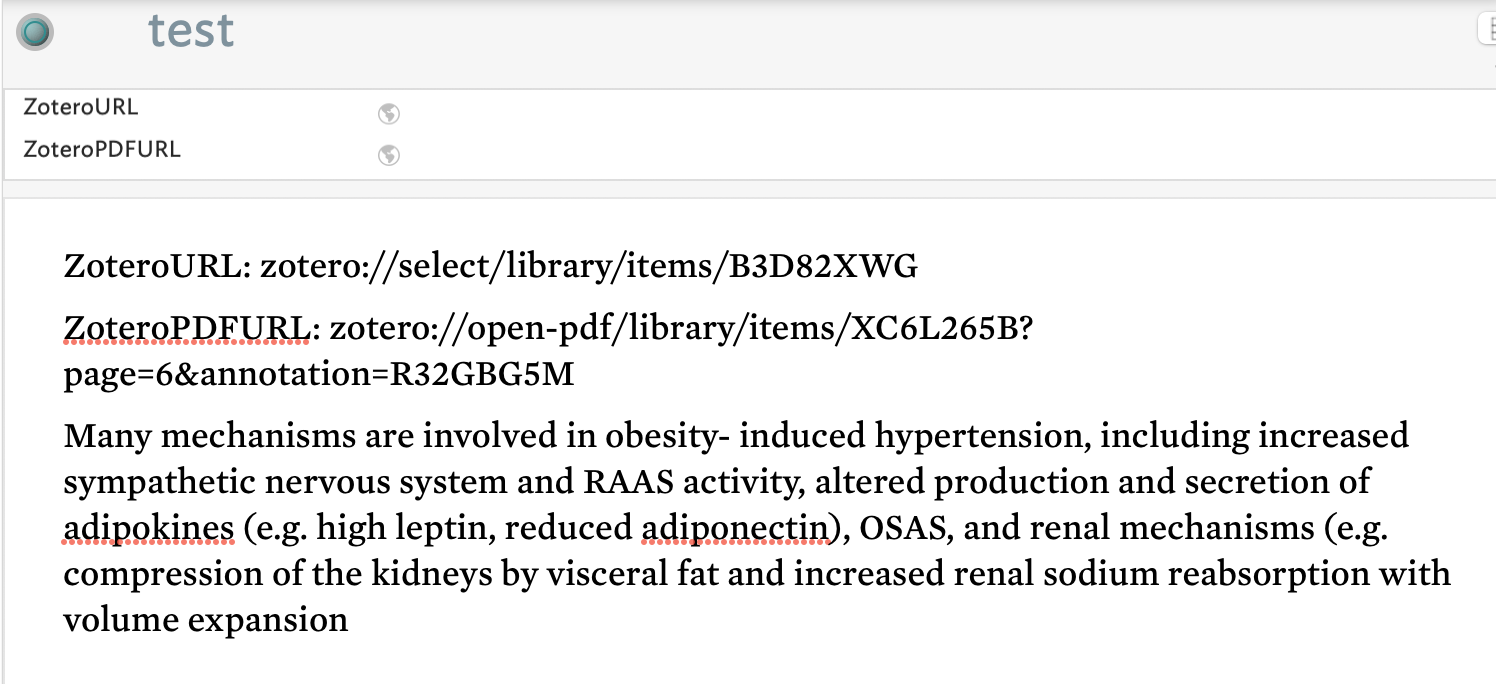
Many mechanisms are involved in obesity- induced hypertension, including increased sympathetic nervous system and RAAS activity, altered production and secretion of adipokines (e.g. high leptin, reduced adiponectin), OSAS, and renal mechanisms (e.g. compression of the kidneys by visceral fat and increased renal sodium reabsorption with volume expansion
ZoteroURL: zotero://select/library/items/B3D82XWG
ZoteroPDFURL: zotero://open-pdf/library/items/XC6L265B?page=6&annotation=R32GBG5M
or better, for simple stream parsing :
ZoteroURL: zotero://select/library/items/B3D82XWG
ZoteroPDFURL: zotero://open-pdf/library/items/XC6L265B?page=6&annotation=R32GBG5M
Many mechanisms are involved in obesity- induced hypertension, including increased sympathetic nervous system and RAAS activity, altered production and secretion of adipokines (e.g. high leptin, reduced adiponectin), OSAS, and renal mechanisms (e.g. compression of the kidneys by visceral fat and increased renal sodium reabsorption with volume expansion
Now, the parse. I’ll put the code in a function:
function fZoteroRefParse(iText:string){
iText.skipTo("ZoteroURL: ").captureLine("ZoteroURL").skipTo("ZoteroPDFURL: ").captureLine("ZoteroPDFURL").captureRest("Text");
}
We call it with a stamp:
fZoteroRefParse($Text);
We could do it all in a stamp but doubtless at some point you will want to alter this a bit.
Note before:
Note after:
Test doc: zotero-data.tbx (168.5 KB)
Now you just need to write the template for the text slug coming out of Zotero. But as I don’t use the app I’ll let someone who uses the app do that.
Sorry, I don’t see this. Can you reshare?
Sorry, I must be dense. I’m not clear on what mechanic is being used to get the zotero content in $Text. I’ve not seen “this” method before. Honestly, I think the modified translator will be the more reliable approach, I just don’t know how to do it.
I remembered I have the Zotero Mac app installed with some test records and setting the export format to RIS and draging to a Tinderbox view, Tinderbox adds the built-in ‘Reference’ prototype and I get this:
Unfortunately, the RIS ‘template’ in Zotero (as at v7.0.11) is not exposed for user editing, so your two Zotero links can’t be added.
Agree. I’ve minimal Zotero expertise. Looking at the app it’s pretty basic with no real useful customisation at app level. So you’d need a custom plug-in. From brief perusal of the docs, making a modified citation style would be a masochistic approach to the goal.
I do find it odd that the RIS exporter is not exposed to the user and simple plain text is often the safe way to go. Putting extra formatting in (HTML, Markdown, etc.) only to then strip it out seems to add scope for error).
Bookends just lets me make a new ‘format’ and design it as I want. But, as using Zotero is a starting assumption, we’re blocked.
Actually, it is exposed. This is what I mean by a Zotero translator. The JS in the translator can be modified to include the additional elements, I just don’t have enough coding skills to do it.
I’m using the Mac app. Aha, the Zotero translator isn’t in the app. It expects you be using GIT to pull repos, etc. Not my area, so I’ll pass. In truth, I think it would be easier just to use a different RM app!