lorem ipsum: some text I want
lorem ipsum: some text I want
lorem ipsum: some text I want
lorem ipsum: some text I want
lorem ipsum: some text I want
When I use this $Text.skipTo(':').captureLine("MyList"); I get the first line. How do I get Tinderbox to process each list and populate a list for me that contains all the text after the “:” on reach line?
The .eachLine() operator, iterates through each line of a steam, where a line is one or more characters ending in a carriage return, line feed, unicode paragraph separator, or the end of the string (so in $Text, it means discrete paragraphs).
Each line, in turn, is bound to a temporary variable LoopVar , and the action is then performed. The name of the variable is set by the user when writing the code, i.e. it is whatever string is entered where LoopVar is shown above. Something like ‘aLine’ might be a more useful variable name.
Given that I would try, and noting that :
$Text.eachLine(aLine){
$Text.skipTo(':').captureLine("MyList");
// or whatever you actually need to do per line
// ...be it one action or several
};
…but that will overwrite all of $MyList. So, perhaps:
$Text.eachLine(aLine){
$Text.skipTo(':').captureLine("MyString");
$MyList+=$MyString;
// or whatever you actually need to do per line
// ...be it one action or several
};
$MyString=;
If variables are supported you could use a var instead of $MyString.
If each line needs to go to a different place you might need extra logic to work out the per-line subject/attribute is so you know where each line of $MyList belongs.
Sorry, not sure of any good tutorials on this beyond the one for the Mars Rover data though IIRC that’s absolute parsing XML rather than text. This sort of usage is hard to guess!
OK, so the second example above didn’t work? Odd as if, for each processed line, the line is captured to $MyString and $MyString is added to $MyList then it matters not if the next iteration (i.e. line/paragraph) overwrites $MyString as it’s already being saved. What are you getting in $MyList?
Part of the issue here is we are only seeing a fraction on the context. If you’re using a test doc (i.e. no the whole project) it might give a better frame of reference if we could see it.
I think the point of $Text.skipTo(':').captureRest("MyString") is like this.
start reading $Text
find marker #1, capture rest of line to target attribute #1
(possibly consume line break at end of line
capture rest of text to a string buffer ($MyString) than now holds original $text from line #2 onwards
repeat to process one ‘line’ at a time.
side note. We clearly need to develop and share better worked examples for this. I’m light on insight as this isn’t an area of the app I’ve used and I’d assumed the folk who are using it for this would share some code.
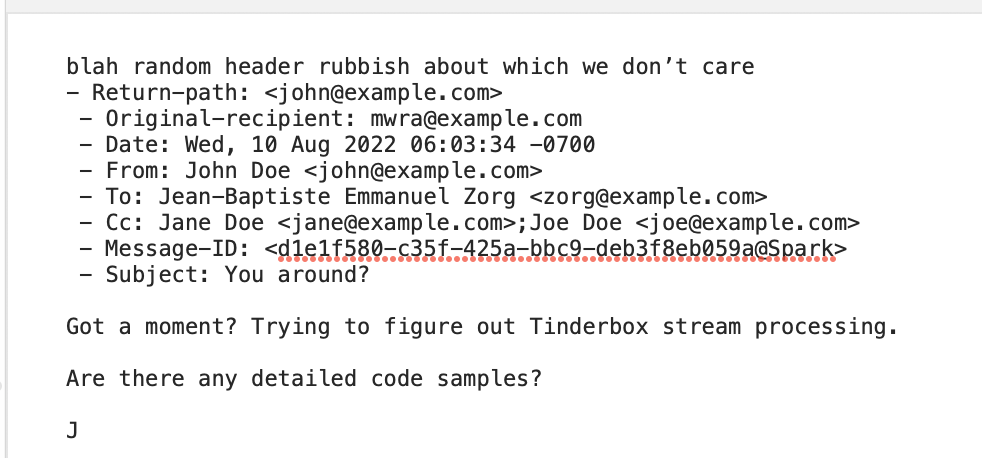
Not having a baseline example, this test doc is based on some edited raw email message data: Using-action-code.tbx (103.1 KB)updated for data glitches: stream-parse-test.tbx (87.7 KB)
Challenge make action code to take this $Text (grab from test file):
assumes sender is always a single entity (String) but recipients/copied-to may be one ora list of entitites (so a Set).
source contains data we don’t want, e.g. under-the-hood routing info) that may be in he source
target labels like 'To: may not be at the beginning of a line
target labels cannot be case-sensitive so a ‘To:’ text test must match To:, to:, TO:, tO:, etc.
