If you would like to have a access to Tinderbox’s app Help files linearised into a PDF, then you can get one for v9.2.0 here.
How is this done? The HTML files used in Tinderbox’s app Help are generated from a Tinderbox. A while back, I designed an alternative export template for the document that exports all the (relevant) TBX notes as a singled, CSS-styled, HTML page. After a quick command line tweak to make Tinderbox links point within the page rather than to separate documents, I then use wkhtmltopdf to make the PDF.
This is probably one of the last times I can used this method as wkhtmltopdf is effectively moribund. It relies on re-using other code libraries that are now either themselves dead or no longer free to re-use. As it is wkhtmltopdf appears to not work on Apple Silicon—I used an old Intel Mac running macOS 10.14 to make the above.
Besides the PDF, a benefit of wkhtmltopdf is (was!) its ability to make a Table of Contents that linked to the relative headings. This does require a carefully structured HTML page—that took some extra work on the original TBX structure. It’s an interesting technique, but doesn’t suit more hypertextual work. aTbRef is a case in point: it is supposed to be explored via links and not read top to bottom.
pandoc is an interesting but very complicated tool. I think it may be able to bridge the HTML to PDF gap although I think it uses LaTeX (which might throw up a fresh crop of problem edge case issues†). Even so, I don’t think it will auto-generate a ToC. One workaround might be to make a ToC within the Help that isn’t used for in-app use but is included in the single page export. The latter includes any CSS but not images which are stored separate from, but this, the HTML page.
So is there a simple way to take a css-styled HTML page, with a well-structured DOM (i.e. properly nested headings) and in-page links, and output that as a PDF with links works, headings PDF-bookmarked and a Table of Contents added?
[Edit] For clarity, here use of Markdown is an unhelpful diversion. Markdown is an affordance to help people indicate HTML styling intent in plain text but without using HTML inline tags. But, please note our start point is a clean HTML doc so after the part of the process where Markdown might be used. So, Markdown won’t help as we’d have to go re-write the whole source TBX to use Markdown. Given we’re ‘just’ trying to make a PDF of the Help doc that’s a lot of extra free labour needed. Of course if someone will commit to maintaining a Markdown port of the Tinderbox Help TBX (not a small or one-off task) then that does open another possible avenue.
Any suggestions?
†. Dang, I tried pandoc on the HTML used to make the PDF above it does break, due to use of LaTeX by pandoc. See:
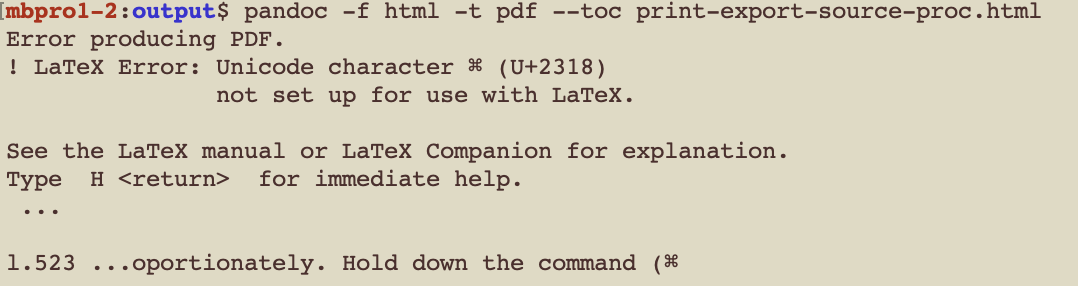

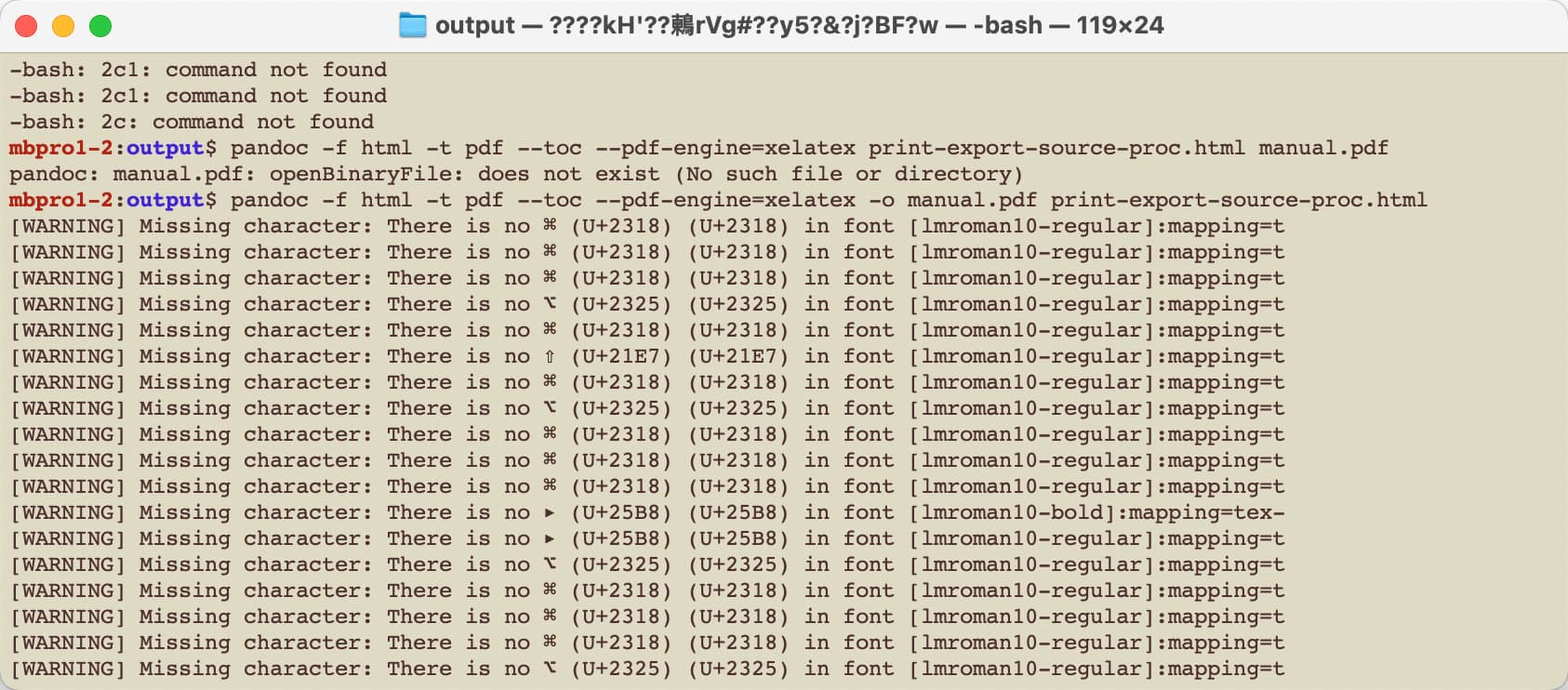




 .
.