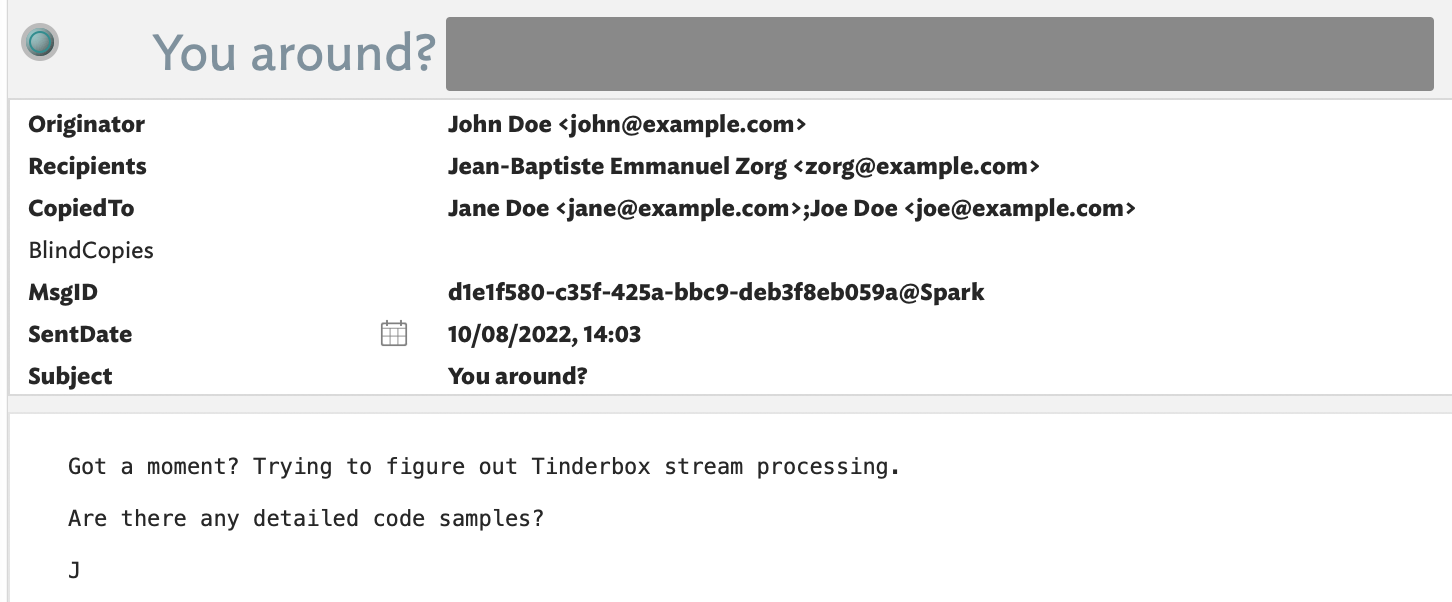
note that origination dates use the sender’s locale’s global time offset (from GMT/UTC). Tinderbox Date attribute data is time zone agnostic. In the worked example above the originators time zone (here likely somewhere in the USA) has been parsed then in Displayed Attributes only displayed in my current (UK) locale. Opening the file is India or Canada, etc. would show the example’s $SentDate as a different date time as a result.
the source challenge is not exhaustive but hopefully covers the tests parsing email source data might need (as IIRC this was the starting use case for this feature!).
Note this demo test is not exhaustive nor presumptive as being the only purpose of stream parsing. It’s purpose it to help crowd-source code examples we can re-work to help those for whom use syntax is an insufficient resource to enable use.
I can already see two different approaches depending on whether the desired embedded metadata targets, e.g. using To: to locate the string John Doe <john@example.com> and store it in $Originator—irrespective or whether that line is then deleted from $Text.
The .captureRest() approach assumes you are nibbling through structured text where the residual string (in email the body text) will form the final processed note $Text (or that of a separate ‘output’ note).
Conversely if the desired target text anchors do not occur in know sequence it becomes necessary to process each line (i.e. paragraph) for all possible occurrences using .eachLine(aLine){.... The only difficulty I see in that is that it may be hard to identify the body copy if it has no anchor/label. That might be worked around by progressively matching lines in the source and deleting them. IOW, if starting from source but outputting the residual for $MyString and for any successful test deleting that paragraph.
Now we have a common test vehicle (perhaps the TBX also needs a free-form source test model too?) perhaps we can generate some usable code for the community.
Sorry, not sure what I’m missing. Is there any action code in this file? My need was much more mundain than this.
As noted in my example, I was not looking to populate multiple attributes, but rather to parsing each link of text following an colon and then populate a list.
lorem ipsum: some text I want
lorem ipsum: some text I want
lorem ipsum: some text I want
lorem ipsum: some text I want
lorem ipsum: some text I want
I was parsing a bunch of headers and just wanted the info after the :, basically a ist of categories.
Here is a real example:
Citizens: Discover new health services, access easily
Cities: Add health services to address public needs
Companies: Helps health providers target services
Other Comapny: Gain seamless access to new services, possible future connection of health data to car
As you mentioned ‘headers’, the obvious association was parsing email headers, thus my confusion, though I think the other test case stands. Meanwhile…
OK, first some surfaced assumptions from your restated case above and addressed/allowed for in my solution:
Task runs on (all of) $Text—via a stamp (you can also use in a rule or edict once happy it works)
In this context ‘line’ and ‘paragraph’ mean the same thing.
Content to be captured is single-line.
Not all lines necessarily have labelled content - these should be ignored.
Start of line target markers are unique within $Text.
Target markers start a line and are terminated with a colon and followed immediately by a colon.
Intended targets need not occur in a consistent order.
Unmatched targets will result in that target attribute not being set.
If targets repeat, only the first by $Text occurrence order is detected/processed.
Patterns for .skipTo(pattern) are literals-or-regex so are case-sensitive unless the pattern is written as written to allow case variation.
My test $Text (likely typo in target string, and added unwanted lines, i.e. possible erroring data):
Citizens: Discover new health services, access easily
unwanted content
Cities: Add health services to address public needs
Companies: Helps health providers target services
unwanted line
Other Company: Gain seamless access to new services, possible future connection of health data to car
The pattern here (needs unique marker!) is to ‘skip to’ just before the rest of line [sic] holding the desired value. As each test (line in the stamp) reads $Text from its start the targets need no occur in order, but they do need to be unique within that $Text. If targets duplicate (e.g. ‘To:’ occurs twice) only the first one reached from the start of $Text is processed.
Just to help getting started, here is the test doc used to develop the solution:
Ugh…sorry, I’m being too obtuse. Perhaps my “real” example was one that we too bounded. Also, in my initial post I don’t recall staying “headers.” I have a variety of example. Assume I don’t have a predefined reader up to the colon, that is why my original example said, “lorem ipsum: some text I want”.
I want tinderbox to process each line and build a list of all the “some text I want” elements, there will be MANY lines that it will need to iterate trough for this to work.
This returns:
some text I want1
lorem ipsum: some text I want2
lorem ipsum: some text I want3
lorem ipsum: some text I want4
lorem ipsum: some text I want
Well, you’ve got all the data in the attributes, make the list from those values or use variables:
… and right on queue, dang, another load of work lost to the multi-doc stamp overwrite. I do hope this bug gets fixed soon or using stamps will become downright dangerous. I’m fed up of having to remember to close all open docs before using another.
As written, this solution, indeed an alternate to @eastgate’s above, has the advantage of avoiding the ‘unwanted’ $text as in the example. In addition, unless you want the extracted strings auto-sorted
The last part is a bit of a kludge. Another unexpected discovery is that whilst the original Tinderbox documentation uses the word ‘pattern’ for the argument for .skipTo(pattern), whereas to date this has implied a literal string or a regex, in the case of .skipTo() and .captureTo() these now appear to accept only string literal values, which is confusing! I’m not sure whether that is design intent or a glitch. If the former, I think the use of the descriptor ‘pattern’ is misleading.
The kludge I use to obtain ‘just’ the body copy text from the source is because I need the line after the ‘Subject:’ line but these stream tools work primarily at line scope and there is no .skipLine operator. Id there were then I could do this (this code does not work!):
Instead my shim is to capture the subject line and having done so and with that line now consumed, use .skip(N) to advance me forward (i.e. past the line end line break). Taking the rest of the stream (to the end of $Text) now works.